나의 개발 일지 (3) RAG 구현 및 개선
by Cori회사에서 하고 있는 업무는 LLM을 활용하여 사내 내부 규정집에 대한 질의응답을 하는 챗봇을 개발하는 것이다.
규정집에 대한 질의응답이 잘 되는 것을 확인하면, 스크래핑 데이터 및 외부 회사 문서들로 확장해나가려 한다.
챗봇 개발에 적용중인 알고리즘은 RAG (Retrieval-Augmented Generation)이며, 해당 알고리즘을 순차적으로
발전시켜나가는 중이다.
LLM (Large Language Model)의 한계
ChatGPT를 비롯한 여러 LLM 모델들은 자신이 학습한 데이터에 대한 질문은 답을 나쁘지 않게 한다.
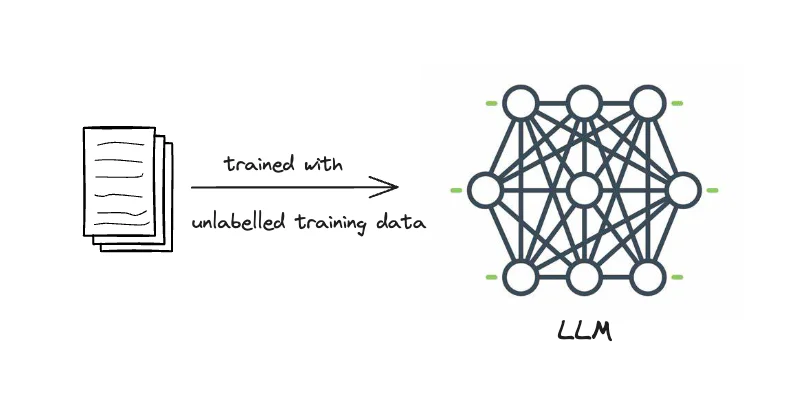
하지만 자신이 학습하지 않은 내용을 질문하는 경우, 거짓 정보를 진실된 정보인 것처럼 알려준다 (할루시네이션)

거짓 정보를 발설하는 현상을 개선하기 위해, RAG (Retrieval Augmented Generation) 기법이 등장했다. RAG는 영어 단어에서 유추해볼 수 있듯이 추출, 증강, 생성하는 단계로 이루어지며, 외부 문서에서 추가 정보를 추출하고 추출한 정보를 Prompt Template을 활용해 증강하고 이를 LLM에 전달하여 응답을 생성한다.


추출 단계에서는 사용자가 던진 질문과 관련성이 높은 정보를 외부 문서에서 '추출'해온다. 추출한 정보를 A info라 했을 때, 증강 단계에서 A info와 기존 사용자 질의를 결합해 프롬프트를 새롭게 '증강'한다.

기존 사용자 질의와 증강된 사용자 질의를 LLM에 전달했을 때 생성되는 응답을 비교하면 증강된 사용자 질의를 입력받은 모델의 출력 값이 보다 나은 것을 확인할 수 있다.
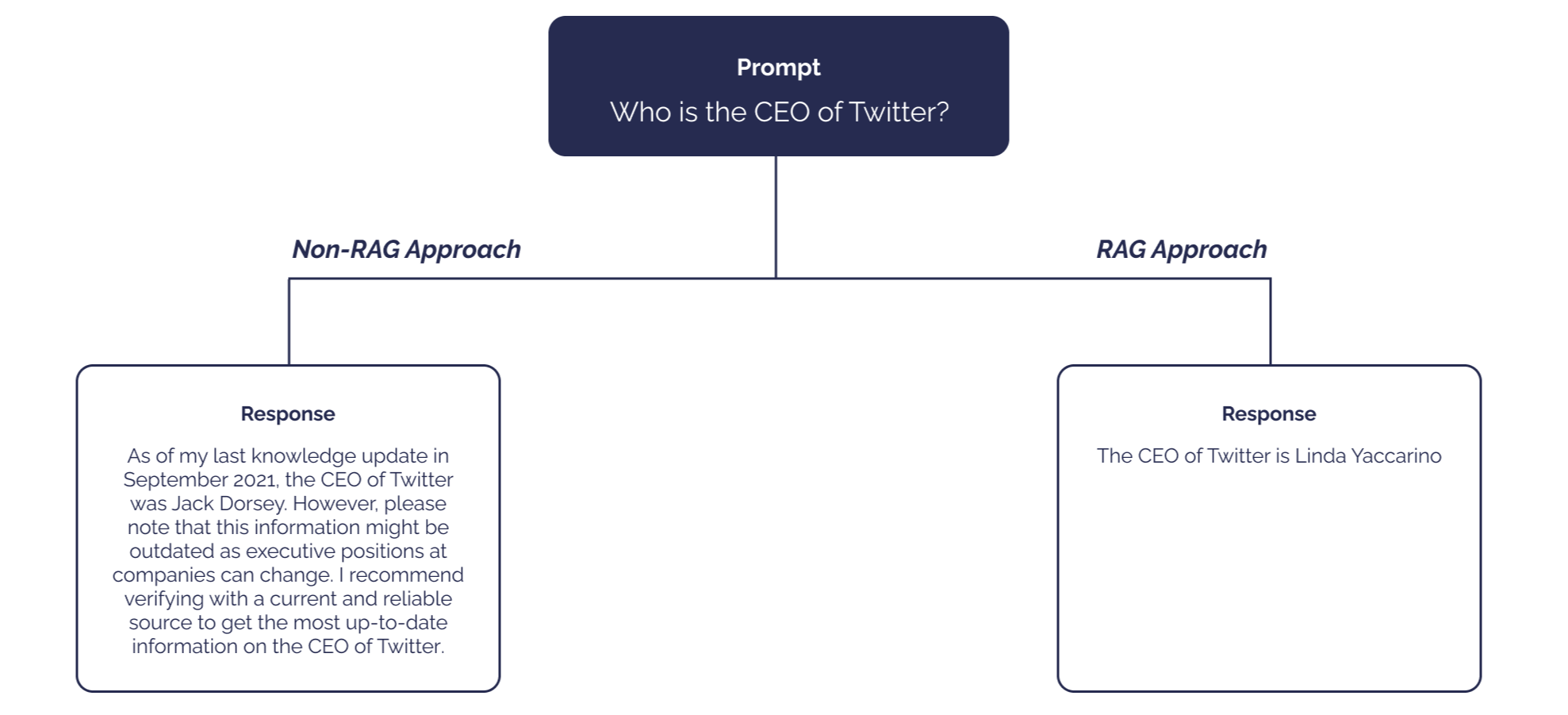
구축된 RAG 모델 아키텍처
신한은행에 전달하기 위해 스크랩한 데이터 및 자사 내부 규정집을 활용하여 RAG 아키텍처를 1차적으로 구축했다. 스크랩한 데이터를 Embedding 모델을 활용하여 벡터로 변환하고, 변환한 벡터를 데이터베이스에 저장한다. 이후 사용자가 언어 모델에 질의하면, 동일한 Embedding 모델을 활용해 질의를 벡터로 변환하고 변환한 벡터와 관련성이 높은 정보를 데이터베이스에서 추출해온다. 추출한 데이터를 프롬프트 템플릿에 전달해 프롬프트를 증강하고, 증강된 프롬프트는 언어 모델에 전달되어 개선된 응답을 생성한다.
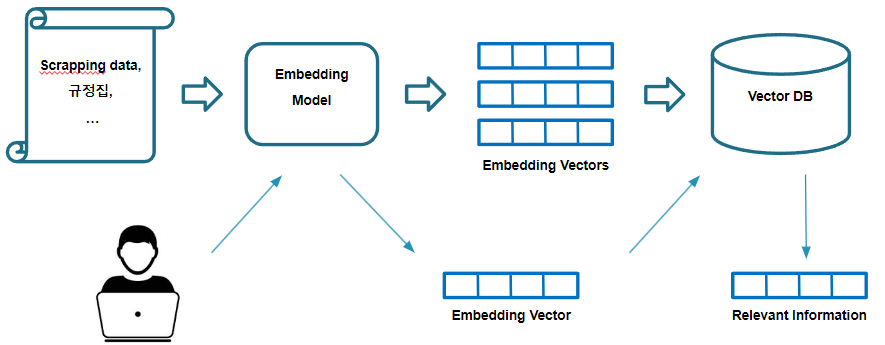
사용 데이터 & 모델

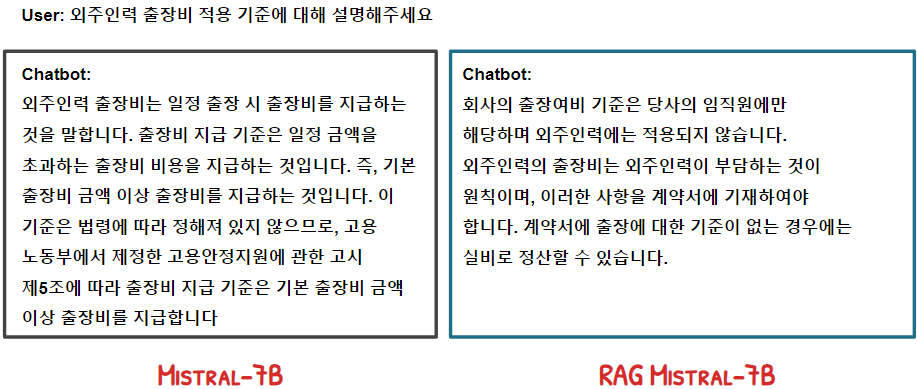
답변 예시
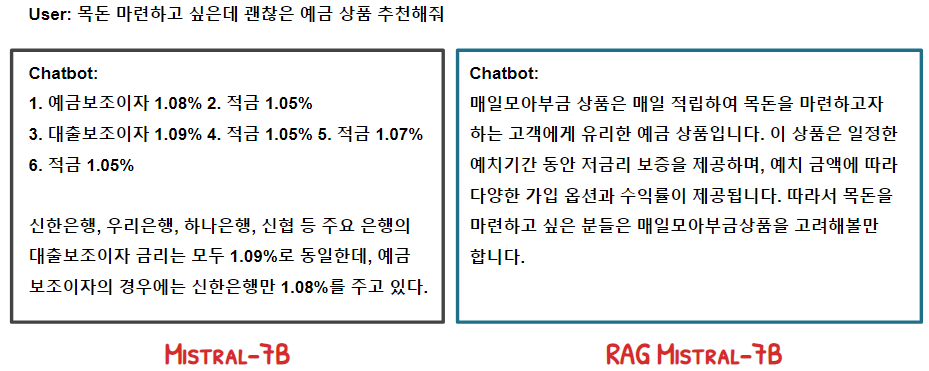
문제점
동작이 잘 하는 것처럼 보이지만, 사용자 발화와 유사한 발화를 잘 인식하지 못하는 문제가 존재한다. 이는 사용자 발화와 관련된 문서를 추출하지 못할 뿐 아니라 의도 파악에도 문제를 초래한다.
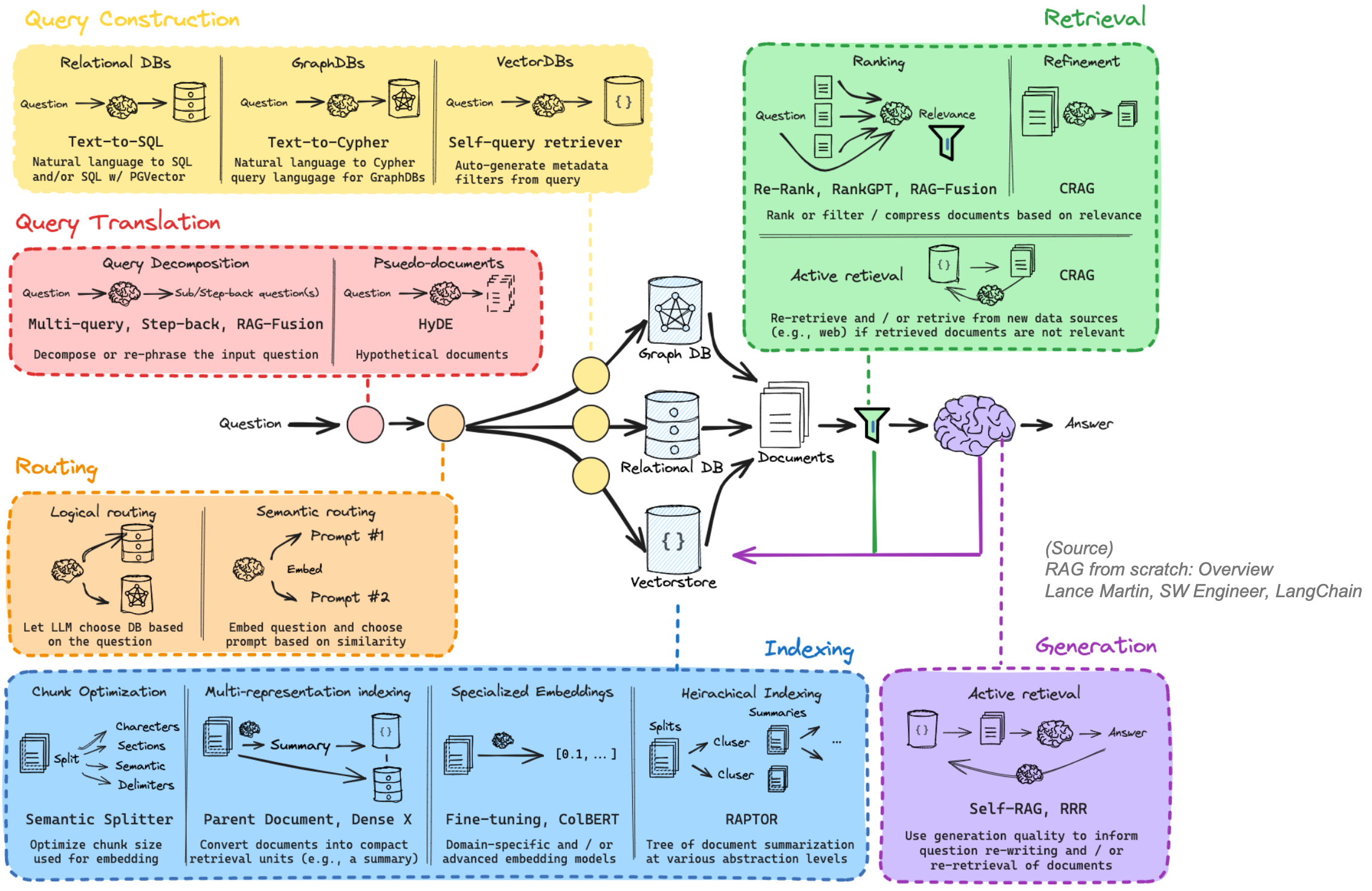
Advanced RAG
기존 RAG (Naive RAG)의 부족한 성능 개선을 위해, 우리 부서는 현재 다음과 같은 Advanced RAG 아키텍처를 차용하여 단계별로 개발중에 있다.
'BlaBla' 카테고리의 다른 글
| 현재 위치 간단하게 확인하기 (feat. 카톡) (1) | 2024.11.05 |
|---|---|
| 나의 개발 일지 (2) Docker 설정 (0) | 2024.08.12 |
| 나의 개발 일지 (1) 서버 세팅 (0) | 2024.08.12 |
| 전자서명 가능한 사이트 (0) | 2024.07.15 |
| 웹페이지 크롤링 서비스, FireCrawl (0) | 2024.07.01 |
블로그의 정보
코딩하는 오리
Cori