[크롤링] 3. 외국인 관광객 데이터 다루기 (1)
by Cori월별 외국인 관광객 통계에 대한 데이터를 수집하고, 파이썬에서 이를 전처리한다. 전처리한 결과를 시각화하여 국적별로 외국인 관광객 수에 어떤 계절적인 패턴이 있는지, 외국인 관광객의 방문이 증가 또는 감소한 원인이 되는 이벤트들이 무엇인지 분석한다.
* 해당 포스팅에서 다루고 있는 모든 내용은 다음 서적을 참고하였습니다.
직장인을 위한 데이터 분석 실무 with 파이썬(개정판)(위키북스 데이터 사이언스 시리즈 63)
‘데이터 분석은 좋은 질문에서 시작합니다’이 책에서는 누구나 궁금했던 그 질문에 대해 데이터로 답해 봅니다. 이 책은 파이썬을 처음 접하는 마케팅, 영업, 기획 실무 담당자들이 파이썬을
book.naver.com
사용 데이터
한국관광공사에서 관광 목적으로 입국한 외국인 월벌 통계 데이터 (2010.01 ~ 2020.05)


* 파일을 살펴본 결과, 엑셀의 첫 번째 행과 70~73번째 행은 사용하지 않아도 되며, 엑셀의 A~G 총 7개의 컬럼만 분석에 사용하면 된다.
0. 파이썬에서 엑셀 데이터 불러오기
import pandas as pd
kto_201201 = pd.read_excel('./files/kto_201201.xlsx', header = 1 \
, usecols = 'A:G', skipfooter = 4)
kto_201201.head()
# kto_202101.tail()
header = 1을 설정해 줌으로써 두 번째 행에 변수명이 있음을 알려주었고, skipfooter = 4를 이용해
밑에 4줄은 생략하고 데이터를 불러왔다. tail() 함수를 이용해 데이터가 제대로 불러져왔는지 확인.
1. 데이터 전처리하기
1) 데이터 탐색
# 전체 데이터의 정보 조회
kto_201201.info()
총 67개의 로우와 7개의 컬럼(6 int, 1 object)으로 구성되어 있는 것을 알 수 있다.
# 정수형 변수의 특징을 조회
kto_201201.describe()
관광 ~ 계 모든 컬럼의 최솟값이 0인 데이터가 들어있다. 해당 데이터를 조회해보자.
# 각 컬럼 값이 0인 부분을 필터링하기 위한 조건식 작성
condition = (kto_201201['관광'] == 0) | (kto_201201['상용'] == 0) \
| (kto_201201['공용'] == 0) | (kto_201201['유학/연수'] == 0)
kto_201201[condition]
교포소계, 교포 데이터가 조건식에서 사용한 4개의 컬럼 모두 0을 가지고 있음을 알 수 있다. (교포는 통계 집계시 기타 목적으로 분류되어 있기 때문이라고 함..)
2) 데이터프레임에 새로운 컬럼(기준년월) 추가
2010년 1월 ~ 2020년 5월 월별 엑셀 파일을 사용하는 것이기 때문에, 기준년월 컬럼을 추가해 가독성을 높이자
kto_201201['기준년월'] = '2012-01'
kto_201201.head()
3) 컬럼 분리하기 (국적 -> 대륙, 국가)
# 국적 컬럼을 살펴보자
kto_201201['국적'].unique() # 중복 값 제거
국적 컬럼을 살펴보면, 대륙과 국가가 혼용되어 있는 것을 알 수 있다. 하나의 칼럼에는 하나의 특징을 가진 값들이 들어있어야 하기 때문에, 대륙 값은 제거하자.
# 대륙 목록 만들기
continents_list = ['아시아주', '미주', '구주', '대양주', '아프리카주', '기타대륙', '교포소계']
# 대륙 목록에 해당하는 값 제외
condition = (kto_201201.국적.isin(continents_list) == False)
kto_201201_country = kto_201201[condition]
kto_201201_country['국적'].unique()
# 새로 만든 데이터프레임 조회
kto_201201_country.head()
새로 만든 데이터프레임을 조회해보면 인덱스 값이 0부터 시작하지 않으므로, 인덱스 초기화를 해 주어야 한다.
kto_201201_country = kto_201201_country.reset_index(drop=True)
kto_201201_country.head()
reset_index() 함수를 사용하면 인덱스 값을 0부터 순차적으로 다시 초기화하며, drop = True 생략 시 기존 인덱스 값이 새로운 컬럼으로 생성된다.
4) 대륙 컬럼 생성
대륙 컬럼은 국적이랑 연관지어 생각할 수 있다. 이에 각 대륙별로 몇 개의 나라가 있는지 파악해보았고, 그 결과 다음과 같이 정리할 수 있었다.
| 아시아주 | 미주 | 유럽(구주) | 오세아니아(대양주) | 아프리카주 | 기타대륙 | 교포소계 |
| 25개국 | 5개국 | 23개국 | 3개국 | 2개국 | 1개국 | 1개 |
이 결과를 토대로, 대륙 컬럼의 내용은 순서대로 '아시아' 25개, '미주' 5개, '유럽' 23개, '오세아니아' 3개, '아프리카주' 2개, '기타대륙' 1개, '교포소계' 1개로 구성하자.
# 대륙 컬럼 값 만들기
continents = ['아시아'] * 25 + ['아메리카'] * 5 + ['유럽'] * 23 + ['오세아니아'] * 3 \
+ ['아프리카'] * 2 + ['기타대륙'] + ['교포']
# 대륙 컬럼 생성
kto_201201_country['대륙'] = continents
kto_201201_country.head()
# kto_201201_country.tail() -> 데이터 확인용

사용한 엑셀 파일이 대륙 순서대로 정렬되어 있었기 때문에, 위와 같이 작성하여 대입하여도 오류 없이 잘 들어갔다.
* 다만 저렇게 대입할 경우 경고가 뜨는데, .loc[row_indexer, col_indexer] = value로 바꿔서 사용해보자
5) 국적별 관광객 비율 살펴보기
데이터프레임을 살펴보면 외국인의 입국 목적은 5가지로 분류되어 있다. 한국을 방문하는 외국인 중에서 관광목적으로 입국하는 비율을 국가별로 비교해보자.
kto_201901_country['관광객비율(%)'] = \
round(kto_201901_country['관광'] / kto_201901_country['계'] * 100, 1)
kto_201901_country.head()(관광객 수 / 전체 입국객 수 * 100) 공식을 사용하여 관광객 비율을 구하고, 새로운 컬럼으로 생성하였다.

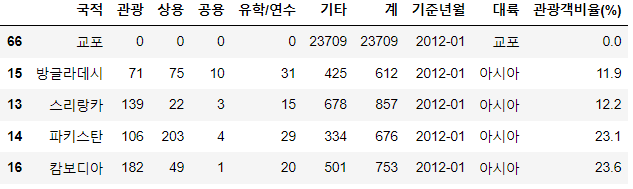
관광객 비율이 높은 국가 상위 5개와, 관광객 비율이 낮은 국가 하위 5개를 살펴보도록 하자.
kto_201201_country.sort_values(by='관광객비율(%)', ascending=False).head()
kto_201201_country.sort_values(by='관광객비율(%)', ascending=True).head()
대륙별 관광객 비율의 평균은 얼마나 되는지도 살펴본다. 이를 위해서, 피벗테이블을 만들어 집계한다.
kto_201201_country.pivot_table(values='관광객비율(%)', index='대륙', aggfunc='mean')
원래 구하려고 했던 값인 중국의 관광객 비율은 얼마나 되는지도 살펴본다.
condition = (kto_201201_country['국적'] == '중국')
kto_201201_country[condition]
마지막으로, 우리나라를 방문하는 외국인 관광객의 국적별 비율을 살펴보자. 이를 위해 우리나라를 방문하는 전체 관광객 수를 구하고, 국적별 외국인 관광객 수를 전체 관광객 수로 나눈다.
# 2012년 1월에 우리나라를 방문하는 전체 외국인 관광객 수 구하기
tourist_sum = sum(kto_201201_country['관광'])
kto_201201_country['전체비율(%)'] = \
round(kto_201201_country['관광'] / tourist_sum * 100, 1)
kto_201201_country.head()
새로 만든 전체비율 컬럼을 활용하여, 외국인 관광객 중 비율이 높은 상위 5개국을 살펴보자
kto_201201_country.sort_values('전체비율(%)', ascending=False).head()
전체 외국인 관광객 중 일본인 관광객이 42.3%로 가장 높은 비율을 차지하고 있는 것을 알 수 있다.
'AI > Data Analysis' 카테고리의 다른 글
| [Elastic Search] 데이터 검색 (0) | 2021.10.25 |
|---|---|
| [크롤링] 외국인 관광객 데이터 다루기 (2) (0) | 2021.09.07 |
| [크롤링] 2. 유튜브 랭킹 데이터 다루기 (0) | 2021.08.27 |
| [크롤링] 1. 음원 정보 수집하기 (0) | 2021.08.25 |
| HTML 태그 탐색하기 (0) | 2021.08.24 |
블로그의 정보
코딩하는 오리
Cori