Self-RAG (이론)
by Cori해당 포스트는 Medium 'Florian June'이 작성한 Advanced RAG 포스트 시리즈 그 여덟번째 내용을 정리하며, Self-RAG에 대해 다루고 있다.
오픈북 시험을 보는 상황에서, 우리는 크게 두 가지 전략을 사용한다.
Method #01. 익숙한 주제에 대해서는 빠르게 답하고, 익숙하지 않은 주제에 대해서는 참고서를 열어 관련 부분을 빨리 찾아서 머릿속으로 정리한 후 시험지에 답을 쓴다.
Method #02. 모든 주제에 대해 책을 참고한다. 관련 섹션을 찾아서 머릿속으로 정리한 후 시험지에 답을 쓴다.
방법 2는 시간이 많이 소요되고 관련 없거나 잘못된 정보를 도입할 가능성이 있으며, 이는 원래 이해했던 부분에서도 혼란과 실수를 초래할 수 있다. 방법 2는 전통적인 RAG 프로세스를 예시하고, 방법 1은 self-RAG 프로세스를 나타낸다.
Overview

Self-RAG는 세 단계로 구성된다.
Step 01. 필요에 따른 검색
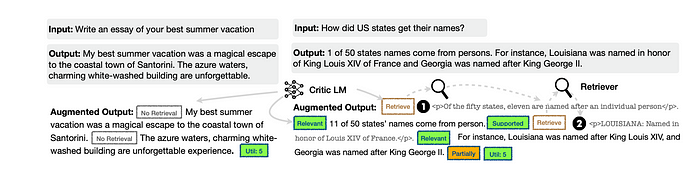
모델이 검색을 필요로 할 때, 예를 들어 "미국 주 이름은 어떻게 생겼나요?"라는 질문이 주어지면 (위 그림의 오른쪽 상단), 모델의 출력에 [Retrieve] 토큰이 포함된다. 이는 해당 질문과 관련된 내용을 검색해야 함을 나타낸다. 반대로 "당신의 최고의 여름 휴가에 대한 에세이를 작성하세요"라는 질문이 주어지면 (위 그림의 오른쪽 하단), 모델은 검색 없이 직접 답변을 생성한다.
Step 02. 병렬 생성
모델은 프롬프트와 검색된 내용을 사용하여 출력을 생성한다. 이 과정에서 세 가지 유형의 reflection 토큰이 검색된 내용의 관련성을 나타낸다.
Step 03. 평가 및 선택
Step 02에서 생성된 콘텐츠를 평가하고 최상의 부분을 출력으로 선택한다.
Reflection Tokens
RAG와 비교했을 때, self-RAG 프레임워크의 차이점은 생성 과정에서 더 정밀한 제어를 위해 반영 토큰(reflection tokens)을 사용한다는 것으로, 이는 다음 그림에서 확인할 수 있다.

self-RAG는 네 가지 명확한 판단을 한다.
- [Retrieve]: 자원 R에서 정보를 검색할지 여부를 결정하는 과정
- [IsREL]: 주어진 데이터 d가 문제 x를 해결하는 데 필요한 정보를 포함하고 있는지 여부를 판단하는 관련성 검사
- [IsSUP]: 제공된 응답 y의 진술이 데이터 d에 의해 지원되는지 확인하는 검증 과정
- [IsUSE]: 문제 x에 대한 응답 y의 유용성을 평가하는 과정 (1~5, 높을수록 유연성 커짐)
RAG에서는 조건에 상관없이 검색이 항상 초기 단계에서 고정된 과정으로 수행된다. 반면, self-RAG는 반영 토큰(reflective tokens)을 도입하여 LLM을 더욱 적응적이고 지능적으로 만든다. LLM이 텍스트를 생성하다가 불확실한 영역에 도달하면, 반영 토큰에서 멈추고, 빠르고 정확한 검색을 수행한 후, 새로 얻은 정보를 사용하여 생성을 재개한다.
Code Explanation
이 모듈의 주요 기능은 비구조화된 문서나 이미지에서 테이블 구조를 정확하게 추출하는 것이다.
추가 기능: 해당 테이블 캡션을 추출하고, 개발자가 테이블 캡션을 테이블과 연관시키기 편리하도록 하는 것이 좋다.
Env Setting
conda create -n llamaindex python=3.11
conda activate llamaindex
pip install llama-index
pip install huggingface-hub
huggingface-cli login
huggingface-cli download m4r1/selfrag_llama2_7b-GGUF selfrag_llama2_7b.q4_k_m.gguf --local-dir "YOUR_DOWNLOAD_MODEL_DIR" --local-dir-use-symlinks Falsefrom llama_index.core import Document, VectorStoreIndex
from llama_index.core.retrievers import VectorIndexRetriever
from llama_index.core.readers import SimpleDirectoryReader
from pathlib import Path
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"
# Option: download SelfRAGPack
# The first execution requires the download of SelfRAGPack.
# Subsequent executions can comment this out.
from llama_index.core.llama_pack import download_llama_pack
download_llama_pack(
"SelfRAGPack",
"./self_rag_pack")
from llama_index.packs.self_rag import SelfRAGQueryEngine
# The directory where the Llama2 model was previously downloaded and saved.
download_dir = "YOUR_DOWNLOAD_MODEL_DIR"
# Create testing documents
documents = [
Document(text="A group of penguins, known as a 'waddle' on land, shuffled across the Antarctic ice, their tuxedo-like plumage standing out against the snow."),
Document(text="Emperor penguins, the tallest of all penguin species, can dive deeper than any other bird, reaching depths of over 500 meters."),
Document(text="Penguins' black and white coloring is a form of camouflage called countershading; from above, their black back blends with the ocean depths, and from below, their white belly matches the bright surface."),
Document(text="Despite their upright stance, penguins are birds that cannot fly; their wings have evolved into flippers, making them expert swimmers."),
Document(text="The fastest species, the Gentoo penguin, can swim up to 36 kilometers per hour, using their flippers and streamlined bodies to slice through the water."),
]
index = VectorStoreIndex.from_documents(documents)
# Setup a simple retriever
retriever = VectorIndexRetriever(
index=index,
similarity_top_k=10,
)
model_path = Path(download_dir) / "selfrag_llama2_7b.q4_k_m.gguf"
query_engine = SelfRAGQueryEngine(str(model_path), retriever, verbose=True)
response = query_engine.query("Which genre the book pride and prejudice?") # No retreival example
response = query_engine.query("How tall is the smallest penguins?") # Retreival exampleclass SelfRAGQueryEngine
생성자는 주로 llama_cpp를 사용하여 Llama2–7B 모델을 로드하는 데 사용된다.
class SelfRAGQueryEngine(CustomQueryEngine):
"""Simple short form self RAG query engine."""
llm: Any = Field(default=None, description="llm")
retriever: BaseRetriever = Field(default=None, description="retriever")
generate_kwargs: Dict = Field(default=None, description="llm generation arguments")
verbose: bool = Field(default=True, description="Verbose.")
def __init__(
self,
model_path: str,
retriever: BaseRetriever,
verbose: bool = False,
model_kwargs: Dict = None,
generate_kwargs: Dict = None,
**kwargs: Any,
) -> None:
"""Init params."""
super().__init__(verbose=verbose, **kwargs)
model_kwargs = model_kwargs or _MODEL_KWARGS
self.generate_kwargs = generate_kwargs or _GENERATE_KWARGS
try:
from llama_cpp import Llama
except ImportError:
raise ImportError(_IMPORT_ERROR_MSG)
self.llm = Llama(model_path=model_path, verbose=verbose, **model_kwargs)
self.retriever = retriever
코드에서는 그림의 모든 단계가 구현된다. 하지만, LlamaIndex의 코드는 병렬 처리를 구현하지 않는다.
def custom_query(self, query_str: str) -> Response:
"""Run self-RAG."""
# Obtain responses using the Llama2 model.
response = self.llm(prompt=_format_prompt(query_str), **_GENERATE_KWARGS)
answer = response["choices"][0]["text"]
source_nodes = []
# Determine if a retrieval is necessary.
if "[Retrieval]" in answer:
if self.verbose:
print_text("Retrieval required\n", color="blue")
# The step 1 of Figure 1, retrieve as needed.
documents = self.retriever.retrieve(query_str)
if self.verbose:
print_text(f"Received: {len(documents)} documents\n", color="blue")
paragraphs = [
_format_prompt(query_str, document.node.text) for document in documents
]
if self.verbose:
print_text("Start evaluation\n", color="blue")
# Step 2 and 3 in Figure 1, generate in parallel and evaluate
# (the code does not implement parallelism)
critic_output = self._run_critic(paragraphs)
paragraphs_final_score = critic_output.paragraphs_final_score
llm_response_per_paragraph = critic_output.llm_response_per_paragraph
source_nodes = critic_output.source_nodes
if self.verbose:
print_text("End evaluation\n", color="blue")
# Select the paragraph with the highest score and return it.
best_paragraph_id = max(
paragraphs_final_score, key=paragraphs_final_score.get
)
answer = llm_response_per_paragraph[best_paragraph_id]
if self.verbose:
print_text(f"Selected the best answer: {answer}\n", color="blue")
answer = _postprocess_answer(answer)
if self.verbose:
print_text(f"Final answer: {answer}\n", color="green")
return Response(response=str(answer), source_nodes=source_nodes)How to train the Llama2–7B model
언어 모델 훈련 과정에는 2가지 모델 (비평 모델 C와 생성 모델 M)이 필요하다. 비평 모델 C는 모델 M에 필요한 감독(supervision) 데이터를 생성하며, 추론 과정에서는 모델 M만 사용되고 모델 C는 필요하지 않다.
Critic Model C
비평 모델은 reflection 토큰을 생성하도록 훈련되며, 해당 모델을 사용하는 목적은 반영 토큰을 오프라인에서 작업 출력에 삽입할 수 있게 하여 훈련 코퍼스를 업데이트하는 것이다. 각 세그먼트에 대한 reflection 토큰을 수동으로 주석 다는 것은 비용이 많이 든다. Self-RAG는 GPT-4를 활용하여 각 reflection 토큰의 고유한 지시를 할당한다.
훈련 데이터 D_critic을 얻은 후에는 다음과 같이 표준 조건부 언어 모델을 기반으로 훈련 목표를 설정할 수 있다:
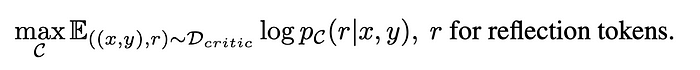
비평 모델 C는 생성 모델 (Llama2-7B 등)을 비롯한 어떤 언어 모델로도 초기화할 수 있다.
Generator model M
그림 4는 훈련 데이터를 수집하는 구체적인 과정을 보여준다. 입력-출력 쌍 (x, y)이 주어지면, self-RAG는 원래의 출력 y를 검색 및 비평 모델을 사용하여 감독 데이터를 생성한다. 각 세그먼트 yt ∈ y에 대해:
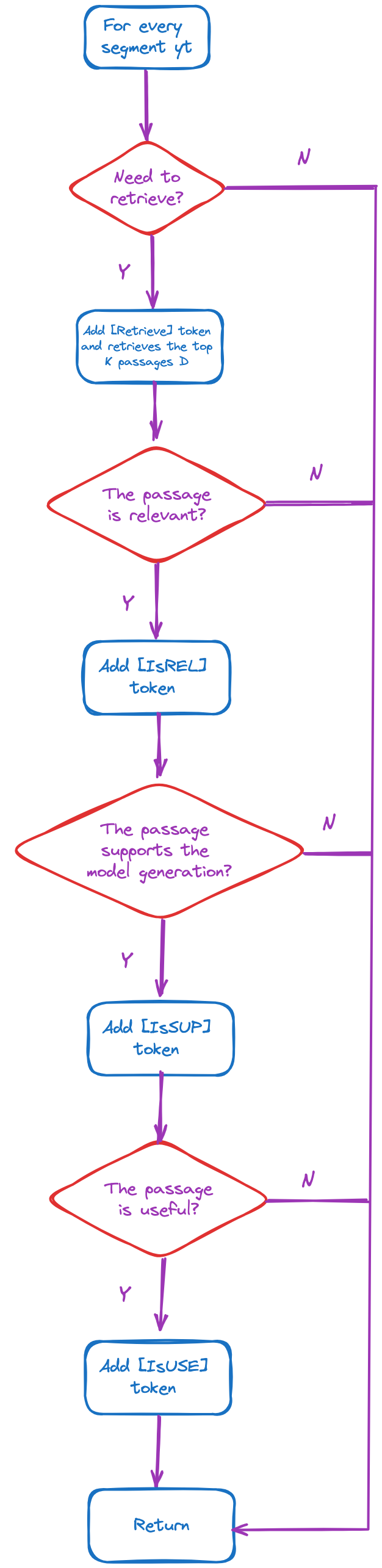
위 그림에서, 모든 조건 판단은 비평 모델 C를 통해 실행되는 것을 볼 수 있다. 획득한 훈련 데이터는 다음과 같다. 생성 모델 M의 경우, 출력뿐 아니라 반영 토큰도 예측해야 한다.
Ref.
https://medium.com/ai-advances/advanced-rag-08-self-rag-c0c5b5952e0e
'AI > Natural Language Processing' 카테고리의 다른 글
| Corrective Retrieval Augmented Generation (CRAG) (0) | 2024.06.18 |
|---|---|
| Prompt Compression (이론) (0) | 2024.06.18 |
| Exploring RAG for Tables (이론) (0) | 2024.06.14 |
| Exploring Query Rewriting (이론) (1) | 2024.06.12 |
| Exploring Semantic Chunking (이론) (0) | 2024.06.12 |
블로그의 정보
코딩하는 오리
Cori