과적합과 일반화
by Cori개요
과적합에 대해서 알아보고, 이러한 상황에서 하이퍼파라미터 튜닝을 통해 일반화하는 방법에 대해 알아본다.
내용 정리
1. 과적합과 일반화
1) 과대적합 (overfitting)
· 모델이 훈련 데이터에 대한 예측 성능은 너무 좋지만 일반성이 떨어져 새로운 데이터 (테스트 데이터)에 대해선 성능이 좋지 않은 것
· 모델이 훈련 데이터 세트의 특징에 너무 맞춰서 학습되었기 때문에 일반화 되지 않아 발생
* 과대적합은 학습 데이터 양에 비해 모델이 너무 복잡한 경우 발생하며, 이를 해결하기 위해 데이터의 양을 늘리거나 모델을 좀 더
단순하게 만드는 방법을 사용한다. (모든 모델은 모델의 복잡도를 변경할 수 있는 규제와 관련된 하이퍼파라미터를 제공)
2) 과소적합 (underfitting)
· 모델이 훈련 데이터와 테스트 데이터셋 모두에 대해 성능이 안 좋은 것
· 모델이 너무 간단하여 훈련 데이터에 대해 충분히 학습하지 못해 발생 (데이터셋의 패턴들을 다 찾아내지 못해서 발생)
* 과소적합은 학습 데이터 양에 비해 모델이 너무 단순한 경우 발생하며, 이를 해결하기 위해 사용한 모델보다 좀 더 복잡한 모델을
사용하거나 모델이 제공하는 규제 하이퍼파라미터를 조절하는 방법을 사용한다.

3) 규제 하이퍼파라미터
· 모델의 복잡도를 규제하는 하이퍼파라미터로, overfitting이나 underfitting이 발생한 경우 이 값을 조정하여 모델이 일반화 되도록 도와줌
· 모든 머신러닝 모델마다 있음
* 하이퍼파라미터 vs 파라미터
· 하이퍼파라미터 = 모델의 성능에 영향을 끼치는 파라미터 값으로 모델 생성 시 사람이 직접 지정해 주는 값
· 파라미터 = 머신러닝에서 파라미터는 모델이 데이터 학습을 통해 직접 찾아야 하는 값
4) 일반화 (generalization)
· 모델이 새로운 데이터셋 (테스트 데이터)에 대해 정확히 예측하는 경우
· 모델이 훈련 데이터로 평가한 결과와 테스트 데이터로 평가한 결과의 차이가 거의 없고, 좋은 평가 지표를 보여준다.
2. Decision Tree 복잡도 제어
0) 모델의 복잡도 관련 주요 하이퍼파라미터
· max_depth: 트리의 최대 깊이
· max_leaf_nodes: 리프노드 개수
· min_samples_leaf: leaf 노드가 되기위한 최소 샘플 수
· min_samples_split: 나누는 최소 샘플 수
1) 실습
· 데이터 읽어들이기

· DecisionTreeClassifier 생성 및 최적의 max_depth 찾기

트리 깊이를 1부터 5까지 설정하여 각각의 트리에 대해 학습하고, 평가 결과를 저장한다.
· 결과 확인

* rename_axis() 함수를 통해 index의 이름을 'Max Depth'로 설정하고, column들의 이름을 'dataset'으로 설정하였다.
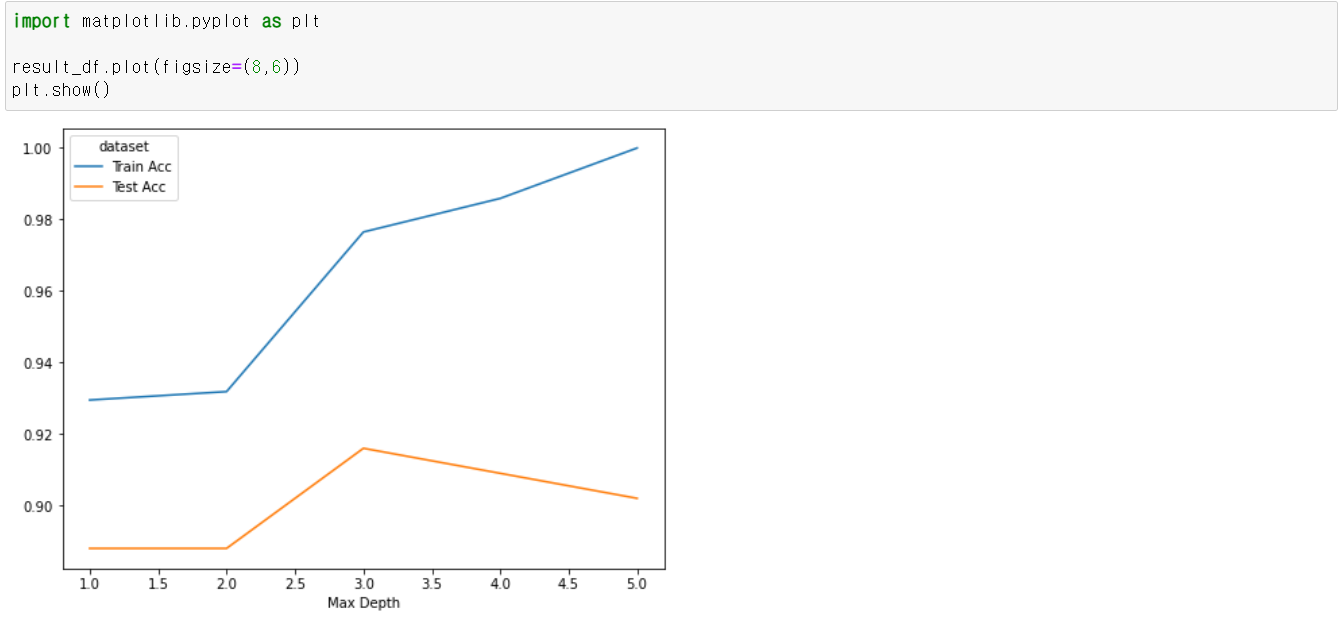
max depth는 3으로 설정할 때의 test set 정확도가 가장 높게 나온 것을 확인할 수 있다.
'AI > Machine Learning' 카테고리의 다른 글
| 그리드서치와 랜덤서치 (0) | 2021.11.29 |
|---|---|
| 불균형 클래스 분류 다루기 (0) | 2021.11.28 |
| 수치형 데이터 전처리 (0) | 2021.11.25 |
| One-Hot Encoding (0) | 2021.11.24 |
| Label Encoding (0) | 2021.11.23 |
블로그의 정보
코딩하는 오리
Cori