앙상블 Voting
by Cori개요
Hard Voting, Soft Voting이 무엇인지 알아보고, 이들을 활용하는 예제를 다뤄본다.
내용 정리
1. Voting
0) 정의
-> 서로 다른 종류의 알고리즘들을 결합하여 다수결 방식으로 최종 결과 출력한다.
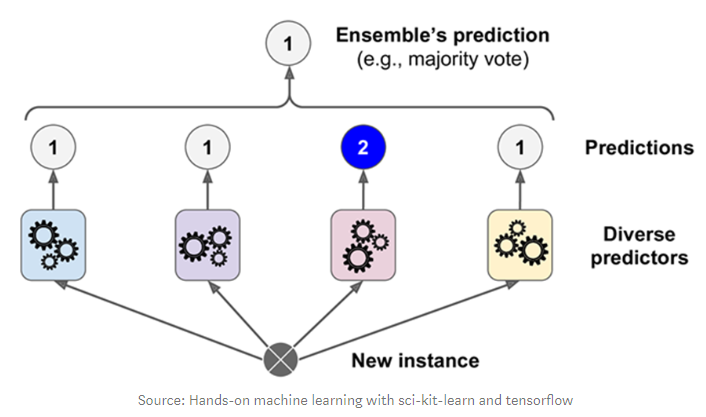
1) Hard Voting
-> 다수의 추정기가 예측한 값들 중 많은 것을 선택한다.
2) Soft Voting
· 서로 다른 종류의 알고리즘들을 결합하여 다수결 방식으로 최종 결과 출력
· 다수의 추정기에서 각 레이블 별 예측한 확률들의 평균을 내서 높은 레이블값을 결과값으로 선택
· Hard Voting보다 Soft Voting의 성능이 더 좋다.

3) voting 함수
sklearn.ensemble.VotingClassifier
· estimators: 앙상블할 모델들을 설정한다. ("추정기이름", 추정기)의 튜플을 리스트로 묶어서 전달
· voting: voting 방식을 설정한다. (hard: 기본값, soft: 지정)
4) 활용
· 필요 라이브러리 Import

· 데이터셋 로딩 및 Train & Test Set split

· 데이터 전처리
-> SVM, KNN, Random Forest 모델을 앙상블하려 하는데, SVM과 KNN은 Feature Scaling이 필요한 반면 Random Forest의 경우 Decision Tree 기반이기 때문에 Feature Scaling이 필요없다.


· SVM, KNN, Random Forest 모델 생성, 학습, 예측

SVM, KNN 모델에 대해서는 X_train_scaled 데이터를, Random Forest 모델에 대해서는 X_train 데이터를 사용한다.
* SVC 모델을 만들 떄에는 predict_proba 사용을 위해 probability = True로 설정하는 것이 필수다.
· 각 모델 별 성능 평가

· VotingClassifier를 이용한 앙상블 (Hard Voting)

모델들을 ("이름", 모델객체) 형태로 묶어주고, 모델에 이름을 붙여 앙상블한다. 모델 평가를 해보면 다음과 같은 성능이 나온다.

· VotingClassifier를 이용한 앙상블 (Soft Voting)

Hard Voting과의 차이점은 VotingClassifier의 voting 인자에 'soft'로 설정했다는 것이다. 모델 평가를 해보면 다음과 같은 성능이 나온다.

Hard Voting에 비해 Train Set과 Test Set의 성능이 조금씩 향상된 것을 확인할 수 있다.
· Pipeline을 이용하여 데이터전처리 & 모델 묶어서 처리
-> SVC, KNN 모델의 경우 Feature Scaling이 필요하기 때문에 Pipeline으로 묶어서 처리하고, Random Forest의 경우 Feature Scaling이 불필요하기 때문에 Pipeline 없이 처리한다.

RandomForest의 경우 Pipeline을 사용하지 않은 것을 확인할 수 있다.
* soft voting일 경우에는 predict_proba, hard voting일 경우에는 predict를 사용

'AI > Machine Learning' 카테고리의 다른 글
| 그리드서치와 랜덤서치 (0) | 2021.11.29 |
|---|---|
| 불균형 클래스 분류 다루기 (0) | 2021.11.28 |
| 과적합과 일반화 (0) | 2021.11.26 |
| 수치형 데이터 전처리 (0) | 2021.11.25 |
| One-Hot Encoding (0) | 2021.11.24 |
블로그의 정보
코딩하는 오리
Cori