Exploring Semantic Chunking (이론)
by Cori해당 포스트는 Medium 'Florian June'이 작성한 Advanced RAG 포스트 시리즈 그 다섯번째 내용을 정리하며, 이 글에서는 의미 기반 청킹 방법을 탐구하고, 그 원리와 응용에 대해 다루고 있다.
가장 일반적으로 사용되는 청킹 방법은 규칙 기반 청킹 방법으로, 고정된 청크 크기나 인접 청크의 중첩등이 있다. 다중 레벨 문서의 경우, Langchain에서 제공하는 RecursiveCharacterTextSplitter를 사용할 수 있다. 실제 응용에서는 미리 정의된 규칙(청크 크기 또는 중첩 부분의 크기)이 엄격하기 때문에 규칙 기반 청킹 방법은 불완전한 검색 문맥 혹은 잡음이 포함된 과도한 청크 크기와 같은 문제를 일으키기 쉽다. 이러한 문제로 인해 의미 기반으로 청킹하는 것이 보다 성능 좋으며, 이는 각 청크가 가능한 한 많은 의미적으로 독립적인 정보를 포함하도록 하는 것을 목표로 한다.
Embedding-based methods
LlamaIndex와 Langchain 모두 임베딩 기반의 의미 청커를 제공한다.
pip install llama-index-core
pip install llama-index-readers-file
pip install llama-index-embeddings-openaifrom llama_index.core.node_parser import (
SentenceSplitter,
SemanticSplitterNodeParser,
)
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.core import SimpleDirectoryReader
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPEN_AI_KEY"
# load documents
dir_path = "YOUR_DIR_PATH"
documents = SimpleDirectoryReader(dir_path).load_data()
embed_model = OpenAIEmbedding()
splitter = SemanticSplitterNodeParser(
buffer_size=1, breakpoint_percentile_threshold=95, embed_model=embed_model
)
nodes = splitter.get_nodes_from_documents(documents)
for node in nodes:
print('-' * 100)
print(node.get_content())위 코드에서, get_nodes_from_documents 함수는 다음과 같은 프로세스를 따라 동작한다.
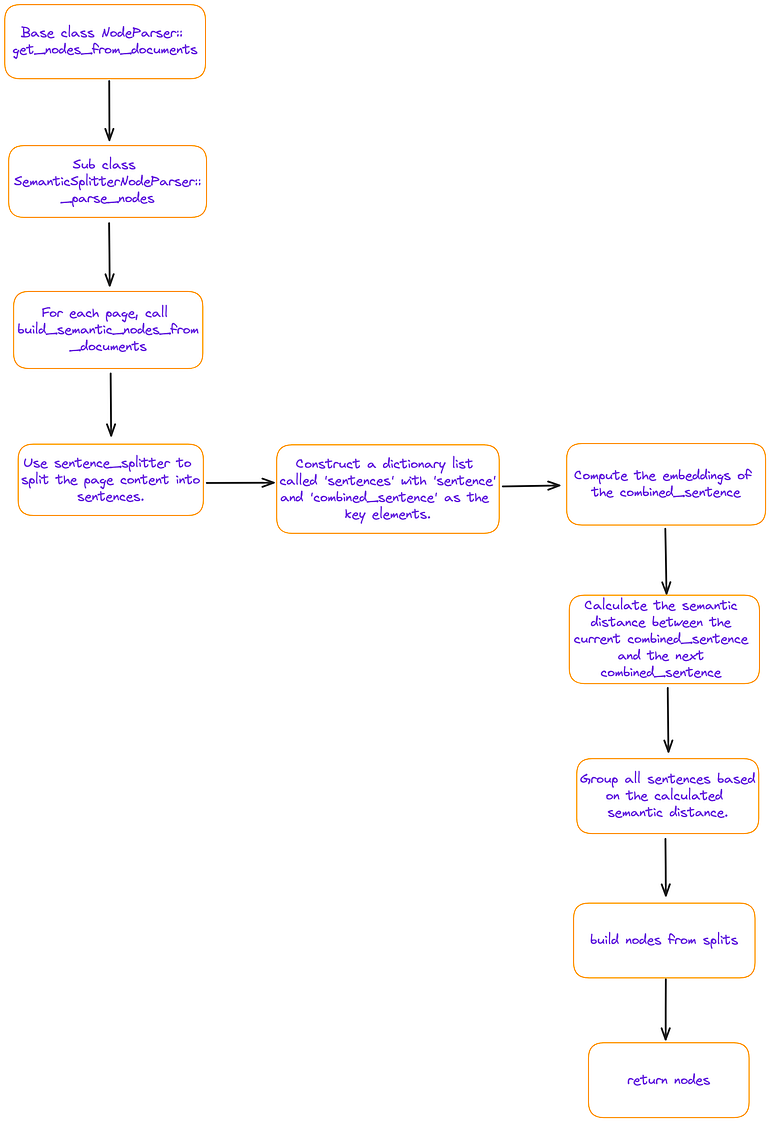
임베딩 기반의 의미 청킹은 본질적으로 슬라이딩 윈도우(combined_sentence)를 기반으로 유사성을 계산하는 것을 포함하며, 인접하고 임계값을 충족하는 문장들이 하나의 청크로 분류된다. 청킹 결과를 살펴보면 청크의 세분성이 비교적 거친 것으로 나타난다. 해당 방법은 페이지 기반이며, 여러 페이지에 걸쳐 있는 청크 문제를 직접적으로 해결하지 않는다.
Model-based methods
methods #01. Naive BERT
BERT의 사전 학습 과정에서는 이진 분류 작업인 다음 문장 예측(NSP)이 설계되어 두 문장 간의 관계를 모델에게 학습시킨다. 여기서는 두 문장을 동시에 BERT에 입력하여 두 번째 문장이 첫 번째 문장을 따르는지 예측한다. 이 원칙을 적용하여 간단한 청킹 방법을 설계할 수 있는데, 문서를 문장 단위로 분할한 후 슬라이딩 윈도우를 사용하여 두 개의 인접한 문장을 BERT 모델에 NSP 판단을 위해 입력한다.

예측된 점수가 미리 설정된 임계값보다 낮으면 두 문장 사이의 의미적 관계가 약하다는 것을 나타내며, 위 그림에서 문장 2와 문장 3 사이의 텍스트 분할 지점으로 사용할 수 있다. 해당 방식은 훈련이나 미세조정 없이 직접 사용 가능하지만, 더 먼 구간의 정보는 무시하고 앞뒤 문장만 고려한다는 한계점이 있다. (예측 효율성 상대적으로 낮음)
methods #02. Cross Segment Attention
Cross-Segment BERT는 텍스트 분할을 문장 단위 분류 작업으로 정의한다. 잠재적 분할 지점의 문맥 (양쪽의 k 토큰)을 모델에 입력하며, [CLS]에 해당하는 은닉 상태는 소프트맥스 분류기로 전달되어 잠재적 분할 지점에서 분할 여부를 결정한다. 논문에서는 추가로 두 가지 모델을 제시하며, 하나는 BERT 모델을 사용하여 각 문장의 벡터 표현을 얻는다. 연속된 문장의 벡터 표현을 Bi-LSTM(그림 (b)) 또는 또 다른 BERT(그림 (c))에 입력하여 각 문장이 텍스트 분할 경계인지 예측한다.
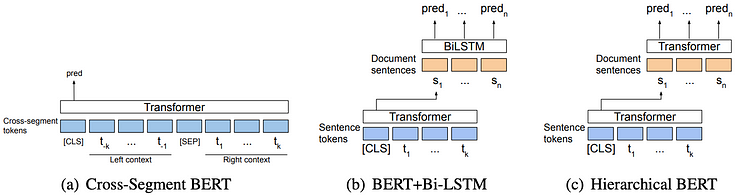
하지만, 해당 모델은 훈련 부분만 공개되어 있어 추론에 사용하기는 힘들다. 또한, 크로스 세그먼트 모델은 각 문장을 독립적으로 벡터화하며, 더 넓은 문맥 정보를 고려하지 않는다는 한계점이 있다.
methods #03. SeqModel
SeqModel은 여러 문장을 동시에 인코딩하기 위해 BERT를 사용하여 더 긴 문맥 내의 종속성을 모델링한 후 문장 벡터를 계산한다. 그런 다음 각 문장 이후에 텍스트 분할이 발생하는지 예측하는데, 추론 속도를 향상시키면서도 정확도를 저해하지 않는 자기 적응형 슬라이딩 윈도우 방법을 활용한다.
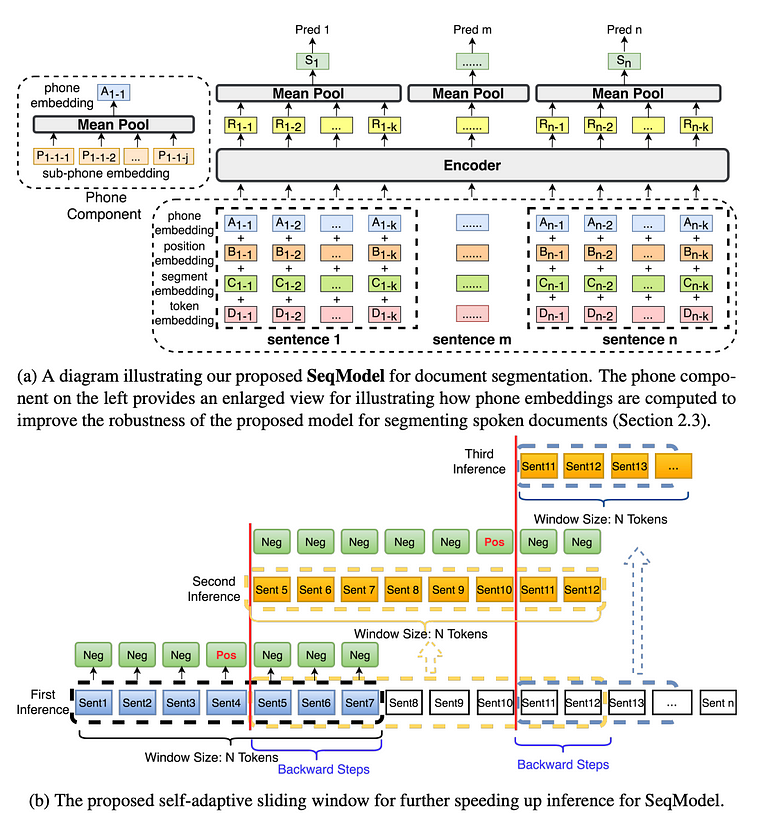
다음은 Seqmodel을 활용하는 코드 (modelscope를 통해 구현할 수 있다)로, 테스트 데이터는 끝에 "오늘은 좋은 날입니다"라는 문장을 추가했지만, 결과는 "Today is a good day"를 어떤 방식으로도 분리하지 않는다.
from modelscope.outputs import OutputKeys
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
p = pipeline(
task = Tasks.document_segmentation,
model = 'damo/nlp_bert_document-segmentation_english-base'
)
print('-' * 100)
result = p(documents='We demonstrate the importance of bidirectional pre-training for language representations. Unlike Radford et al. (2018), which uses unidirectional language models for pre-training, BERT uses masked language models to enable pretrained deep bidirectional representations. This is also in contrast to Peters et al. (2018a), which uses a shallow concatenation of independently trained left-to-right and right-to-left LMs. • We show that pre-trained representations reduce the need for many heavily-engineered taskspecific architectures. BERT is the first finetuning based representation model that achieves state-of-the-art performance on a large suite of sentence-level and token-level tasks, outperforming many task-specific architectures. Today is a good day')
print(result[OutputKeys.TEXT])LLM-based methods
논문 'Dense X Retrieval: What Retrieval Granularity Should We Use?'에서는 새로운 검색 단위인 '명제'를 소개한다. 명제는 텍스트 내에서 독립적인 사실을 담고 있는 원자적 표현으로 정의되며, 간결하고 독립적인 자연어 형식으로 제시된다.
해당 논문에서는 프롬프트를 구성하고 대형 언어 모델(LLM)과 상호작용하여 '명제'를 획득한다. 사용하는 프롬프트 템플릿 예제는 다음과 같다.
PROPOSITIONS_PROMPT = PromptTemplate(
""" "Content"를 명확하고 간단한 명제로 분해하여 문맥 없이도 해석 가능하도록 하세요.
1. 복합 문장을 간단한 문장으로 나누세요. 가능하면 입력의 원래 문구를 유지하세요.
2. 추가적인 설명 정보를 동반한 명명된 엔티티에 대해 이 정보를 별도의 독립된 명제로 분리하세요.
3. 명사를 수식하거나 전체 문장에 필요한 수식어를 추가하고 대명사(예: "it", "he", "she", "they", "this", "that")를 지칭하는 엔티티의 전체 이름으로 대체하여 명제를 문맥에서 벗어나게 만드세요.
4. 결과를 문자열 목록으로 제시하되, JSON 형식으로 포맷하세요.
Input: Title: ¯Eostre. Section: Theories and interpretations, Connection to Easter Hares. Content: The earliest evidence for the Easter Hare (Osterhase) was recorded in south-west Germany in 1678 by the professor of medicine Georg Franck von Franckenau, but it remained unknown in other parts of Germany until the 18th century. Scholar Richard Sermon writes that "hares were frequently seen in gardens in spring, and thus may have served as a convenient explanation for the origin of the colored eggs hidden there for children. Alternatively, there is a European tradition that hares laid eggs, since a hare’s scratch or form and a lapwing’s nest look very similar, and both occur on grassland and are first seen in the spring. In the nineteenth century the influence of Easter cards, toys, and books was to make the Easter Hare/Rabbit popular throughout Europe. German immigrants then exported the custom to Britain and America where it evolved into the Easter Bunny."
Output: [ "The earliest evidence for the Easter Hare was recorded in south-west Germany in 1678 by Georg Franck von Franckenau.", "Georg Franck von Franckenau was a professor of medicine.", "The evidence for the Easter Hare remained unknown in other parts of Germany until the 18th century.", "Richard Sermon was a scholar.", "Richard Sermon writes a hypothesis aboutthe possible explanation for the connection between hares and the tradition during Easter", "Hares were frequently seen in gardens in spring.", "Hares may have served as a convenient explanation for the origin of the colored eggs hidden in gardens for children.", "There is a European tradition that hares laid eggs.", "A hare’s scratch or form and a lapwing’s nest look very similar.", "Both hares and lapwing’s nests occur on grassland and are first seen in the spring.", "In the nineteenth century the influence of Easter cards, toys, and books was to make the Easter Hare/Rabbit popular throughout Europe.", "German immigrants exported the custom of the Easter Hare/Rabbit to Britain and America.", "The custom of the Easter Hare/Rabbit evolved into the Easter Bunny in Britain and America." ]
Input: {node_text}
Output:"""
)실습을 위해서는, LlamaIndex의 DenseXRetrievalPack을 별도로 설치해야 한다. 설치 후 간단한 테스트를 진행해보자.
from llama_index.core.readers import SimpleDirectoryReader
from llama_index.core.llama_pack import download_llama_pack
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_KEY"
# Download and install dependencies
DenseXRetrievalPack = download_llama_pack(
"DenseXRetrievalPack", "./dense_pack"
)
# If you have already downloaded DenseXRetrievalPack, you can import it directly.
# from llama_index.packs.dense_x_retrieval import DenseXRetrievalPack
dir_path = "YOUR_DIR_PATH"
documents = SimpleDirectoryReader(dir_path).load_data() # Load documents
# Use LLM to extract propositions from every document/node
dense_pack = DenseXRetrievalPack(documents)
response = dense_pack.run("YOUR_QUERY")DenseXRetrieval 클래스는 다음과 같은 형태를 가지고 있다.
class DenseXRetrievalPack(BaseLlamaPack):
def __init__(
self,
documents: List[Document],
proposition_llm: Optional[LLM] = None,
query_llm: Optional[LLM] = None,
embed_model: Optional[BaseEmbedding] = None,
text_splitter: TextSplitter = SentenceSplitter(),
similarity_top_k: int = 4,
) -> None:
"""Init params."""
self._proposition_llm = proposition_llm or OpenAI(
model="gpt-3.5-turbo",
temperature=0.1,
max_tokens=750,
)
embed_model = embed_model or OpenAIEmbedding(embed_batch_size=128)
nodes = text_splitter.get_nodes_from_documents(documents)
sub_nodes = self._gen_propositions(nodes)
all_nodes = nodes + sub_nodes
all_nodes_dict = {n.node_id: n for n in all_nodes}
service_context = ServiceContext.from_defaults(
llm=query_llm or OpenAI(),
embed_model=embed_model,
num_output=self._proposition_llm.metadata.num_output,
)
self.vector_index = VectorStoreIndex(
all_nodes, service_context=service_context, show_progress=True
)
self.retriever = RecursiveRetriever(
"vector",
retriever_dict={
"vector": self.vector_index.as_retriever(
similarity_top_k=similarity_top_k
)
},
node_dict=all_nodes_dict,
)
self.query_engine = RetrieverQueryEngine.from_args(
self.retriever, service_context=service_context
)text_splitter를 사용하여 문서를 원래 노드로 나눈 후, self._gen_propositions를 호출하여 명제를 생성함으로써 해당하는 하위 노드를 얻는 것입니다. 그런 다음 nodes + sub_nodes를 사용하여 VectorStoreIndex를 구축하며, 이는RecursiveRetriever를 통해 검색할 수 있다. 노드와 서브 노드의 관계는 다음과 같다.

각 원래 노드에 대해, 비동기적으로 self._aget_proposition을 호출하여 PROPOSITIONS_PROMPT를 통해 LLM의 초기 출력(initial_output)을 얻은 다음, 이 초기 출력을 기반으로 명제를 얻고 TextNode를 생성한다. 마지막으로, 이러한 TextNode를 원래 노드와 연관시킨다. LLM이 생성한 명제를 훈련 데이터로 사용하여 텍스트 생성 모델을 추가로 미세 조정한다는 것은 주목할 만 하며, 해당 텍스트 생성 모델은 공개적으로 접근 가능하다.
Ref.
'AI > Natural Language Processing' 카테고리의 다른 글
| Exploring RAG for Tables (이론) (0) | 2024.06.14 |
|---|---|
| Exploring Query Rewriting (이론) (1) | 2024.06.12 |
| Re-ranking (이론) (0) | 2024.06.11 |
| Using RAGAs + LlamaIndex for RAG evaluation (이론) (1) | 2024.06.11 |
| Unveiling PDF Parsing: How to extract formulas from scientific pdf papers (0) | 2024.06.10 |
블로그의 정보
코딩하는 오리
Cori