대학원 AI 면접, 필기 시험 대비 기초 지식 정리
by Cori개요
선형대수, 확률과 통계, 기본 인공지능에 관한 지식들을 정리하여 향후 면접에서나 필기 시험에 대비하기 위한 포스팅
내용 정리
Part I. 선형대수학
-> 선형대수 관련 내용은 '다크프로그래머'님의 티스토리에 정리가 상당히 잘 되어 있어, 해당 사이트를 보며 공부
Part II. 확률과 통계
-> 다음 사이트에 올라와있는 PDF를 사용해 공부
2021 수능용 확률과 통계 개념 총정리
새과정에 맞춰 정리한 2021 수능용 확률과 통계 개념 총정리 입니다. 2021 수능용 확률과 통계 개념 총정리...
blog.naver.com
Part III. 기본 인공지능
1. 인공지능 개요
1) 인공지능이란 ?
-> 기계가 사람의 지능을 모방하게 하는 기술로, 다트머스대학 수학과 교수인 '존 메카시'가 "지능이 있는 기계를 만들기
위한 과학과 공학"이란 논문에서 처음으로 제안하였다. (1955년)
이후 인공지능은 인간의 지능(인지, 추론, 학습 등)을 컴퓨터나 시스템 등으로 만든 것 또는 만들 수 있는 방법론이나 실현 가능성 등을
연구하는 기술 또는 과학을 뜻한다.
2) 튜링 테스트
· 1950년대 앨런 튜링이 제안한 인공지능 여부를 테스트하는 방법
· 테스트하는 사람이 컴퓨터 화면으로 사람과 기계와 각각 대화를 한 뒤 어느쪽이 사람인지 기계인지 구분할 수 없으면
인간수준의 사고를 가진 것으로 판명하는 방법이다.
* 1991년부터 튜링테스트를 기반으로 가장 뛰어난 챗봇에게 시상하는 뢰브너 상 제정
3) 중국어 방의 역설
· 철학자 존 설이 튜링 테스트로 기계의 인공지능 여부를 판정할 수 없다는 것을 논증하기 위해 고안한 사고 실험으로, 1980년대에 시행됨
· 안다는 것은 지능에 대한 심오한 문제로, 단순한 답변 목록조차도 진정한 지능을 가진 것처럼 보일 수 있다는 것을 보임
4) AGI, Aritificial General Intelligence
· 인간이 할 수 있는 모든 지적인 업무를 해낼 수 있는 가상적인 기계의 지능을 말하며, 인공지능 연구의 주요 목표이다.
Strong AI: AGI 성능을 가지는 인공지능
Weak AI: 기존에 인간은 쉽게 해낼 수 있었지만 컴퓨터로 처리하기 어려웠던 일을 컴퓨터가 수행할 수 있도록 하는 것이 목적으로, 지각을 가지고 있지 않으며 특정한 업무를 처리하는데 집중한다.
5) 인공지능의 발전을 가능하게 만든 세가지 요소
① 데이터의 급격한 증가
② 알고리즘의 발전
③ 컴퓨터 하드웨어의 발전 (특히 GPU, TPU)
6) 머신러닝과 딥러닝의 차이
① 머신러닝
· 데이터 학습 기반의 인공 지능 분야
· 기계에서 어떻게 동작할 지 일일이 코드로 명시하지 않고, 데이터를 이용해 학습할 수 있도록 알고리즘과 기술을 개발
② 딥러닝
· 인공지능 신경망 알고리즘을 기반으로 하는 머신러닝의 한 분야. 비정형 데이터 (영상, 음성, 텍스트)에서 뛰어난 성능을 보인다.
* 비정형 데이터란 ?
-> 정해진 규칙 없이 저장되어 값의 의미를 쉽게 파악할 수 없는 데이터로, 텍스트, 음성, 영상 데이터가 대표적인 예이다.
7) 머신러닝과 기존 프로그래밍과의 차이
① 전통적 프로그래밍
· 데이터와 프로그램 (함수, 알고리즘)을 컴퓨터에 전달하면 결과(Output) 도출
② 머신러닝
· 데이터(Input) 와 결과(Output)를 컴퓨터에 전달하면 프로그램 (알고리즘, 모델, 규칙 등) 도출
2. 머신러닝
0) 머신러닝 모델 (알고리즘, 모형)
· 머신러닝 모델이란 데이터의 패턴을 수식화 한 함수를 말하며, "이런 데이터는 이런 패턴을 가졌을 것"이라고 가정한 함수를 정한 뒤 데이터를 학습시켜 데이터의 패턴을 잘 표현하는 함수를 만든다.
1) 모델을 만드는 과정
① 모델을 정하여 수식화한다.
② 모델의 데이터를 이용해 학습시킨다. (Train, fit)
③ 학습된 모델이 얼마나 데이터 패턴을 잘 표현하는지 평가한다. (Test)

2) 데이터 관련 용어
① Feature
· 추론하기 위한 근거가 되는 값들을 표현하는 용어
· 예측하거나 분류해야 하는 데이터의 특성, 속성 값
· 입력 변수 (Input), 독립 변수
· 일반적으로 X로 표현 (Feature들이 보통 여러개이기 때문에, 집합 형태를 의미하기 위해 대문자를 사용)
② Label
· 예측하거나 분류해야 하는 값들을 표현하는 용어
· 출력 변수 (Output), 종속 변수
· 일반적으로 y로 표현 (Label은 보통 한개이기 때문에, 소문자를 사용)
③ Data Point
· 개별 데이터를 표현
④ Class
· Label의 값이 범주형 데이터일 경우 (개/고양이, 남성/여성 등) 그 구성 고유값을 의미한다.
3) 머신러닝 알고리즘 분류
① 지도학습
· 모델에게 데이터의 특징(Feature)와 정답(Label)을 알려주며 학습
· 대부분의 머신러닝이 지도학습에 해당
· 지도학습은 분류와 회귀 문제로 나뉜다.
[분류]
· 두 개 이상의 클래스에서 선택을 묻는 지도 학습 방법
· 분류 대상 클래스가 2개 일 경우 이진 분류, 분류 대상 클래스가 3개 이상일 경우 다중 분류
[회귀]
· 숫자 (연속된 값)를 예측하는 지도 학습 방법
② 비지도학습 (Unsupervised Learning)
· 정답이 없이 데이터의 특징만 학습하여 데이터간의 관계를 찾는 학습 방법
· 비지도학습의 대표적인 방법으로 군집과 차원축소가 있다.
[군집]
· 비슷한 유형의 데이터 그룹을 찾으며, 주로 데이터 경향성을 파악한다.
· K-평균 클러스터링, 평균점 이동 클러스터링, DBSCAN 방식이 있음
[차원 축소]
· 예측에 영향을 최대한 주지 않으면서 변수를 축소하는 역할을 한다.
· 고차원 데이터를 저차원의 데이터로 변환하는 비지도 학습에 해당하며, 대표적으로 주성분 분석 (PCA) 방법이 있다.
③ 강화학습
· 학습하는 시스템이 행동을 실현하고, 그 결과에 따른 보상이나 벌점을 받는 방식으로 학습한다.
· 학습이 계속되며 가장 큰 보상을 얻기 위한 최상의 전략을 스스로 학습하게 함

4) 머신러닝 개발 절차
① Business Understanding
② Data Understanding - 데이터 수집, 탐색을 통한 데이터 파악
③ Data Preparation - 데이터 전처리
④ Modeling - 머신러닝 모델 선정, 모델 학습
⑤ Evaluation - 모델 평가, 평가 결과에 따른 위 프로세스 반복
⑥ Deployment - 평가 결과가 좋으면 실제 업무에 적용
5) 사이킷런 (scikit-learn)
· 머신러닝 관련 다양한 알고리즘을 제공하며, 모든 알고리즘에 일관성 있는 사용법을 제공해 보편적으로 사용된다.
① Transformer (변환기)
· 데이터 전처리를 하는 클래스로, LabelEncoder, MinMaxScaler등이 있다.
· 데이터 셋의 값의 형태를 변환
· fit(): 어떻게 변환할 지 학습하는 함수
· transform(): 변환 처리하는 함수
· fit_transform(): fit()과 transform()을 같이 처리하는 함수
② Estimator (추정기)
· 데이터를 학습하고 예측하는 알고리즘(모델)들을 구현한 클래스로, DecisionTreeClassifier, LinearRegression등이 있다.
· fit(): 데이터를 학습하는 함수
· predict(): 데이터를 예측하는 함수

6) 데이터셋
① Train Dataset (훈련/학습 데이터셋)
② Validation Dataset (검증 데이터셋)
③ Test Dataset (평가 데이터셋)
* Test Dataset은 마지막에 모델의 성능을 측정하는 용도로 딱 한 번만 사용된다. (Train Dataset과 Validation Dataset로 모델을 최적화한 뒤 마지막에 Test Dataset으로 최종 평가)
7) 데이터 전처리에 주로 사용되는 기법
· 데이터 분리(검증) 방식
① Hold out 방식
② K-Fold Cross Validation 방식
③ StratifiedKold 방식
* cross_val_score()
-> 데이터셋을 K개로 나누고 K번 반복하면서 평가하는 작업을 처리해주는 함수

· 범주형 데이터 전처리
-> scikit-learn 머신러닝 API들은 Feature나 Label의 값들이 숫자(정수/실수)인 것만 처리 가능
① Label Encoding
· 문자열(범주형) 값을 오름차순 정렬 후 0부터 1씩 증가하는 값으로 변환

* 숫자의 차이가 모델에 영향을 주지 않는 트리 계열 모델 (의사결정나무, 랜덤포레스트)에 적용한다.
② One-Hot Encoding
· N개의 클래스를 N차원의 One-Hot 벡터로 표현되도록 변환 (고유값들을 컬럼으로 만들고 정답에 해당하는 열은 1, 나머지는 0으로 표현)

* 숫자의 차이가 모델에 영향을 미치는 선형 계열 모델 (로지스틱 회귀, SVM, 신경망)에서 범주형 데이터 변환 시에 적용한다.
· 표준화
-> Feature의 값들이 평균: 0, 표준편차: 1인 범위 (표준정규분포)에 있도록 변환
① StandardScaler

* SVM, 선형회귀, 로지스틱 회귀 알고리즘 (선형모델)은 데이터셋이 표준정규분포를 따를 때 성능이 좋다.
② MinMaxScaler
· 데이터셋의 모든 값을 0(Min Value)과 1(Max Value) 사이의 값으로 변환

* StandardSacler와 MinMaxScaler 중 어느것이 더 좋고 나쁜지는 판단할 수 x, 번갈아가며 돌려보고 판단
8) 분류 평가 지표
① 정확도 (Accuracy)
② 정밀도 (Precision)
③ 재현률 (Recall)
④ F1점수 (F1 Score)
⑤ PR Curve, AP
⑥ ROC, AUC
양성과 음성
· 양성 - 모델이 찾으려는 주 대상
· 음성 - 모델이 찾으려는 주 대상이 아닌 것
ex) 스팸메일 분류: 스팸메일 = 양성, 일반메일 = 음성
금융사기 모델: 사기거래 = 양성, 정상거래 = 음성
혼동 행렬
· 실제 값과 예측한 것을 표로 만든 평가표로, 분류의 예측 결과가 몇 개나 맞고 틀렸는지 확인할 때 사용

· TP (True Positive) - 양성으로 예측했는데 맞은 개수
· TN (True Negative) - 음성으로 예측했는데 맞은 개수
· FP (False Positive) - 양성으로 예측했는데 틀린 개수
· FN (False Negative) - 음성으로 예측했는데 틀린 개수
* 정확도, 정밀도, 재현율/민감도, F1 Score
· 정확도: 전체 데이터 중 맞게 예측한 것의 비율
· 정밀도(Precision) : Positive(양성)으로 예측한 것 중 실제 양성인 것의 비율
· 재현율/민감도(Recall/Sensitivity): 실제 Positive(양성)인 것 중 Positive(양성)으로 예측한 것의 비율

재현율과 정밀도의 관계
· 재현율이 더 중요한 경우
-> 실제 Positive 데이터를 Negative 데이터로 잘못 판단하면 업무상 큰 영향이 있는 경우로, 암환자 판정 모델이 대표적이다.
· 정밀도가 더 중요한 경우
-> 실제 Negative 데이터를 Positive 데이터로 잘못 판단하면 업무상 큰 영향이 있는 경우로, 스팸메일 판정 모델이 대표적이다.
* 임계값(Threshold) 변경을 통해 재현율과 정밀도를 변환하며, 이를 위해 Binarizer를 사용한다.
· 임계값이란 ?
-> 모델이 분류 Label을 결정할 때 기준이 되는 확률 기준값
Positive일 확률이 임계값 이상이면 Positive, 이하이면 Negative으로 예측한다.

* 임계값을 높이면 양성으로 예측하는 기준을 높임 -> 음성으로 예측되는 샘플이 많아짐 (정밀도 ↗, 재현율 ↘)
임게값을 낮추면 양성으로 예측하는 기준을 낮춤 -> 양성으로 예측되는 샘플이 많아짐 (정밀도 ↘, 재현율 ↗)
PR Curve (Precision Recall Curve, AP Score (Average Precision Score)
· Positive 확률 0~1사이의 모든 임계값에 대해 재현율(recall)과 정밀도(precision)의 변화를 이용한 평가 지표
· X축에 재현율, Y축에 정밀도를 놓고 임계값이 1->0으로 변화할 때 두 값의 변화를 선 그래프로 그린다.
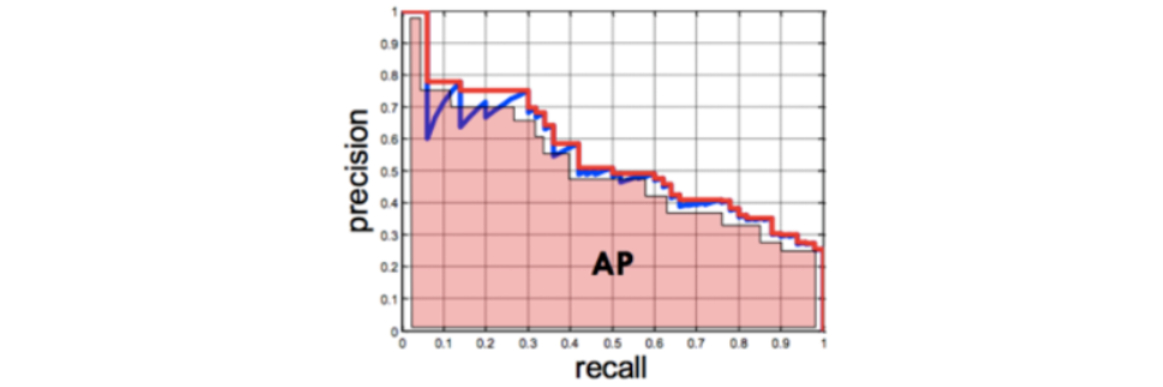
· AP Score는 PR Curve의 성능 평가 지표를 하나의 점수로 평가한 값으로, PR Curve 선 아래 면적을 계산한 값 (높을수록 좋음)
ROC Curve (Receiver Operation Characteristic Curve)와 AUC Score (Area Under the Curve Score)
· 이진 분류 모델의 성능 평가 지표 중 하나로, 불균형 데이터셋을 평가할 때 사용한다.
· FPR (False Positive Rate)을 X축, TPR(True Positive Rate)을 Y축으로 놓고 임계값을 변경하여 FPR이 변할 때 TPR의 변화를 표현

· AUC Score는 ROC 곡선 아래쪽 면적으로, 0~1 사이로 값이 나온다. 값이 클수록 좋음
* 가장 완벽한 모델은 FPR이 0이고 TPR이 1인 것이며, 일반적으로 FPR이 작을 때 TPR이 높는 경우가 좋다고 할 수 있다.
9) 회귀 평가 방법
① MSE (Mean Sqaured Error)
② RMSE (Root Mean Squared Error)
③ R^2 (결정계수)
* 결정계수란 ?
-> 모델이 어떤 값을 예측했을 때, 평균으로 예측할 때보다 얼마나 더 잘 예측했는지 본다.
10) 머신러닝 모델 종류
① SVM (Support Vector Machine), 분류 모델
· 하나의 분류 그룹을 다른 그룹과 분리하는 최적의 경계를 찾아내는 알고리즘으로, 딥러닝 이전에 분류에서 뛰어난 성능을 보인 모델
· 비선형 데이터셋에 SVM을 적용하기 위해 커널 서포트 벡터 머신 등장
② 의사결정 트리 (DecisionTree)
③ 랜덤포레스트 (RandomForest)
④ 앙상블 (Ensemble)
⑤ 최근접이웃 (KNN)
⑥ 군집 (Clustering)
3. 딥러닝
0) 딥러닝의 특징
① 전통적 기계학습 (Machine Learning) Process
· 사람이 수작업으로 특징을 추출하고, 이렇게 추출한 특징 벡터를 분류기에 전달하여 결과 판단

② 딥러닝 (Deep Learning) Process
· 특징 추출과 분류 모두 기계가 수행
· 처음부터 끝까지 기계가 다 수행하기 때문에, End to End 방식이라고도 함

1) 딥러닝으로 할 수 있는 일
① 분류
② 회귀
③ 물체 검출 (object detection)
④ 기계번역
⑤ 예술적 창조 (GAN)
⑥ 강화 학습 (Reinforcement Learning)
2) 딥러닝 프로세스
① 학습 단계

② 추론 단계

3) DNN (Deep Neural Network) 신경망 구성 요소
① Layer(층): Network를 구성하는 Layer
② Loss Function(손실함수): 가중치를 어떻게 업데이트 할 지 예측 결과와 Ground Truth (실제 결과) 사이의 차이를 정의
③ Optimizer: 가중치를 업데이트하여 모델의 성능을 최적화
④ Unit, Node, Neuron: Tensor를 입력으로 받아 처리 후 Tensor를 출력하는 데이터 처리 모듈 (Input -> Output)
-> 입력 값에 weight(가중치)를 곱하고, bias(편향)을 더한 결과를 Activation Function(활성화함수)에 넣어 최종 결과를 출력한다.
⑤ Activation Function: 선형결합한 결과를 비선형화 시키는 목적으로 사용
4) Layer(층)
① Input Layer
· 입력값들을 받아 Hidden Layer에 전달하는 노드들로 구성된 Layer
② Hidden Layer
· Input Layer와 Output Layer 사이에 존재하는 Layer
③ Output Layer
· 예측결과를 출력하는 노드들로 구성된 Layer
* 대부분 Layer들은 학습을 통해 최적화할 Parameter를 가지며, Dropout, Pooling Layer와 같이 Parameter가 없는 Layer도 존재
목적, 구현 방식에 따른 Layer
① Fully Connected Layer (Dense Layer)
-> 추론 단계에서 주로 사용하는 Layer
② Convolution Layer
-> 이미지 Feature Extraction으로 주로 사용하는 Layer
③ Recurrent Layer
-> Sequential (순차)데이터의 Feature Extraction으로 주로 사용하는 Layer
④ Embedding Layer
-> Text 데이터의 Feature Extraction으로 주로 사용하는 Layer
5) 모델 (Network)
· Layer를 연결한 것이 Deep Learning 모델이다.
· 이전 레이어의 출력을 Input으로 받아 처리 후 Output으로 출력하는 레이어들을 연결

6) 활성 함수 (Activation Function)
· 각 유닛이 입력과 Weight 간에 가중합을 구한 뒤 출력 결과를 만들기 위해 거치는 함수
· 같은 층 (layer)의 모든 유닛들은 같은 활성 함수를 가짐
· 출력 레이어의 경우 출력하려는 문제에 맞춰 나오도록 하는 함수를 사용한다.
· 은닉층 (Hidden Layer)의 경우 비선형성을 주는 것을 목적으로 하기 때문에, RELU 함수를 주로 사용한다.
활성함수 종류
① Sigmoid (Logistic Function)

· 출력값의 범위: 0~1
· 초기 딥러닝의 Hidden Layer의 활성함수로 Sigmoid가 많이 사용되었지만, 층을 깊게 쌓을 경우 기울기 소실 문제가 발생하여 학습 x
· 함수값의 중심이 0이 아니어서 학습이 느려지는 단점이 있음 (X = 0 -> Y = 0.5)
· Binary Classifier (이진 분류)를 위한 네트워크의 Output Layer (출력층)의 활성함수로 사용됨 (은닉층에서는 거의 사용 x)
* 기울기 소실 (Gradient Vanishing) 문제란 ?
-> 최적화(Optimize) 과정에서 Gradient가 0인 값과 밑단층 (Bottom Layer)의 가중치들이 학습되지 않는 현상
② Hyperbolic Tangent

· 출력값의 범위: -1~1
· Output이 0을 중심으로 분포하므로 Sigmoid보다 학습에 효율적이다.
· 기울기 소실 문제 발생
③ ReLU (Rectified Linear Unit)

· 기울기 소실 문제를 어느정도 해결한 활성함수
· 0 이하의 값 (z <= 0)들에 대해 뉴런이 죽는 단점이 있다. (Dying ReLU)
④ Learky ReLU

· ReLU의 dying ReLU 현상을 해결하기 위해 나온 함수
· 음수 z를 0으로 반환하지 않고, alpha (0~1사이 실수)를 곱해 반환한다.

⑤ Softmax
· Multi-Class Classification(다중 분류)를 위한 네트워크의 Output Layer(출력층)의 활성화 함수로 주로 사용됨 (은닉층에 사용 x)
· Layer의 Unit들의 출력 값들을 정규화하여 각 Class에 대한 확률값으로 변환한다.
· 출력 노드들의 값은 0~1 사이의 실수로 변환되고, 그 값들의 총합 = 1
7) Loss Function (손실 함수)
· 모델이 출력한 예측값과 실제 데이터의 차이를 계산하는 함수
· 네트워크 모델을 훈련하는 동안, Loss 함수가 계산한 Loss값 (손실)이 최소화 되도록 파라미터 (가중치, 편향)을 업데이트한다.
· 네트워크 모델이 해결하려는 문제의 종류에 따라 표준적인 Loss Function 존재
문제 별 Loss Function
① Binary Classification (이진분류)
· binary_crossentropy를 Loss Function으로 사용

② Multi-class Classification (다중분류)
· categorical_crossentropy를 Loss Function으로 사용
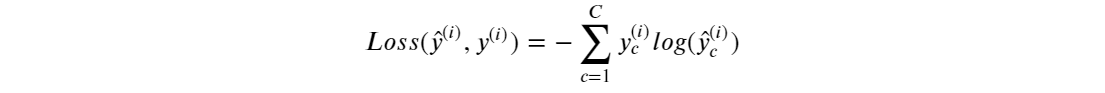
③ Regression (회귀)
· Mean Squared Error를 Loss Function으로 사용

* 문제 별 Output Layer Activation Function, Loss Function

8) Optimizer (최적화 방법)
· 학습 시 모델 네트워크의 파라미터들을 데이터에 맞춰 최적화하는 알고리즘
· 딥러닝은 경사하강법 (Gradient Descent)과 오차역전파 (Back Propagation) 알고리즘을 기반으로 파라미터들을 최적화
① 경사하강법 (Gradient Descent)
· 최적화를 위해 파라미터들에 대한 Loss Function의 Grdaient 값을 구해, Gradient의 반대 방향으로 일정 크기만큼 파라미터들을
업데이트하는 방법

② 오차역전파 (Back Propagation)
· 딥러닝 학습 시 파라미터를 최적화 할 때 추론한 역방향으로 Loss를 전달하며 단계적으로 파라미터들을 업데이트하는 방법
· 뒤에서부터 한단계씩 미분해 Gradient 값을 구하고, 이를 연쇄법칙에 의해 곱해가며 파라미터를 최적화한다.
· 추론의 경우 입력에서 출력 방향으로 계산하며, 이 경우에는 순전파라고 한다.
* 오차역전파를 이해하기 위해 계산 그래프를 사용함
9) 파라미터 업데이트 단위
① Batch Gradient Descent (배치 경사하강법)
· Loss를 계산할 때 전체 학습 데이터를 사용해 그 평균값을 기반으로 파라미터 최적화
· 많은 계산량이 필요해서 속도가 느리며, 학습데이터가 클 경우 메모리가 부족할 수 있다.
② Mini Batch Stochastic Gradient Descent (미니배치 확률적 경사하강법)
· Loss를 계산할 때 전체 데이터를 다 사용하지 않고 지정한 데이터 양 (batch size)만큼 계산해 파라미터를 업데이트한다.
· 계산은 빠르지만, 최적값을 찾아가는 방향이 불안정하여 부정화.
* Step : 한번에 파라미터를 업데이트하는 단위

SGD를 기반으로 한 주요 옵티마이저
① 방향성을 개선한 최적화 방법 - Momentum, NAG
② 학습률을 개선한 최적화 방법 - Adagrad, RMSProp
③ 방향성 + 학습률을 개선한 최적화 방법 - Adam

10) Overfitting, Underfitting
[Dropout Layer 추가를 통한 Overfitting 규제]
11) Batch Normalization (배치정규화)
· 각 Layer에서 출력된 값을 평균=0, 표준편차=1로 정규화하여 각 Layer들의 입력분포를 균일하게 만들어준다.
· Internal Covariate Shift(내부 공변량 변화) 문제를 해결하기 위해 사용한다.
· 입력 데이터와 파라미터의 가중합을 구한 결과에 Batch Normalization을 적용한 뒤, 그 결과를 Activation 함수에 전달

Internal Covariate Shift 문제

· 학습 과정에서 각 층을 통과할 때마다 입력 데이터 분포가 달라지는 현상
· 입력 데이터의 분포가 정규분포를 따르더라도 레이어를 통과하면서 성능이 떨어지는 문제가 발생한다.
· 각 Layer를 통과할 때마다 분포를 정규분포로 정규화하여 성능을 올림
Batch Normalization 효과
· 랜덤하게 생성되는 초기 가중치에 대한 영향력을 줄일 수 있음
· 학습하는 동안 과대적합에 대한 규제의 효과를 줌
· Gradient Vanishing, Gradient Exploding 효과를 막아줌
12) 파라미터 vs 하이퍼파라미터
① Parameter
· 모델이 학습하여 데이터에 가장 적합한 값을 찾아내는 파라미터
· Weights W
· Bias b
② Hyper Parameter
· 모형의 구조를 결정하거나 Optimization 방법을 결정하는 변수들로, 개발자가 직접 설정하는 파라미터
· Optimizer 종류
· Learning Rate
· Hidden Layer의 수
· Hidden Unit의 수
· Iteration의 수
· Activation Function의 종류
· Minibatch Size
· Regularization
· Dropout Rate 등
13) CNN (Convolution Neural Network)
· 이미지로부터 부분적 특성을 추출하는 Feature Extraction 부분과, 분류를 위한 Classification 부분으로 나눈다.
· Feature Extraction 부분에 이미지 특징 추출에 성능이 좋은 Convolution Layer 사용

* Feature Extraction: Convolution Layer, 추론: Dense Layer (Fully Connected Layer) 등
Feature Extractor에 Dense Layer를 사용했을 경우 문제점 - 기존 MLP
① Dense Layer (Fully Connected Layer)는 이미지의 공간적 구조를 학습하는 것이 어렵다.
· 같은 형태가 전체 이미지에서 위치가 바뀌었을 때, 다른 값으로 인식하게 됨
② 이미지를 Input으로 사용할 경우 weight의 양이 매우 크다.
· weight가 많다는 것은 학습 대상이 많은 것이기 때문에, 학습하기 그만큼 어려워진다.
Convolution Layer Parameter 개수 구하기
(filter height * filter width * channel) * filter 개수 + filter 개수 (bias)
'AI' 카테고리의 다른 글
| LLM 모델 메모리 사용량 계산하는 방법 (2) | 2024.12.16 |
|---|---|
| Vector DB - Milvus (0) | 2024.07.26 |
| Vector DB 선택하기 (0) | 2024.07.22 |
| Llama Index 살펴보기 (0) | 2024.03.11 |
| DNN(Deep Neural Networks) 성능 개선 (0) | 2021.12.06 |
블로그의 정보
코딩하는 오리
Cori