불균형 클래스 분류 다루기
by Cori개요
데이터 불균형이 무엇인지 알아보고, 이를 해결할 수 있는 방법들 중 Cost-sensitive Learning 기법과 SMOTE 기법에 대해 다룬다.
내용 정리
1. 데이터 불균형
0) 정의
-> 어떤 데이터에서 각 클래스 (주로 범주형 변수)가 가지고 있는 데이터의 양에 차이가 큰 경우를 말한다.
예시) 이번 포스팅에서 다룰 대출 문제 예측 데이터셋에도 데이터 불균형이 있다.

불균형 데이터에 대해 아무런 처리도 하지 않고 예측을 수행하면, 다음과 같은 결과가 발생한다.

1번 클래스 데이터 (소수)를 0번 클래스 데이터 (다수)로 예측하는 경우가 상당히 많으며, 이에 데이터 불균형 문제를 해결해보려고 한다.
1) 해결 방법
· 언더 샘플링
-> 불균형한 데이터 셋에서 높은 비율을 차지하던 클래스의 데이터 수를 줄임으로써 데이터 불균형을 해소한다.
from imblearn.under_sampling import RandomUnderSampler
X_resampled, y_resampled = RandomUnderSampler(random_state=0).fit_resample(X, y)* 언더 샘플링은 학습에 사용되는 전체 데이터 수를 급격하게 감소시키는 과정에서 필요한 정보들 또한 삭제할 수 있기 떄문에 오히려 성능이 떨어질 수도 있다.
· 오버 샘플링
-> 낮은 비율 클래스의 데이터 수를 늘림으로써 데이터 불균형을 해소한다.
from imblearn.over_sampling import RandomOverSampler
X_resampled, y_resampled = RandomOverSampler(random_state=0).fit_resample(X, y)* 일반적인 오버 샘플링을 사용하면 같은 데이터를 중복하여 생성하기 때문에, 학습시에 overfitting을 불러일으킬 수 있다. 또한, 데이터 양이 경우에 따라 상당히 늘어날 수도 있어 학습에 많은 시간이 소요된다는 단점이 있다.
※ 일반 오버샘플링과 언더샘플링의 경우 성능이 좋지는 않기 때문에, 이번 포스팅에서 실습하지는 않을 예정
· SMOTE (오버 샘플링)
① 소수 클래스에서 각각의 샘플들의 knn을 찾는다.
② 그 이웃들 사이에 선을 그어 무작위 점을 생성한다.
4) ADASYN (오버 샘플링)
-> SMOTE의 개선된 버전으로, SMOTE와 동일한 프로세스를 진행한 후 임의의 작은 값들을 더해줌으로써 조금 더 사실적인 데이터를 생성한다. (모든 표본이 약간 더 분산됨)
5) Cost-sensitive Learning (비용민감 학습)
-> 데이터 자체를 생성하지는 않지만, 머신러닝을 학습할 때 소수의 클래스에 대한 cost 값에 가중치를 더 많이 주어 균형 잡힌 학습이 가능하게 한다.
2. Cost Sensitive Learning을 활용한 데이터 불균형 문제 해결
-> Cost Sensitive Learning을 활용하면, 소수의 클래스에 더 많은 가중치를 줄 수 있기 때문에 데이터 불균형이 발생한 데이터셋에 대해서도 기존의 학습 방식보다 좀 더 나은 결과를 얻을 수 있다.
0) 사전 작업
· 클레스 레이블 불균형 검사

전체 150,000개의 데이터 중 대출 연체 데이터는 10,026개로, 전체의 6.68%를 차지하고 있음을 알 수 있다. 이러한 데이터셋에 결측치 처리, 이상치 처리를해 주고 난 후 (해당 포스팅에서는 생략) 다음 작업을 한다.
· 데이터셋 조회

SD2 컬럼이 우리가 찾고자 하는 목표 변수로, 최근 2년 동안 90일 이상 연체한 적이 있으면 1, 없으면 0을 가진다.
· 종속 변수, 독립 변수 분리

· Train Data, Test Data 분리

· 필요 라이브러리 import

1) Cost-sensitive Learning을 적용하지 않은 RandomForestClassifier
· 모델 생성 & 학습

· 모델 평가

predict() 함수와 predict_proba() 함수를 이용하여 예측 점수, 예측 확률을 계산하였다.

0번 클래스 (연체한 적 없음)는 대부분 0번 클래스로 예측한 반면 1번 클래스들 또한 0번 클래스로 상당히 많이 예측하였다.
2) Cost-sensitive Learning을 적용한 RandomForest Classifier
· 모델 생성 & 학습

weights가 추가되었다는 점을 제외하면 별로 달라진 부분은 없다. RandomForestClassifier() 함수의 class_weight 부분에 인자값으로 전달. 클래스 1이 소수 데이터이므로, 더 많은 가중치를 주어 학습하도록 설정 해 주었다.
· 모델 평가


Cost-sensitive learning을 적용하여 모델 평가를 진행해 본 결과, 앞서 예측을 잘 하지 못했던 1번 클래스의 예측 정확도도 상당히 많이 올라간 것을 확인할 수 있다.
3. SMOTE 기법을 이용한 데이터 불균형 해결
· imblearn 패키지 설치

· SMOTE 기법 적용
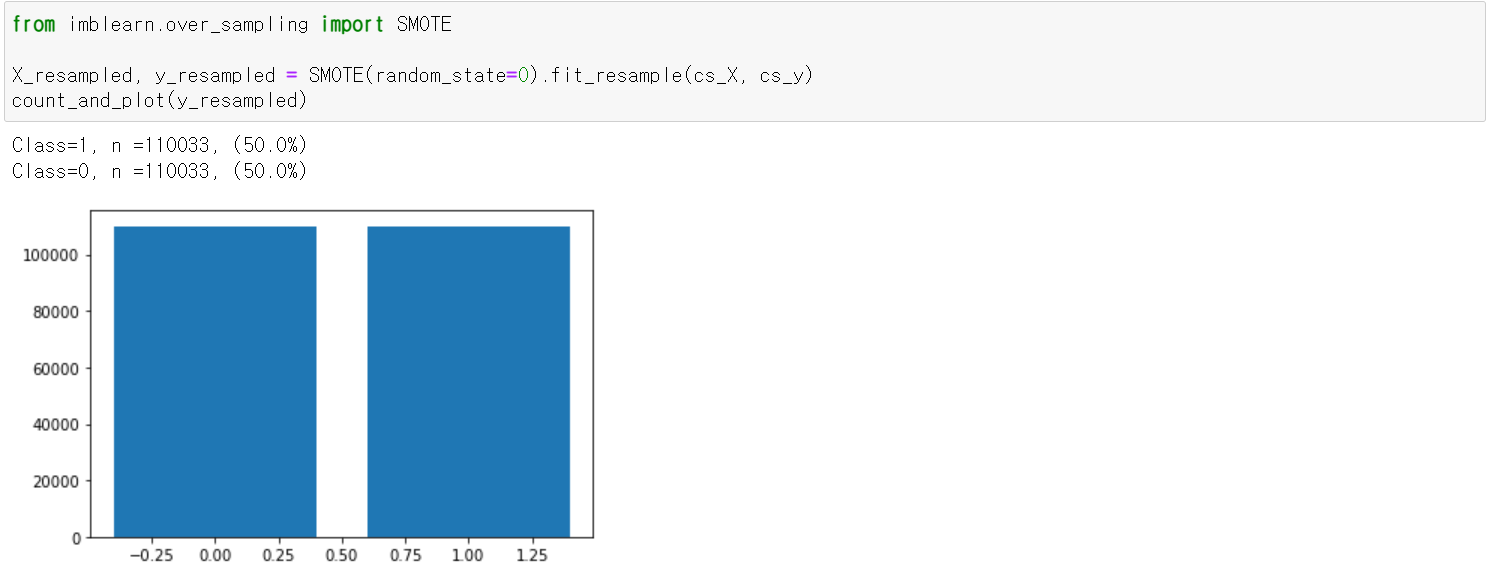
데이터 양이 대폭 늘어난 것을 확인할 수 있다.
· 파이프라인 생성

· 그리드서치 적용

· 모델 평가

앞서 예측을 잘 하지 못했던 1번 클래스의 예측 정확도도 상당히 많이 올라간 것을 확인할 수 있다. 이렇게 데이터 불균형이 발생하는 클래스에 대해 가중치를 적용하고, 오버 샘플링을 통해 문제를 해결하는 방법에 대해 알아보았다.
* Reference
1) 불균형 클래스 분류
불균형 클래스 분류(Imbalanced Classification)를 위한 4가지 방법
머신러닝으로 불균형 데이터를 분류하는 대부분의 예시는 이항 클래스 분류에 초점을 맞추고 있다. 그래서 이번엔 다중 클래스 불균형 데이터(Multi-class imbalanced data)를 처리하는 포스팅을 기록
dining-developer.tistory.com
2) [튜토리얼2] 불균형 데이터 분류하기
[튜토리얼2] 불균형 데이터 분류하기
공부중인 개발자 블로그.
limjun92.github.io
3) 언더 샘플링과 오버 샘플링
언더 샘플링(Undersampling)과 오버 샘플링(Oversampling)
* 해당 포스팅은 파이썬 머신러닝 완벽 가이드(권철민, 2019) 교재를 참고하여 공부하며 작성한 글입니다. 순서 언더 샘플링과 오버 샘플링의 개념 SMOTE 개념 SMOTE 코드 1. 언더 샘플링과 오버 샘
hwi-doc.tistory.com
'AI > Machine Learning' 카테고리의 다른 글
| 앙상블 Voting (0) | 2021.12.01 |
|---|---|
| 그리드서치와 랜덤서치 (0) | 2021.11.29 |
| 과적합과 일반화 (0) | 2021.11.26 |
| 수치형 데이터 전처리 (0) | 2021.11.25 |
| One-Hot Encoding (0) | 2021.11.24 |
블로그의 정보
코딩하는 오리
Cori