Prompt Compression (이론)
by Cori해당 포스트는 Medium 'Florian June'이 작성한 Advanced RAG 포스트 시리즈 그 아홉번째 내용을 정리하며, RAG 성능 개선을 위해 프롬프트를 압축하는 방법에 대해 다루고 있다.
RAG 프로세스는 다음과 같은 두 가지 문제에 직면할 수 있다:
1. 대형 언어 모델(LLM)은 일반적으로 컨텍스트 길이 제한이 있어 입력 텍스트가 길어질수록 처리 시간이 오래 걸리고 비용이 증가한다.
2. 검색된 컨텍스트가 항상 유용하지 않을 수 있다. 더 큰 청크의 일부분만이 답변과 관련 있을 수 있으며, 특정 질문에 답하기 위해 여러 청크를 결합해야 할 수 있다. 이 문제는 재순위를 사용해도 여전히 존재한다.
LLM을 위한 프롬프트 압축은 이러한 문제를 해결하기 위한 방법으로, 기본적인 목표는 프롬프트에서 핵심 정보를 유지하여 입력 토큰을 더 가치 있게 만드는 것이다. 이 접근법은 모델의 성능을 향상시키고 비용을 줄여준다. 실제 작업에서는 비구조화된 데이터가 구조화된 데이터보다 훨씬 더 많다. 이러한 방대한 데이터를 파싱할 수 없다면, 그 엄청난 가치를 실현할 수 없다. 비구조화된 데이터 중에서 PDF 문서가 대부분을 차지하며, PDF 문서를 효과적으로 처리하는 것은 다른 유형의 비구조화된 문서를 관리하는 데에도 큰 도움이 될 수 있다.

보라색 점선으로 표시된 것처럼 일부 압축기는 검색된 컨텍스트에 직접 적용될 수도 있다.
프롬프트 압축 방법은 네 가지 주요 범주로 나눌 수 있다:
method #01. 정보 엔트로피 기반 방법: Selective Context, LLMLingua, LongLLMLingua와 같은 방법들이 있다. 이 방법들은 작은 언어 모델을 사용하여 원래 프롬프트의 각 토큰의 자체 정보나 당혹도(perplexity)를 계산한다. 그런 다음 당혹도가 낮은 토큰을 삭제한다.
method #02. 소프트 프롬프트 튜닝 기반 방법: AutoCompressor와 GIST와 같은 방법들이 있다. 이러한 방법들은 특정 도메인에 적합하도록 LLM 매개변수를 미세 조정해야 하지만, 블랙박스 LLM에는 직접 적용할 수 없다.
method #03. 데이터 증류 후 모델 훈련: LLMLingua-2와 RECOMP와 같은 방법들이 있다. LLM에서 데이터를 증류한 다음, 더 해석 가능한 텍스트 요약을 생성하는 모델을 훈련한다. 이러한 요약은 다양한 언어 모델 간에 전이 가능하며, 그래디언트 업데이트가 필요 없는 블랙박스 LLM에 적용될 수 있다.
method #04. 토큰 병합 또는 토큰 가지치기 기반 방법: ToMe와 AdapLeR와 같은 방법들이 있다. 이러한 방법들은 보통 모델 미세 조정이나 추론 과정 중간 결과 생성을 요구한다.
Selective Context
다음 그림은 LLM이 전체 컨텍스트나 완전한 대화 기록 없이도 사용자 쿼리에 응답할 수 있음을 보여준다. 관련 정보가 생략되더라도 LLM은 예상된 응답을 생성할 수 있으며, 이는 LLM이 문맥 단서와 사전 훈련 중 얻은 사전 지식을 통해 누락된 정보를 추론할 수 있을 것으로 생각된다.

성능을 저하시키지 않으면서 덜 유익한 콘텐츠를 필터링하여 컨텍스트 길이를 최적화할 수 있으며, 이것이 선택적 컨텍스트(Selective Context)의 핵심 통찰이다. 선택적 컨텍스트는 작은 언어 모델(SLM)을 사용하여 주어진 컨텍스트에서 문장, 구 또는 토큰과 같은 어휘 단위의 자체 정보를 결정한다. 획득한 자체 정보를 사용하여 그것들의 정보성을 평가하며, 정보성이 높은 콘텐츠를 선택적으로 유지함으로써 선택적 컨텍스트는 LLM을 위한 더 간결하고 효율적인 컨텍스트 표현을 제공한다.
Self Information
선택적 컨텍스트(Selective Context)는 자체 정보를 사용하여 콘텐츠의 품질을 평가한다. 자체 정보(Self-information)는 놀라움(surprisal) 또는 정보 콘텐츠(information content)라고도 불리며, 정보 이론에서 중요한 개념이다. 이는 사건이 전달하는 정보의 양을 정량화하며, 토큰의 음의 로그 우도로 정의된다:

수식에서 I(x)는 토큰 x의 자체 정보를 나타내며, P(x)는 그 출력 확률을 나타낸다.
정보 이론에서 자체 정보는 사건과 관련된 놀라움 또는 불확실성의 정도를 정량화힌다. 더 많은 정보를 전달하는 희귀한 사건은 더 높은 자체 정보를 갖고, 반대로, 더 적은 정보를 전달하는 일반적인 사건은 더 낮은 자체 정보를 갖는다.
Env Setting
conda create -n "selective_context" python=3.10
conda activate selective_context
pip install selective-context
python -m spacy download en_core_web_sm잘 설정되었는지는 다음과 같이 확인할 수 있다.
from selective_context import SelectiveContext
sc = SelectiveContext(model_type='gpt2', lang='en')
text = "INTRODUCTION Continual Learning ( CL ) , also known as Lifelong Learning , is a promising learning paradigm to design models that have to learn how to perform multiple tasks across different environments over their lifetime [To uniform the language and enhance the readability of the paper we adopt the unique term continual learning ( CL ) .]. Ideal CL models in the real world should be deal with domain shifts , researchers have recently started to sample tasks from two different datasets . For instance , proposed to train and evaluate a model on Imagenet first and then challenge its performance on the Places365 dataset . considers more scenarios , starting with Imagenet or Places365 , and then moving on to the VOC/CUB/Scenes datasets. Few works propose more advanced scenarios built on top of more than two datasets."
context, reduced_content = sc(text)
# We can also adjust the reduce ratio
# context_ratio, reduced_content_ratio = sc(text, reduce_ratio = 0.5)Selective Context 함수를 구현해보자.
class SelectiveContext:
...
...
def __call__(self, text: str, reduce_ratio: float = 0.35, reduce_level :str = 'phrase') -> List[str]:
context = self.beautify_context(text)
self.mask_ratio = reduce_ratio
sents = [sent.strip() for sent in re.split(self.sent_tokenize_pattern, context) if sent.strip()]
# You want the reduce happen at sentence level, phrase level, or token level?
assert reduce_level in ['sent', 'phrase', 'token'], f"reduce_level should be one of ['sent', 'phrase', 'token'], got {reduce_level}"
sent_lus, phrase_lus, token_lus = self._lexical_unit(sents)
lexical_level = {
'sent': sent_lus,
'phrase': phrase_lus,
'token': token_lus
}
# context is the reduced context, masked_sents denotes what context has been filtered out
context, masked_sents = self.self_info_mask(lexical_level[reduce_level].text, lexical_level[reduce_level].self_info, reduce_level)
return context, masked_sents해당 코드는 크게 3가지 단계로 구성된다.
Step 1. 문맥 내 각 토큰의 자체 정보 계산
문맥 C = x0, x1, …, xn이 주어졌을 때, 여기서 각 xi는 토큰을 나타낸다. 인과 언어 모델(GPT-2, OPT, LLaMA 등)을 사용하여 각 토큰 xi의 자체 정보를 계산한다:

class SelectiveContext:
...
...
def _get_self_info_via_gpt2(self, text: str) -> Tuple[List[str], List[float]]:
if self.lang == 'en':
text = f"<|endoftext|>{text}"
elif self.lang == 'zh':
text = f"[CLS]{text}"
with torch.no_grad():
encoding = self.tokenizer(text, add_special_tokens=False, return_tensors='pt')
encoding = encoding.to(self.device)
outputs = self.model(**encoding)
logits = outputs.logits
probs = torch.softmax(logits, dim=-1)
self_info = -torch.log(probs)
input_ids = encoding['input_ids']
input_ids_expaned = input_ids[:, 1:].unsqueeze(-1)Step 2. 어휘 단위 병합
토큰 수준에서 선택적 컨텍스트 필터링을 수행하면 일관성 없는 컨텍스트가 될 수 있다. 예를 들어, 원래 프롬프트의 "2009"가 "209"로 압축될 수 있다. 따라서 토큰 수준 필터링 외에도 구와 문장 수준에서 필터링 절차를 구현하는 것이 중요한데, 필터링의 기본 단위인 어휘 단위는 토큰, 구 또는 문장이 될 수 있다. 각 어휘 단위 u = (xt, …, xt+α)의 자체 정보를 계산하는 방법은, 자체 정보의 가법성 원칙에 따라 u를 구성하는 각 토큰의 자체 정보를 더하면 된다:

class SelectiveContext:
...
...
def _lexical_unit(self, sents):
if self.sent_level_self_info:
sent_self_info = []
all_noun_phrases = []
all_noun_phrases_info = []
all_tokens = []
all_token_self_info = []
for sent in sents:
# print(sent)
tokens, self_info = self.get_self_information(sent)
'''
ipdb> sent
'INTRODUCTION Continual Learning ( CL ) , also known as Lifelong Learning , is a promising learning paradigm to design models that have to learn how to perform multiple tasks across different environments over their lifetime [To uniform the language and enhance the readability of the paper we adopt the unique term continual learning ( CL ) .].'
ipdb> tokens
['IN', 'TR', 'ODUCT', 'ION', ' Contin', 'ual', ' Learning', ' (', ' CL', ' )', ',', ' also', ' known', ' as', ' Lif', 'elong', ' Learning', ',', ' is', ' a', ' promising', ' learning', ' paradigm', ' to', ' design', ' models', ' that', ' have', ' to', ' learn', ' how', ' to', ' perform', ' multiple', ' tasks', ' across', ' different', ' environments', ' over', ' their', ' lifetime', ' [', 'To', ' uniform', ' the', ' language', ' and', ' enhance', ' the', ' read', 'ability', ' of', ' the', ' paper', ' we', ' adopt', ' the', ' unique', ' term', ' continual', ' learning', ' (', ' CL', ' )', '.', '].']
ipdb> self_info
[7.514791011810303, 1.632637619972229, 0.024813441559672356, 0.006853647995740175, 12.09920597076416, 2.1144468784332275, 9.457701683044434, 2.4503376483917236, 10.236454963684082, 0.8689146041870117, 5.269547939300537, 4.641763210296631, 0.22138957679271698, 0.010370315983891487, 10.071824073791504, 0.6905602216720581, 0.01698811538517475, 1.5882389545440674, 0.4495090842247009, 0.45371606945991516, 6.932497978210449, 6.087430477142334, 3.66465425491333, 3.3969509601593018, 7.337691307067871, 5.881226539611816, 1.7340556383132935, 4.599822521209717, 6.482723236083984, 4.045308589935303, 4.762691497802734, 0.21346867084503174, 3.7985599040985107, 4.6389899253845215, 0.33642446994781494, 4.918881416320801, 2.076707601547241, 3.3553669452667236, 5.5081071853637695, 5.625778675079346, 0.7966060638427734, 6.347291946411133, 12.772034645080566, 13.792041778564453, 4.11267614364624, 6.583715915679932, 3.3618998527526855, 8.434362411499023, 1.2423189878463745, 5.8330583572387695, 0.0013973338063806295, 0.3090735077857971, 1.1139129400253296, 4.160390853881836, 3.744772434234619, 7.2841596603393555, 1.4088190793991089, 7.86871337890625, 4.305004596710205, 9.69282341003418, 0.08665203303098679, 1.6127821207046509, 1.6296097040176392, 0.46206924319267273, 3.0398476123809814, 6.892032623291016]
'''
sent_self_info.append(np.mean(self_info))
all_tokens.extend(tokens)
all_token_self_info.extend(self_info)
noun_phrases, noun_phrases_info = self._calculate_lexical_unit(tokens, self_info)
'''
ipdb> noun_phrases
['INTRODUCTION Continual Learning', ' (', ' CL', ' )', ',', ' also', ' known', ' as', ' Lifelong Learning', ',', ' is', ' a promising learning paradigm', ' to', ' design', ' models', ' that', ' have', ' to', ' learn', ' how', ' to', ' perform', ' multiple tasks', ' across', ' different environments', ' over', ' their lifetime', ' [', 'To', ' uniform', ' the language', ' and', ' enhance', ' the readability', ' of', ' the paper', ' we', ' adopt', ' the unique term continual learning', ' (', ' CL', ' )', '.', ']', '.']
ipdb> noun_phrases_info
[4.692921464797109, 2.4503376483917236, 10.236454963684082, 0.8689146041870117, 5.269547939300537, 4.641763210296631, 0.22138957679271698, 0.010370315983891487, 3.5931241369495788, 1.5882389545440674, 0.4495090842247009, 4.284574694931507, 3.3969509601593018, 7.337691307067871, 5.881226539611816, 1.7340556383132935, 4.599822521209717, 6.482723236083984, 4.045308589935303, 4.762691497802734, 0.21346867084503174, 3.7985599040985107, 2.487707197666168, 4.918881416320801, 2.7160372734069824, 5.5081071853637695, 3.2111923694610596, 6.347291946411133, 12.772034645080566, 13.792041778564453, 5.348196029663086, 3.3618998527526855, 8.434362411499023, 2.3589248929638416, 0.3090735077857971, 2.6371518969535828, 3.744772434234619, 7.2841596603393555, 4.672402499616146, 1.6127821207046509, 1.6296097040176392, 0.46206924319267273, 3.0398476123809814, 3.446016311645508, 3.446016311645508]
'''
# We need to add a space before the first noun phrase for every sentence except the first one
if all_noun_phrases:
noun_phrases[0] = f" {noun_phrases[0]}"
all_noun_phrases.extend(noun_phrases)
all_noun_phrases_info.extend(noun_phrases_info)
return [
LexicalUnits('sent', text=sents, self_info=sent_self_info),
LexicalUnits('phrase', text=all_noun_phrases, self_info=all_noun_phrases_info),
LexicalUnits('token', text=all_tokens, self_info=all_token_self_info)
]Step 3. 정보성이 있는 컨텍스트의 선택적 유지
각 어휘 단위의 자체 정보가 계산된 후에는 어떻게 그것들의 정보성을 평가할 수 있을까가 해결해야 할 문제다. 해당 논문에서는 가장 정보성 있는 콘텐츠를 선택하기 위해 백분위 기반 필터링 접근 방식을 사용하는 적응형 방법을 제안한다. 이는 고정된 임계값을 사용하거나 상위 k개의 어휘 단위를 유지하는 것보다 더 바람직하며, 먼저, 자체 정보 값을 기준으로 어휘 단위를 내림차순으로 정렬한다. 그런 다음, 모든 어휘 단위에 대해 이 값들의 p-번째 백분위를 계산한다. 그 후, 자체 정보 값이 p-번째 백분위 이상인 어휘 단위를 선택적으로 유지한다.
class SelectiveContext:
...
...
def self_info_mask(self, sents: List[str], self_info: List[float], mask_level):
# mask_level: mask sentences, phrases, or tokens
sents_after_mask = []
masked_sents = []
self.ppl_threshold = np.nanpercentile(self_info, self.mask_ratio * 100)
# if title is not None:
# with open(os.path.join(self.path, title+'_prob_token.tsv'), 'w', encoding='utf-8') as f:
# for token, info in zip(tokens, self_info):
# f.write(f"{token}\t{info}\n")
# with open(os.path.join(self.path, title+'_prob_sent.tsv'), 'w', encoding='utf-8') as f:
# for sent, info in zip(sents, sent_self_info):
# f.write(f"{sent}\n{info}\n\n")
for sent, info in zip(sents, self_info):
if info < self.ppl_threshold:
masked_sents.append(sent)
sents_after_mask.append(self.mask_a_sent(sent, mask_level))
else:
sents_after_mask.append(sent)
masked_context = " ".join(sents_after_mask) if mask_level == 'sent' else "".join(sents_after_mask)
return masked_context, masked_sents
LLMLingua
LLMLingua는 Selective Context가 압축된 내용 간의 상호 연관성과 프롬프트 압축에 사용된 작은 언어 모델과 LLM 간의 상관관계를 무시하는 경향이 있음을 지적한다. LLMLingua는 이러한 문제를 정확히 해결하는데, 구체적으로, 다음 그림에 나타난 것처럼, LLMLingua는 예산 조절기를 사용하여 원래 프롬프트의 다양한 구성 요소(예: 지침, 데모, 질문)에 동적으로 다른 압축 비율을 할당한다. 또한, LLMLingua는 높은 압축 비율에서도 의미적 무결성을 유지하기 위해 데모 수준의 거친 압축을 수행한다. 추가로, LLMLingua는 세밀한 프롬프트 압축을 위한 토큰 수준의 반복 알고리즘을 도입한다.

Selective Context와 비교하여, LLMLingua는 토큰 간의 조건부 의존성을 고려하면서 프롬프트의 핵심 정보를 더 효과적으로 유지할 수 있으며, 프롬프트를 대략 20배로 압축할 수 있다.
Budget controller
Budget controller는 LLMLingua의 주요 구성 요소로, 기존 프롬프트의 다양한 부분에 동적으로 다른 압축 비율을 할당하는 데 사용된다. 프롬프트의 다른 섹션은 압축에 대한 민감도가 다르다. 예를 들어, 지침(instruction)과 질문(question)은 더 민감한 반면, 설명(demonstrations)은 덜 민감하다. Budget controller의 역할은 지침과 질문에 더 낮은 압축 비율을 할당하여 필수 정보를 보존하는 것이다. 반면, 중복 정보를 제거하기 위해 설명에는 더 높은 압축 비율을 할당할 수 있다.

위 수식에서, 주요 변수는 다음과 같다.
M𝑠: GPT-2 또는 LLaMA와 같은 작은 언어 모델
x = (x^ins, x^dems, x^que): 지침, 데모, 질문을 포함하는 원래 프롬프트
𝐿, 𝐿_ins, 𝐿_dems, 𝐿_que는 각각 x, x^ins, x^dems, x^que의 토큰 수
𝜏_dems: 전체 목표 압축 비율 𝜏 및 지침과 질문에 대한 사전 정의된 압축 비율인 𝜏_ins 및 𝜏_que에 따른 데모의 압축 비율 D: 압축된 데모를 포함할 집합
Budget Controller 주요 작동 과정은 다음과 같다.
Step 1. 설명의 압축 비율 계산
Step 2. GPT-2 또는 LLaMA와 같은 작은 언어 모델을 사용하여 원래 설명 집합의 각 설명의 perplexity 계산
Step 3. 모든 설명을 당혹도 기준으로 내림차순으로 정렬
Step 4. 반복적으로 설명을 선택하고 집합 D에 추가
Step 5. 설명을 압축한 후 남은 예산을 지침과 질문에 할당
Step 6. 거친 압축 후 집합 D 출력
설명 수준의 과정(demonstration-level process)을 통해 예산 조절기는 압축 중에 핵심 정보를 유지하면서 원래 프롬프트의 크기를 효과적으로 줄일 수 있다. 이 방법은 여러 설명을 포함하는 프롬프트에 특히 적합하며, 관련 코드는 LLMLingua github control_context_budget 함수에 있다.
Iterative Token-level Prompt Compression (ITPC)
당혹도를 사용한 프롬프트 압축에는 고유한 한계가 있는데, 바로 독립성 가정이다. 이 가정은 프롬프트의 각 토큰을 독립적으로 본다(토큰의 발생 확률은 이전 토큰에만 의존하며 다른 토큰과는 관련이 없다고 가정한다). 이 가정의 문제는 자연어에서 종종 존재하는 토큰 간의 복잡한 의존성을 간과하는 것인데, 이러한 의존성은 문맥을 이해하고 의미적 무결성을 유지하는 데 필수적이다.
이러한 간과는 압축 과정에서 중요한 정보의 손실로 이어질 수 있는데, 높은 비율의 압축에서 특정 토큰이 문맥 내에서 중요한 추론 단계나 논리적 연결을 제공하는 경우, 단순히 그 토큰의 당혹도만을 기준으로 유지 여부를 결정하면 불완전한 추론 과정이 될 수 있다. 문제 해결을 하기 위해 LLMLingua는 반복적 토큰 수준 프롬프트 압축(ITPC) 알고리즘을 도입했다. 이 방법은 독립 확률에만 의존하는 대신, 프롬프트 압축 동안 각 토큰의 중요성을 더 정확하게 평가한다. 이를 위해 프롬프트의 각 부분을 반복적으로 처리하고 현재 문맥 내에서 각 토큰의 조건부 확률을 고려한다. 이 접근법은 토큰 간의 의존성을 더 잘 유지하는 데 도움을 주며, ITPC 상세 단계는 다음 그림과 같다. 이 과정을 통해 ITPC 알고리즘은 프롬프트의 의미적 무결성을 유지하면서 프롬프트 길이를 효과적으로 압축하여 LLM의 추론 비용을 줄일 수 있다. 관련 코드는 github iterative_compress_prompt 함수에 있다.

Instruction Tuning
명령어 튜닝은 LLMLingua에서 중요한 단계인데, 그 목적은 프롬프트 압축에 사용되는 작은 언어 모델과 LLM 간의 분포 차이를 최소화하는 것이다. 명령어 튜닝은 다음과 같이 이루어진다.

Code
Env Setting
conda create -n "llmlingua" python=3.11
conda activate llmlingua
pip install llmlinguafrom llmlingua import PromptCompressor
GSM8K_PROMPT = "Question: Angelo and Melanie want to plan how many hours over the next week they should study together for their test next week. They have 2 chapters of their textbook to study and 4 worksheets to memorize. They figure out that they should dedicate 3 hours to each chapter of their textbook and 1.5 hours for each worksheet. If they plan to study no more than 4 hours each day, how many days should they plan to study total over the next week if they take a 10-minute break every hour, include 3 10-minute snack breaks each day, and 30 minutes for lunch each day?\nLet's think step by step\nAngelo and Melanie think they should dedicate 3 hours to each of the 2 chapters, 3 hours x 2 chapters = 6 hours total.\nFor the worksheets they plan to dedicate 1.5 hours for each worksheet, 1.5 hours x 4 worksheets = 6 hours total.\nAngelo and Melanie need to start with planning 12 hours to study, at 4 hours a day, 12 / 4 = 3 days.\nHowever, they need to include time for breaks and lunch. Every hour they want to include a 10-minute break, so 12 total hours x 10 minutes = 120 extra minutes for breaks.\nThey also want to include 3 10-minute snack breaks, 3 x 10 minutes = 30 minutes.\nAnd they want to include 30 minutes for lunch each day, so 120 minutes for breaks + 30 minutes for snack breaks + 30 minutes for lunch = 180 minutes, or 180 / 60 minutes per hour = 3 extra hours.\nSo Angelo and Melanie want to plan 12 hours to study + 3 hours of breaks = 15 hours total.\nThey want to study no more than 4 hours each day, 15 hours / 4 hours each day = 3.75\nThey will need to plan to study 4 days to allow for all the time they need.\nThe answer is 4\n\nQuestion: You can buy 4 apples or 1 watermelon for the same price. You bought 36 fruits evenly split between oranges, apples and watermelons, and the price of 1 orange is $0.50. How much does 1 apple cost if your total bill was $66?\nLet's think step by step\nIf 36 fruits were evenly split between 3 types of fruits, then I bought 36/3 = 12 units of each fruit\nIf 1 orange costs $0.50 then 12 oranges will cost $0.50 * 12 = $6\nIf my total bill was $66 and I spent $6 on oranges then I spent $66 - $6 = $60 on the other 2 fruit types.\nAssuming the price of watermelon is W, and knowing that you can buy 4 apples for the same price and that the price of one apple is A, then 1W=4A\nIf we know we bought 12 watermelons and 12 apples for $60, then we know that $60 = 12W + 12A\nKnowing that 1W=4A, then we can convert the above to $60 = 12(4A) + 12A\n$60 = 48A + 12A\n$60 = 60A\nThen we know the price of one apple (A) is $60/60= $1\nThe answer is 1\n\nQuestion: Susy goes to a large school with 800 students, while Sarah goes to a smaller school with only 300 students. At the start of the school year, Susy had 100 social media followers. She gained 40 new followers in the first week of the school year, half that in the second week, and half of that in the third week. Sarah only had 50 social media followers at the start of the year, but she gained 90 new followers the first week, a third of that in the second week, and a third of that in the third week. After three weeks, how many social media followers did the girl with the most total followers have?\nLet's think step by step\nAfter one week, Susy has 100+40 = 140 followers.\nIn the second week, Susy gains 40/2 = 20 new followers.\nIn the third week, Susy gains 20/2 = 10 new followers.\nIn total, Susy finishes the three weeks with 140+20+10 = 170 total followers.\nAfter one week, Sarah has 50+90 = 140 followers.\nAfter the second week, Sarah gains 90/3 = 30 followers.\nAfter the third week, Sarah gains 30/3 = 10 followers.\nSo, Sarah finishes the three weeks with 140+30+10 = 180 total followers.\nThus, Sarah is the girl with the most total followers with a total of 180.\nThe answer is 180"
llm_lingua = PromptCompressor()
# llm_lingua = PromptCompressor("microsoft/phi-2") ## Or use the phi-2 model,
## Or use the quantation model, like TheBloke/Llama-2-7b-Chat-GPTQ, only need <8GB GPU memory.
## Before that, you need to pip install optimum auto-gptq
# llm_lingua = PromptCompressor("TheBloke/Llama-2-7b-Chat-GPTQ", model_config={"revision": "main"})
compressed_prompt = llm_lingua.compress_prompt(GSM8K_PROMPT.split("\n\n")[0], instruction="", question="", target_token=200)
print('-' * 100)
print("original:")
print(GSM8K_PROMPT.split("\n\n")[0])
print('-' * 100)
print("compressed_prompt:")
print(compressed_prompt)기본 모델은 처음 실행할 때 다운로드되며, 양자화된 모델을 사용할 수도 있습니다. 실행 결과는 다음과 같다.

LongLLMLingua
LLMLingua의 문제는 압축 과정에서 사용자 질문을 고려하지 않아 관련 없는 정보를 유지할 수 있다는 점이다. LongLLMLingua는 압축 과정에 사용자 질문을 포함시켜 이 문제를 해결한다.

LongLLMLingua는 LLM에서 핵심 정보를 인식하는 능력을 향상시키기 위해 네 가지 새로운 구성 요소를 제안한다:
Component # 01. 질문 인식 거친 압축 및 세밀한 압축
Component # 02. 문서 재정렬 매커니즘
Component # 03. 동적 압축 비율
Component # 04. 하위 시퀀스 복구 알고리즘
Question-aware coarse-grained compression
LongLLMLingua는 다양한 문맥 x^doc_k에 조건화된 질문 x^que의 당혹도를 사용하여 그것들의 연관성을 나타내는 방법을 제안한다. 제한 문구인 "이 질문에 대한 답을 주어진 문서에서 찾을 수 있습니다"를 x^que 뒤에 추가할 수 있다. 이 문구는 x^que와 x^doc_k 간의 연결을 강화하고 환각 효과를 줄이는 정규화 항목으로 작용하며, 다음과 같이 표현될 수 있다:

x^que로 조건화되더라도, 전체 문서에 대해 계산된 당혹도 점수가 충분히 뚜렷하지 않을 수 있으며, 이는 문서 수준의 압축에 대한 부적절한 측정치가 된다. 관련 코드는 github get_distance_longllmlingua 함수에서 찾을 수 있다.
Question-aware fine-grained compression
LongLLMLingua는 대비 당혹도(contrastive perplexity) 개념을 도입한다.
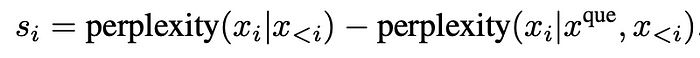
Step 01. 질문을 고려하지 않고 토큰의 당혹도를 계산한다 (perplexity(x_i | x < i))
Step 02. 질문을 포함하여 다시 당혹도를 측정한다 (perplexity(x_i | x^que, x < i)), 질문 x^que가 주어졌을 때 토큰 x_i 이전의 모든 토큰을 보는 놀라움 측정
목표는 질문과 관련하여 각 토큰의 놀라움 수준이 얼마나 변하는지를 결정하는 것으로, 질문이 포함되었을 때 단어가 덜 놀랍다면, 이는 그 단어가 질문과 매우 관련이 있을 수 있음을 나타낸다.
Document reordering mechanism
추론 과정에서 LLM은 프롬프트의 시작과 끝 부분의 콘텐츠를 사용하는 경향이 있으며, 중간 부분의 콘텐츠는 무시한다. 이 문제는 "중간에서 잃어버림(Lost in the Middle)" 문제로 알려져 있다.

관련 정보가 처음에 배치되었을 때 LLM이 가장 잘 수행되는 것을 볼 수 있다. 이에 LongLLMLingua는 거친 압축 결과를 바탕으로 문단을 정리하여, 점수가 높은 순서대로 앞에서 뒤로 배치한다.

Dynamic compression ratio
문서마다 중요한 정보의 밀도가 다르기 때문에 질문과 더 관련성이 높은 문서에 더 많은 예산(즉, 더 낮은 압축 비율)을 할당해야 한다. LongLLMLingua는 거친 압축에서의 중요도 점수를 사용하여 fine-grained 압축 과정 동안 예산 할당을 안내한다. 구체적으로, LLMLingua의 budget controller를 사용하여 유지할 문서에 대한 초기 예산을 설정하는 것부터 시작한다. 이후 세밀한 압축 단계에서 각 문서에 압축 예산을 동적으로 할당하며, 이는 거친 압축 단계에서 결정된 문서의 중요도 점수 순위에 기반한다. LongLLMLingua는 적응형 할당을 위해 선형 스케줄러를 사용하며, 각 토큰 xi의 예산은 다음과 같이 공식화될 수 있다:

Nd는 문서의 수를 나타내며, 는 동적 할당을 위한 전체 예산을 제어하는 하이퍼파라미터이다. 관련 코드는 github get_dynamic_compression_ratio 함수에서 찾을 수 있다.
Subsequence recovery algorithm
fine-grained 토큰 단위 압축 과정에서 주요 엔티티의 일부 토큰이 제거될 수 있다. 예를 들어, 원래 프롬프트의 "2009"가 "209"로 압축될 수 있고, "Wilhelm Conrad Rontgen"이 "Wilhelmgen"으로 압축될 수 있다.

LongLLMLingua는 LLM의 응답에서 원래 내용을 복원할 수 있는 하위 시퀀스 복구 알고리즘을 제안했다.

Step 1. LLM의 응답에서 토큰 yly_l을 순회(traverse)하고, 압축된 프롬프트 x~\tilde{x}에 나타나는 가장 긴 하위 문자열 y~key,l\tilde{y}_{key,l}을 선택한다.
Step 2. 원래 프롬프트 xxx에서 y~key,l\tilde{y}_{key,l}y~key,l에 해당하는 최대 공통 최단 하위 시퀀스xi,jx_{i,j}xi,j를 찾는다.
Step 3. LLM의 응답에서 해당 토큰 y~key,l\tilde{y}_{key,l}y~key,l을 xi,jx_{i,j}xi,j로 대체한다.
관련 코드는 github recover 함수에서 찾을 수 있다.
Code
환경 설정은 LLMLingua와 동일하다. 테스트 코드와 결과는 다음과 같다.
from llmlingua import PromptCompressor
GSM8K_PROMPT = "Question: Angelo and Melanie want to plan how many hours over the next week they should study together for their test next week. They have 2 chapters of their textbook to study and 4 worksheets to memorize. They figure out that they should dedicate 3 hours to each chapter of their textbook and 1.5 hours for each worksheet. If they plan to study no more than 4 hours each day, how many days should they plan to study total over the next week if they take a 10-minute break every hour, include 3 10-minute snack breaks each day, and 30 minutes for lunch each day?\nLet's think step by step\nAngelo and Melanie think they should dedicate 3 hours to each of the 2 chapters, 3 hours x 2 chapters = 6 hours total.\nFor the worksheets they plan to dedicate 1.5 hours for each worksheet, 1.5 hours x 4 worksheets = 6 hours total.\nAngelo and Melanie need to start with planning 12 hours to study, at 4 hours a day, 12 / 4 = 3 days.\nHowever, they need to include time for breaks and lunch. Every hour they want to include a 10-minute break, so 12 total hours x 10 minutes = 120 extra minutes for breaks.\nThey also want to include 3 10-minute snack breaks, 3 x 10 minutes = 30 minutes.\nAnd they want to include 30 minutes for lunch each day, so 120 minutes for breaks + 30 minutes for snack breaks + 30 minutes for lunch = 180 minutes, or 180 / 60 minutes per hour = 3 extra hours.\nSo Angelo and Melanie want to plan 12 hours to study + 3 hours of breaks = 15 hours total.\nThey want to study no more than 4 hours each day, 15 hours / 4 hours each day = 3.75\nThey will need to plan to study 4 days to allow for all the time they need.\nThe answer is 4\n\nQuestion: You can buy 4 apples or 1 watermelon for the same price. You bought 36 fruits evenly split between oranges, apples and watermelons, and the price of 1 orange is $0.50. How much does 1 apple cost if your total bill was $66?\nLet's think step by step\nIf 36 fruits were evenly split between 3 types of fruits, then I bought 36/3 = 12 units of each fruit\nIf 1 orange costs $0.50 then 12 oranges will cost $0.50 * 12 = $6\nIf my total bill was $66 and I spent $6 on oranges then I spent $66 - $6 = $60 on the other 2 fruit types.\nAssuming the price of watermelon is W, and knowing that you can buy 4 apples for the same price and that the price of one apple is A, then 1W=4A\nIf we know we bought 12 watermelons and 12 apples for $60, then we know that $60 = 12W + 12A\nKnowing that 1W=4A, then we can convert the above to $60 = 12(4A) + 12A\n$60 = 48A + 12A\n$60 = 60A\nThen we know the price of one apple (A) is $60/60= $1\nThe answer is 1\n\nQuestion: Susy goes to a large school with 800 students, while Sarah goes to a smaller school with only 300 students. At the start of the school year, Susy had 100 social media followers. She gained 40 new followers in the first week of the school year, half that in the second week, and half of that in the third week. Sarah only had 50 social media followers at the start of the year, but she gained 90 new followers the first week, a third of that in the second week, and a third of that in the third week. After three weeks, how many social media followers did the girl with the most total followers have?\nLet's think step by step\nAfter one week, Susy has 100+40 = 140 followers.\nIn the second week, Susy gains 40/2 = 20 new followers.\nIn the third week, Susy gains 20/2 = 10 new followers.\nIn total, Susy finishes the three weeks with 140+20+10 = 170 total followers.\nAfter one week, Sarah has 50+90 = 140 followers.\nAfter the second week, Sarah gains 90/3 = 30 followers.\nAfter the third week, Sarah gains 30/3 = 10 followers.\nSo, Sarah finishes the three weeks with 140+30+10 = 180 total followers.\nThus, Sarah is the girl with the most total followers with a total of 180.\nThe answer is 180"
QUESTION = "Question: Josh decides to try flipping a house. He buys a house for $80,000 and then puts in $50,000 in repairs. This increased the value of the house by 150%. How much profit did he make?"
llm_lingua = PromptCompressor()
compressed_prompt = llm_lingua.compress_prompt(
GSM8K_PROMPT.split("\n\n")[0],
question = QUESTION,
# ratio=0.55
# Set the special parameter for LongLLMLingua
condition_in_question = "after_condition",
reorder_context = "sort",
dynamic_context_compression_ratio = 0.3, # or 0.4
condition_compare = True,
context_budget = "+100",
rank_method = "longllmlingua",
)
print('-' * 100)
print("original:")
print(GSM8K_PROMPT.split("\n\n")[0])
print('-' * 100)
print("compressed_prompt:")
print(compressed_prompt)
AutoCompressor
AutoCompressor는 기존에 소개한 방식과 달리 소프트 프롬프트 기반 접근 방식이다. 이 방법은 어휘를 확장하고 "요약 토큰"과 "요약 벡터"를 활용하여 컨텍스트 정보를 압축함으로써 기존 모델을 스마트하게 미세 조정한다.

Step 1. 어휘 확장: 모델의 기존 어휘에 "요약 토큰"을 추가한다. 요약 토큰은 모델이 많은 양의 정보를 작은 벡터로 압축할 수 있도록 한다.
Step 2. 문서 분할: 처리할 문서를 작은 세그먼트로 나누고, 각 세그먼트에 요약 토큰을 추가한다. 이러한 토큰은 이전 세그먼트의 요약 정보를 포함하여 요약 축적을 만든다.
Step 3. 미세 조정 훈련: "다음 단어 예측" 작업을 활용하여 모델을 미세 조정하는 비지도 학습 방법을 사용한다. 이 작업의 목표는 현재 토큰 앞의 토큰과 이전 세그먼트의 요약 벡터를 기반으로 다음 단어를 예측하는 것이다.
Step 4. 역전파: AutoCompressor는 시간 역전파(BPTT)와 그래디언트 체크포인팅을 사용하여 각 세그먼트의 계산 그래프 크기를 최소화한다. 역전파는 전체 문서에 대해 수행되어 모델이 전체 컨텍스트의 연관성을 학습할 수 있게 힌다.
Code
import torch
from transformers import AutoTokenizer
from auto_compressor import LlamaAutoCompressorModel, AutoCompressorModel
# Load AutoCompressor trained by compressing 6k tokens in 4 compression steps
tokenizer = AutoTokenizer.from_pretrained("princeton-nlp/AutoCompressor-Llama-2-7b-6k")
# Need bfloat16 + cuda to run Llama model with flash attention
model = LlamaAutoCompressorModel.from_pretrained("princeton-nlp/AutoCompressor-Llama-2-7b-6k", torch_dtype=torch.bfloat16).eval().cuda()
prompt = 'The first name of the current US president is "'
prompt_tokens = tokenizer(prompt, add_special_tokens=False, return_tensors="pt").input_ids.cuda()
context = """Joe Biden, born in Scranton, Pennsylvania, on November 20, 1942, had a modest upbringing in a middle-class family. He attended the University of Delaware, where he double-majored in history and political science, graduating in 1965. Afterward, he earned his law degree from Syracuse University College of Law in 1968.\nBiden's early political career began in 1970 when he was elected to the New Castle County Council in Delaware. In 1972, tragedy struck when his wife Neilia and 1-year-old daughter Naomi were killed in a car accident, and his two sons, Beau and Hunter, were injured. Despite this devastating loss, Biden chose to honor his commitment and was sworn in as a senator by his sons' hospital bedsides.\nHe went on to serve as the United States Senator from Delaware for six terms, from 1973 to 2009. During his time in the Senate, Biden was involved in various committees and was particularly known for his expertise in foreign affairs, serving as the chairman of the Senate Foreign Relations Committee on multiple occasions.\nIn 2008, Joe Biden was selected as the running mate for Barack Obama, who went on to win the presidential election. As Vice President, Biden played an integral role in the Obama administration, helping to shape policies and handling issues such as economic recovery, foreign relations, and the implementation of the Affordable Care Act (ACA), commonly known as Obamacare.\nAfter completing two terms as Vice President, Joe Biden decided to run for the presidency in 2020. He secured the Democratic nomination and faced the incumbent President Donald Trump in the general election. Biden campaigned on a platform of unity, promising to heal the divisions in the country and tackle pressing issues, including the COVID-19 pandemic, climate change, racial justice, and economic inequality.\nIn the November 2020 election, Biden emerged victorious, and on January 20, 2021, he was inaugurated as the 46th President of the United States. At the age of 78, Biden became the oldest person to assume the presidency in American history.\nAs President, Joe Biden has worked to implement his agenda, focusing on various initiatives, such as infrastructure investment, climate action, immigration reform, and expanding access to healthcare. He has emphasized the importance of diplomacy in international relations and has sought to rebuild alliances with global partners.\nThroughout his long career in public service, Joe Biden has been recognized for his commitment to bipartisanship, empathy, and his dedication to working-class issues. He continues to navigate the challenges facing the nation, striving to bring the country together and create positive change for all Americans."""
context_tokens = tokenizer(context, add_special_tokens=False, return_tensors="pt").input_ids.cuda()
summary_vectors = model(context_tokens, output_softprompt=True).softprompt
print(f"Compressing {context_tokens.size(1)} tokens to {summary_vectors.size(1)} summary vectors")
# >>> Compressing 660 tokens to 50 summary vectors
generation_with_summary_vecs = model.generate(prompt_tokens, do_sample=False, softprompt=summary_vectors, max_new_tokens=12)[0]
print("Generation w/ summary vectors:\n" + tokenizer.decode(generation_with_summary_vecs))
# >>> The first name of the current US president is "Joe" and the last name is "Biden".
next_tokens_without_context = model.generate(prompt_tokens, do_sample=False, max_new_tokens=11)[0]
print("Generation w/o context:\n" + tokenizer.decode(next_tokens_without_context))
# >>> The first name of the current US president is "Donald" and the last name is "Trump".LLMLingua-2
Llama-7B와 같은 인과 언어 모델에서 정보 엔트로피를 기반으로 토큰이나 어휘 단어를 삭제하여 프롬프트를 압축하는 것과 관련된 두 가지 문제를 식별한다.
Problem 1. 정보 엔트로피를 결정하는 데 사용되는 작은 언어 모델이 프롬프트 압축 목표와 일치하지 않는다.
Problem 2. 단방향 문맥만을 사용하여 프롬프트 압축에 필요한 모든 정보를 포함하지 않을 수 있다.
이 문제들의 핵심은 정보 엔트로피가 압축을 위한 최적의 측정치가 아닐 수 있다는 점이며, LLMLingua-2의 전체 아키텍처는 다음과 같다.

문제 1을 해결하기 위해 LLMLingua-2는 데이터 증류 과정을 도입한다. 이 과정은 대형 언어 모델(LLM)로부터 지식을 추출하여 핵심 정보를 잃지 않고 프롬프트를 압축하고, 동시에 추출적 텍스트 압축 데이터셋을 구성한다. 구성한 압축 데이터세트를 훈련함으로써, 작은 언어 모델이 프롬프트 압축에 효과적으로 맞춰지도록 한다.
문제 2를 해결하기 위해 LLMLingua-2는 프롬프트 압축을 토큰 분류 문제로 다룬다. 이 접근 방식은 압축된 프롬프트가 원본과의 일관성을 유지하도록 하며, 프롬프트 압축을 위해 필요한 모든 정보를 양방향 문맥에서 캡처하기 위해 기본 아키텍처로 트랜스포머 인코더를 사용한다.
How to Construct an Effective Prompt Compression Dataset
Data distilation
데이터 증류는 GPT-4와 같은 대형 언어 모델에서 지식을 추출하여 핵심 정보를 잃지 않고 프롬프트를 효과적으로 압축하는 과정을 포함한다. LLMLingua-2에서 사용하는 지침은 신중하게 설계되었으며, 이는 GPT-4가 생성 과정에서 새로운 단어를 추가하지 않고 원본 텍스트에서 중요하지 않은 단어를 생략하여 텍스트를 압축하도록 요구한다. 동시에, 지침은 압축 비율 제한을 부과하지 않으며, 대신 GPT-4에게 최대한 많은 정보를 유지하면서 원본 텍스트를 가능한 한 많이 압축하도록 요청한다.

GPT-4는 매우 긴 문맥을 처리할 때 종종 높은 압축 비율을 적용하는데, 이는 긴 문맥을 처리하는 데 한계가 있기 때문일 수 있다. 과도한 압축은 상당한 정보 손실을 초래하여 이후 작업의 성능에 크게 영향을 미친다.

이 문제를 완화하기 위해 LLMLingua-2는 청크 압축 방법을 채택하여 긴 텍스트를 512 토큰을 넘지 않는 여러 청크로 나누고, GPT-4가 각 블록을 별도로 압축하도록 유도한다.
Data Annotation
데이터 증류를 통해 원본 텍스트와 압축된 버전의 쌍을 확보했다. 데이터 주석의 목적은 원본 텍스트의 각 토큰에 이진 라벨을 할당하여 압축 후에 해당 토큰을 유지할지 여부를 결정하는 것이다. GPT-4가 지침을 정확히 따르지 않을 수 있기 때문에, LLMLingua-2는 슬라이딩 윈도우 기법을 사용하여 검색 범위를 제한한다. 또한, GPT-4가 압축 과정에서 원본 단어를 변경할 가능성을 처리하기 위해 퍼지 매칭을 활용한다.
Quality Control
LLMLingua-2는 GPT-4 증류를 통해 생성된 압축 텍스트와 자동 주석 라벨의 품질을 평가하기 위해 변동률(VR)과 정렬 간격(AG), 2가지 품질 관리 지표를 사용한다.변동률(Variation Rate)은 압축된 텍스트에서 원본 텍스트와 다른 단어의 비율을 측정하고, 정렬 간격(Alignment Gap)은 자동 주석 라벨의 품질을 평가한다. 이러한 지표를 사용하여 LLMLingua-2는 저품질 샘플을 제외함으로써 데이터셋의 품질을 보장할 수 있다.
Compressor
Viewed as a Binary Classification Problem
초기에는 프롬프트 압축 문제를 이진 분류 문제로 변환할 수 있다. 기본 개념은 각 어휘 단위를 독립적인 개체로 간주하고 "보존" 또는 "폐기" 라벨을 할당하는 것입니다. 이 접근 방식은 압축된 프롬프트의 콘텐츠 무결성을 유지하면서 모델의 설계를 단순화한다.
Model Architecture
트랜스포머 인코더 기반의 특징 인코더를 사용하고 그 위에 선형 분류 레이어를 추가한다. 이 아키텍처는 각 어휘 단위의 양방향 문맥 정보를 포착하여 압축 작업에 필요한 중요한 정보를 제공한다.
Compression Strategy
원래 프롬프트 x에 대한 압축 전략은 세 단계로 이루어진다. 목표 압축 비율은 1/τ로, τ는 압축된 프롬프트의 단어 수와 원래 프롬프트 x의 단어 수의 비율로 정의된다.
Step 1. 압축된 프롬프트 x˜에서 유지할 토큰의 목표 수를 결정한다: N˜ = τN.
Step 2. 토큰 분류 모델을 사용하여 각 단어 xi가 ‘보존’으로 표시될 확률 pi를 예측한다.
Step 3. 원래 프롬프트 x에서 pi 값이 가장 높은 상위 N˜ 단어를 원래 순서를 유지하여 압축된 프롬프트 x˜를 형성한다.
Code
LLMLingua-2의 주요 작업은 압축기를 구성하는 것이다. 압축기를 획득한 후 사용하는 방법은 다음과 같다. 주요 내부 과정은 github compress_prompt_llmlingua2 함수에서 확인할 수 있다.
from llmlingua import PromptCompressor
PROMPT = "John: So, um, I've been thinking about the project, you know, and I believe we need to, uh, make some changes. I mean, we want the project to succeed, right? So, like, I think we should consider maybe revising the timeline.\n\nSarah: I totally agree, John. I mean, we have to be realistic, you know. The timeline is, like, too tight. You know what I mean? We should definitely extend it."
llm_lingua = PromptCompressor(
model_name = "microsoft/llmlingua-2-xlm-roberta-large-meetingbank",
use_llmlingua2 = True,
)
compressed_prompt = llm_lingua.compress_prompt(PROMPT, rate=0.33, force_tokens = ['\n', '?'])
## Or use LLMLingua-2-small model
# llm_lingua = PromptCompressor(
# model_name="microsoft/llmlingua-2-bert-base-multilingual-cased-meetingbank",
# use_llmlingua2=True,
# )
print('-' * 100)
print("original:")
print(PROMPT)
print('-' * 100)
print("compressed_prompt:")
print(compressed_prompt)
RECOMP
RECOMP는 두 가지 유형의 훈련된 압축기를 도입한다: 추출적 압축기와 생성적 압축기. 추출적 압축기는 검색된 문서에서 유용한 문장을 선택하고, 생성적 압축기는 여러 문서의 정보를 결합하여 요약을 생성한다.

Extractive Compressor
주어진 n개의 문장 [s1, s2, ..., sn]이 포함된 입력 문서 세트에 대해, 이중 인코더 모델을 훈련시킨다. 이 모델은 문장 si와 입력 시퀀스 x를 고정 차원의 임베딩으로 변환한다. 이 임베딩의 내적은 목표 출력 시퀀스를 생성하기 위해 입력 x에 si를 추가하는 것이 대형 언어 모델(LLM)에게 주는 이점을 나타낸다. 압축기로부터의 최종 요약문 s는 입력과의 내적에 따라 순위가 매겨진 상위 N개의 문장으로 구성된다.
Abstractive Compressor
추상적 압축기는 인코더-디코더 모델이다. 이 모델은 입력 시퀀스 x와 검색된 문서 세트를 결합하여 요약문 s를 출력한다. 이 접근법은 대형 언어 모델(예: GPT-3)을 사용하여 훈련 데이터를 생성하고, 이 데이터를 필터링한 후 필터링된 데이터셋으로 인코더-디코더 모델을 훈련시키는 과정을 포함한다.
논의된 방법 중에서 LongLLMLingua는 우수한 선택이 될 수 있으며, LLMLingua-2 같은 경우 속도와 메모리 사용 측면에서 장점이 있다.
Ref.
https://medium.com/ai-advances/advanced-rag-09-prompt-compression-95a589f7b554
'AI > Natural Language Processing' 카테고리의 다른 글
| Query Classification and Refinement (2) | 2024.06.18 |
|---|---|
| Corrective Retrieval Augmented Generation (CRAG) (0) | 2024.06.18 |
| Self-RAG (이론) (0) | 2024.06.17 |
| Exploring RAG for Tables (이론) (0) | 2024.06.14 |
| Exploring Query Rewriting (이론) (1) | 2024.06.12 |
블로그의 정보
코딩하는 오리
Cori