[크롤링] 외국인 관광객 데이터 다루기 (2)
by Cori외국인 관광객 데이터 다루기 1편에서 수행한 데이터 분석 및 데이터 전처리의 내용을 함수화하여 간편하게 사용할 수 있도록
하고, 추가로 전처리한 데이터를 시각화 하는 방법에 대해 다룬다.
1편에서 수행한 데이터 분석 및 전처리
1. 불러올 데이터의 형태 파악
2. 엑셀 파일 파이썬으로 불러오기 (pd.read_excel())
3. 데이터 탐색 (info(), describe())
4. 기준년월 컬럼 추가
5. 국적 데이터만 남기기 (대륙 데이터 제거)
6. 대륙 컬럼 만들기
7. 국적별 관광객비율(%) 살펴보기
8. 전체 외국인 관광객 대비 국적별 관광객 비율 살펴보기
* 해당 포스팅에서 다루고 있는 모든 내용은 다음 서적을 참고하였습니다.
직장인을 위한 데이터 분석 실무 with 파이썬(개정판)(위키북스 데이터 사이언스 시리즈 63)
‘데이터 분석은 좋은 질문에서 시작합니다’이 책에서는 누구나 궁금했던 그 질문에 대해 데이터로 답해 봅니다. 이 책은 파이썬을 처음 접하는 마케팅, 영업, 기획 실무 담당자들이 파이썬을
book.naver.com
1. 데이터 작업 간편화하기
0) 함수 정의하기
-> 위 1~8번 작업을 수행하는 함수는 다음과 같이 정의할 수 있다.
def create_kto_data(yy, mm):
# 1. 불러올 엑셀 파일 경로 지정
file_path = './tours/kto_{}{}.xlsx'.format(yy, mm)
# 2. 엑셀 파일 불러오기
df = pd.read_excel(file_path, header = 1, skipfooter = 4, usecols='A:G')
# 3. '기준년월 컬럼 추가'
df['기준년월'] = '{}-{}'.format(yy, mm)
# 4. '국적' 컬럼에서 대륙 제거하고 국가만 남기기
ignore_list = ['아시아주', '미주', '구주', '대양주', '아프리카주', '기타대륙', '교포소계']
condition = (df['국적'].isin(ignore_list) == False)
df_country = df[condition].reset_index(drop=True)
# 5. '대륙' 컬럼 추가
continents = ['아시아'] * 25 + ['아메리카'] * 5 + ['유럽'] * 23 + ['오세아니아'] * 3 \
+ ['아프리카'] * 2 + ['기타대륙'] + ['교포']
df_country['대륙'] = continents
# 6. 국가별 '관광객비율(%)' 컬럼 추가
df_country['관광객비율(%)'] = round(df_country.관광 / df_country.계 * 100, 1)
# 7. '전체비율(%)' 컬럼 추가
tourist_sum = sum(df_country['관광'])
df_country['전체비율(%)'] = round(df_country['관광'] / tourist_sum * 100, 1)
# 8. 결과 출력
return(df_country)1) 여러 엑셀 파일 불러와 하나로 합치기
-> 불러올 파일명은 kto_201001.xlsx, kto_201002.xlsx, kto_201003.xlsx , ... , kto_202005.xlsx 형태
다음과 같이 작성하면, 원하는 년월 데이터를 얻을 수 있다.
# 6자리로 정렬하여 기준년월 출력하기
for yy in range(2010, 2021):
for mm in range(1, 13):
mm_str = str(mm).zfill(2) # zfill을 적용하여 10월 이전의 달들도 01, 02, ... 형태로 -
yymm = '{}{}'.format(yy, mm)zfill, rjust, ljust는 이런 문자열 연산에서 유용하게 쓰이는 함수 중 하나인데, 여기서는 다루지 않으려 한다.
이를 앞서 작성한 함수와 결합 해보자.
df = pd.DataFrame()
for yy in range(2010, 2021):
for mm in range(1, 13):
if (yy == 2020 and mm > 5):
break
tmp = create_kto_data(str(yy), str(mm).zfill(2))
df = df.append(tmp, ignore_index = True)
df.head()
정보를 출력해보자
df.info()
7500개 (125개월 * 60개의 국적)의 행이 관측되는 것을 확인할 수 있다.
해당 데이터를 엑셀로 저장하자
df.to_excel('./tours/kto_total.xlsx, index = False)2) 통합된 데이터를 국적별로 필터링하여 엑셀에 저장하기
-> 통합된 데이터가 있으면 이후 분석 과정을 수행하는데 있어 충분하지만, 경우에 따라 특성에 맞는 개별 데이터로 저장할 필요가 있다.
반복문을 통해 통합된 외국인 관광객 데이터를 국적별로 필터링하여 총 60개의 국적별 엑셀 파일로 저장해보자
# 국적 리스트 만들기
country_list = df['국적'].unique()
country_list
# 개별 국적별 관광객 데이터 저장하기
for country in country_list:
# 국적으로 필터링
condition = (df['국적'] == country)
df_filter = df[condition]
# 국적명을 반영한 파일명 만들고, 엑셀 파일로 저장하기
file_path = './tours/[국적별 관광객 데이터] {}.xlsx'.format(country)
df_filter.to_excel(file_path, index = False)2. 데이터 시각화하기
1) 시계열 그래프 그리기
-> 앞서 저장한 kto_total.xlsx 데이터를 이용하여, 전체 관광객 데이터 중 중국 국적의 관광객 수를 추출해보자
df = pd.read_excel('./tours/kto_total.xlsx')
df.head()
시각화를 위한 사전작업 수행 (한글폰트 설정)
from matplotlib import font_manager, rc
import platform
import matplotlib.pyplot as plt
if platform.system() == 'Windows':
path = 'c:\Windows\Fonts\malgun.ttf'
font_name = font_manager.FontProperties(fname=path).get_name()
rc('font', family=font_name)
elif platform.system() == 'Darwin':
rc('font',faimly='AppleGothic')
else:
print('Check your OS system')중국 국적의 데이터 필터링을 진행해보자
condition = (df['국적'] == '중국')
df_filter = df[condition]
df_filter.head()
해당 데이터를 시각화 해보자
plt.plot(df_filter['기준년월'], df_filter['관광'])
plt.show()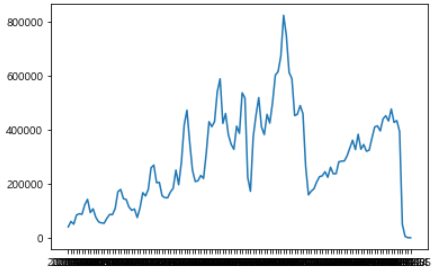
반복문을 이용해, 다양한 국적을 데이터 필터링 및 시각화를 진행해보자
country_list = ['중국', '일본', '대만', '미국']
for country in country_list:
condition = (df['국적'] == country)
df_filter = df[condition]
plt.plot(df_filter['기준년월'], df_filter['관광'])
plt.title('{} 국적의 관광객 추이'.format(country))
plt.xlabel('기준년월')
plt.ylabel('관광객수')
plt.xticks(['2010-01','2011-01','2012-01','2013-01','2014-01','2015-01',\
'2016-01','2017-01','2018-01','2019-01','2020-01'])
plt.show()



국적만 다르기 때문에, for문 내부에서 국적에 대한 정보만 변경해주며 그래프 시각화를 진행하였다.
2) 히트맵 그래프 그리기
-> 히트맵 그래프를 그릴 떄에는 X축, Y축, 그래프 내용에 어떤 변수들이 들어갈지 고민해야 한다.. 위 관광객 데이터를 히트맵으로 그리기 위해, X축에 월(Month)을, Y축에 연도(Year)을 넣고, 그래프 내용에는 관광객 숫자를 넣어보자.
. 전체 데이터 조회
df.head()
전체 데이터를 조회해보니, 년도와 월이 한 컬럼에 같이 들어있다. 히트맵을 그리기 위해, 연도와 월을 분리하자.
df['년도'] = df['기준년월'].str.slice(0, 4)
df['월'] = df['기준년월'].str.slice(5, 7)
df.head()
중국인 관광객에 대한 히트맵을 그리기 위해, 국적이 중국인 사람들을 분리해보자.
condition = (df['국적'] == '중국')
df_filter = df[condition]
df_filter.head()
피벗 테이블을 활용하여, df_filter 데이터를 매트릭스 형태로 변환해보자.
df_pivot = df_filter.pivot_table(values='관광', index='년도', columns='월')
df_pivot
이제 히트맵 그래프를 그릴 수 있다.. 히트맵 그래프는 matplotlib에서 지원하지 않고, seaborn 라이브러리를 통해 나타낼 수 있는데, seaborn 라이브러리는 matplotlib 라이브러리에 종속되기 때문에 seaborn 라이브러리를 import 할 때는 항상 matplotlib 라이브러리도 함께 import 해야 한다.
라이브러리를 import하고, 그래프를 그려보자
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize = (16, 10))
sns.heatmap(df_pivot, annot = True, fmt = '.0f', cmap = 'rocket_r')
plt.title('중국 관광객 히트맵')
plt.show()
히트맵 그래프를 통해 어느 시기에 관광객이 많은지, 적은지 한 눈에 알아볼 수 있다. 앞선 그래프 작업과 마찬가지로, 반복문을 통해 여러 국적의 히트맵을 그려보자.
for country in country_list:
condition = (df['국적'] == country)
df_filter = df[condition]
df_pivot = df_filter.pivot_table(values='관광', index='년도', columns='월')
plt.figure(figsize = (16, 10))
sns.heatmap(df_pivot, annot = True, fmt = '.0f', cmap = 'rocket_r')
plt.title('{} 관광객 히트맵'.format(country))
plt.show()



'AI > Data Analysis' 카테고리의 다른 글
| [Elastic Search] VM Workstation을 이용한 Elastic Search 사용 (1) (0) | 2021.10.26 |
|---|---|
| [Elastic Search] 데이터 검색 (0) | 2021.10.25 |
| [크롤링] 3. 외국인 관광객 데이터 다루기 (1) (0) | 2021.08.30 |
| [크롤링] 2. 유튜브 랭킹 데이터 다루기 (0) | 2021.08.27 |
| [크롤링] 1. 음원 정보 수집하기 (0) | 2021.08.25 |
블로그의 정보
코딩하는 오리
Cori