Enhancing Global Understanding
by Cori해당 포스트는 Medium 'Florian June'이 작성한 Advanced RAG 포스트 시리즈 그 열두번째 내용을 정리하며, 문서나 코퍼스의 전반적인 이해를 향상시키기 위한 네 가지 혁신적인 방법과 여기서 얻은 통찰과 생각에 대해 다루고 있다.
과학 문헌 검토, 법률 사례 요약 등 중요한 실제 작업은 여러 청크나 문서에 걸쳐 지식을 이해해야 한다.
기존 RAG 방법은 각 청크를 독립적으로 인코딩하기 때문에 청크 경계를 넘어선 정보 이해를 요구하는 작업을 LLM이 수행하는 데 도움이 되지 않는다. 여기서는 문서나 코퍼스의 전반적인 이해를 향상시키기 위한 네 가지 방법은 다음과 같다.
Method 1. RAPTOR: 트리 기반 검색 시스템으로 텍스트 청크를 재귀적으로 임베딩, 클러스터링, 요약한다.
Method 2. Graph RAG: 지식 그래프 생성, 커뮤니티 감지, RAG, 쿼리 집중 요약(QFS)을 결합하여 전체 텍스트 코퍼스의 포괄적인 이해를 돕는다.
Method 3. HippoRAG: 인간의 장기 기억의 해마 인덱싱 이론에서 영감을 얻은 검색 프레임워크로, LLM, 지식 그래프, 개인화된 페이지랭크 알고리즘과 협력한다.
Method 4. spRAG: AutoContext 및 관련 세그먼트 추출(RSE)이라는 두 가지 핵심 기술을 통해 표준 RAG 시스템의 성능을 향상시킨다.
RAPTOR, Recursive Abstractive Processing for Tree-Organized Retrieval
RAPTOR는 텍스트 세그먼트를 재귀적으로 임베딩, 클러스터링, 요약하는 데 설계된 새로운 트리 기반 검색 시스템으로, 하향식으로 트리를 구성하여 다양한 수준의 요약을 제공한다. 추론 과정에서 RAPTOR는 해당 트리에서 정보를 검색하며, 다양한 추상화 수준에서 더 긴 문서의 데이터를 통합한다.
Key Idea
RAPTOR는 텍스트 청크를 임베딩 기반 클러스터로 구성하는 재귀적 방법을 사용하며, 각 클러스터에 대한 요약을 생성하여 하향식으로 트리를 구성한다.

Constructing a RAPTOR Tree
Text Chunking
검색 코퍼스를 각 100토큰의 연속적인 청크로 나눕니다. 청크가 100토큰을 초과할 경우, RAPTOR는 문맥적 및 의미적 일관성을 유지하기 위해 전체 문장을 다음 청크로 이동시킨다.
def split_text(
text: str, tokenizer: tiktoken.get_encoding("cl100k_base"), max_tokens: int, overlap: int = 0
):
"""
Splits the input text into smaller chunks based on the tokenizer and maximum allowed tokens.
Args:
text (str): The text to be split.
tokenizer (CustomTokenizer): The tokenizer to be used for splitting the text.
max_tokens (int): The maximum allowed tokens.
overlap (int, optional): The number of overlapping tokens between chunks. Defaults to 0.
Returns:
List[str]: A list of text chunks.
"""
...
...
# If adding the sentence to the current chunk exceeds the max tokens, start a new chunk
elif current_length + token_count > max_tokens:
chunks.append(" ".join(current_chunk))
current_chunk = current_chunk[-overlap:] if overlap > 0 else []
current_length = sum(n_tokens[max(0, len(current_chunk) - overlap):len(current_chunk)])
current_chunk.append(sentence)
current_length += token_count
...
...Embedding
Sentence-BERT를 사용하여 이러한 청크의 밀집 벡터 표현을 생성하며, 이 청크들은 해당 임베딩과 함께 RAPTOR 트리 구조의 리프 노드를 구성한다.
class TreeBuilder:
"""
The TreeBuilder class is responsible for building a hierarchical text abstraction
structure, known as a "tree," using summarization models and
embedding models.
"""
...
...
def build_from_text(self, text: str, use_multithreading: bool = True) -> Tree:
"""Builds a golden tree from the input text, optionally using multithreading.
Args:
text (str): The input text.
use_multithreading (bool, optional): Whether to use multithreading when creating leaf nodes.
Default: True.
Returns:
Tree: The golden tree structure.
"""
chunks = split_text(text, self.tokenizer, self.max_tokens)
logging.info("Creating Leaf Nodes")
if use_multithreading:
leaf_nodes = self.multithreaded_create_leaf_nodes(chunks)
else:
leaf_nodes = {}
for index, text in enumerate(chunks):
__, node = self.create_node(index, text)
leaf_nodes[index] = node
layer_to_nodes = {0: list(leaf_nodes.values())}
logging.info(f"Created {len(leaf_nodes)} Leaf Embeddings")
...
...Clustering method
클러스터링은 RAPTOR 트리를 구성하는 데 중요한 역할을 하며, 텍스트 단락을 일관된 그룹으로 정리한다. 이는 관련된 콘텐츠를 함께 모아 후속 검색 프로세스를 향상시킨다. RAPTOR의 클러스터링 방법은 다음과 같은 특징이 있다:
Feature 1. 소프트 클러스터링을 위해 Gaussian 혼합 모델(GMM)과 UMAP 차원 축소를 사용한다.
Feature 2. UMAP 매개변수를 조정하여 전역 및 지역 클러스터를 식별할 수 있다.
Feature 3. 최적의 클러스터 수를 결정하기 위해 베이지안 정보 기준(BIC)을 사용한다.
이 클러스터링 방법의 핵심은 하나의 노드가 여러 클러스터에 속할 수 있다는 것이다. 이는 단일 텍스트 세그먼트가 다양한 주제에 대한 정보를 포함할 수 있음을 고려하여 여러 요약에 포함되도록 한다. GMM을 사용하여 노드를 클러스터링한 후, 각 클러스터 내의 노드는 LLM에 의해 요약된다. 이 과정은 큰 청크를 선택된 노드의 간결하고 일관된 요약으로 변환하며, 관련 프롬프트는 다음과 같다.

Construction Algorithm
전체 트리의 리프 노드(끝 노드)를 얻고, 클러스터링 알고리즘을 결정했다. 위 그림의 Formation of one tree layer 부분에서 보이는 것 같이, 함께 그룹화된 노드들은 형제 노드를 형성하며, 부모 노드는 해당 특정 클러스터의 요약을 포함한다. 생성된 요약은 트리의 비리프 노드들로 구성된다. 요약된 노드들은 다시 임베딩(재삽입)되며, 임베딩, 클러스터링, 요약의 과정은 더 이상 클러스터링이 불가능해질 때까지 계속된다. 이로 인해 원본 문서들의 구조화된 다계층 트리 표현이 생성된다.
class ClusterTreeConfig(TreeBuilderConfig):
...
...
def construct_tree(
self,
current_level_nodes: Dict[int, Node],
all_tree_nodes: Dict[int, Node],
layer_to_nodes: Dict[int, List[Node]],
use_multithreading: bool = False,
) -> Dict[int, Node]:
...
...
for layer in range(self.num_layers):
new_level_nodes = {}
logging.info(f"Constructing Layer {layer}")
node_list_current_layer = get_node_list(current_level_nodes)
if len(node_list_current_layer) <= self.reduction_dimension + 1:
self.num_layers = layer
logging.info(
f"Stopping Layer construction: Cannot Create More Layers. Total Layers in tree: {layer}"
)
break
clusters = self.clustering_algorithm.perform_clustering(
node_list_current_layer,
self.cluster_embedding_model,
reduction_dimension=self.reduction_dimension,
**self.clustering_params,
)
lock = Lock()
summarization_length = self.summarization_length
logging.info(f"Summarization Length: {summarization_length}")
...
...Retrieval Processes
RAPTOR 트리를 생성한 후, 쿼리에 활용하는 방법으로는 두 가지 방법이 있다: 트리 탐색을 기반으로 하는 방법과 축소된 트리를 기반으로 하는 방법이 있으며, 이는 다음과 같다.

트리 탐색은 트리의 루트 레벨에서 시작하여 쿼리 벡터와의 코사인 유사도를 기준으로 상위 k개의 노드(이 경우 상위 1개)를 검색한다. 각 레벨에서는 이전 레벨의 상위 k개 노드의 자식 노드들 중에서 상위 k개 노드를 검색한다.
class TreeRetriever(BaseRetriever):
...
...
def retrieve_information(
self, current_nodes: List[Node], query: str, num_layers: int
) -> str:
"""
Retrieves the most relevant information from the tree based on the query.
Args:
current_nodes (List[Node]): A List of the current nodes.
query (str): The query text.
num_layers (int): The number of layers to traverse.
Returns:
str: The context created using the most relevant nodes.
"""
query_embedding = self.create_embedding(query)
selected_nodes = []
node_list = current_nodes
for layer in range(num_layers):
embeddings = get_embeddings(node_list, self.context_embedding_model)
distances = distances_from_embeddings(query_embedding, embeddings)
indices = indices_of_nearest_neighbors_from_distances(distances)
if self.selection_mode == "threshold":
best_indices = [
index for index in indices if distances[index] > self.threshold
]
elif self.selection_mode == "top_k":
best_indices = indices[: self.top_k]
nodes_to_add = [node_list[idx] for idx in best_indices]
selected_nodes.extend(nodes_to_add)
if layer != num_layers - 1:
child_nodes = []
for index in best_indices:
child_nodes.extend(node_list[index].children)
# take the unique values
child_nodes = list(dict.fromkeys(child_nodes))
node_list = [self.tree.all_nodes[i] for i in child_nodes]
context = get_text(selected_nodes)
return selected_nodes, context반면 축소된 트리는 트리를 단일 레이어로 압축하고, 쿼리 벡터와의 코사인 유사도를 기준으로 토큰의 수가 임계값에 도달할 때까지 노드를 검색한다.
class TreeRetriever(BaseRetriever):
...
...
def retrieve_information_collapse_tree(self, query: str, top_k: int, max_tokens: int) -> str:
"""
Retrieves the most relevant information from the tree based on the query.
Args:
query (str): The query text.
max_tokens (int): The maximum number of tokens.
Returns:
str: The context created using the most relevant nodes.
"""
query_embedding = self.create_embedding(query)
selected_nodes = []
node_list = get_node_list(self.tree.all_nodes)
embeddings = get_embeddings(node_list, self.context_embedding_model)
distances = distances_from_embeddings(query_embedding, embeddings)
indices = indices_of_nearest_neighbors_from_distances(distances)
total_tokens = 0
for idx in indices[:top_k]:
node = node_list[idx]
node_tokens = len(self.tokenizer.encode(node.text))
if total_tokens + node_tokens > max_tokens:
break
selected_nodes.append(node)
total_tokens += node_tokens
context = get_text(selected_nodes)
return selected_nodes, contextRAPTOR는 다음 그림과 같이 2가지 방법에 대한 성능 비교를 진행하였다. 2000개의 토큰을 가진 축소된 트리가 가장 좋은 결과를 제공하는 것을 볼 수 있으며, 이는 트리 탐색보다 더 많은 유연성을 제공하기 때문이다(모든 노드를 동시에 검색함으로써 주어진 문제에 적합한 세부 수준에서 정보 검색).
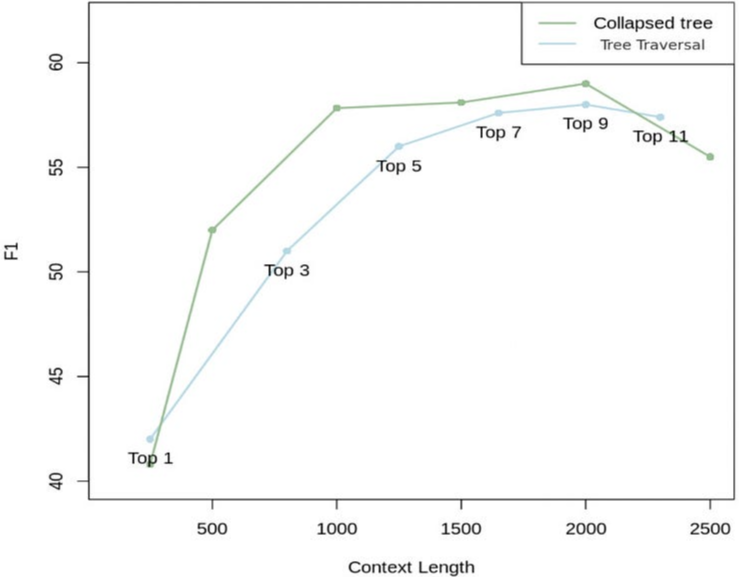
그림 5는 신데렐라 이야기와 관련된 두 가지 쿼리에 대해 RAPTOR가 정보를 어떻게 검색하는지를 보여줍니다: "이야기의 중심 주제는 무엇인가요?"와 "신데렐라는 어떻게 행복한 결말을 맞이했나요?

강조된 노드는 RAPTOR의 선택을 나타내며, 화살표는 DPR(밀집 패시지 검색)의 리프 노드를 가리킨다. 중요한 점은, RAPTOR가 제공하는 문맥이 종종 DPR에 의해 검색된 정보를 직접적으로 또는 상위 레이어 요약 내에서 포함하고 있다는 것이다.
Graph RAG
Graph RAG는 LLM을 사용하여 두 단계로 구성된 그래프 기반 텍스트 인덱스를 생성한다:
Step 1. 소스 문서들로부터 지식 그래프를 도출한다.
Step 2. 밀접하게 연결된 엔티티 그룹들에 대한 커뮤니티 요약을 생성한다.
쿼리가 주어지면, 각 커뮤니티 요약은 부분적인 응답에 기여하며 이러한 부분적인 응답들은 최종적인 global answer를 형성하기 위해 집계된다.
Graph RAG의 파이프라인은 다음과 같다. 보라색 상자는 인덱싱 작업을 나타내고, 녹색 상자는 쿼리 작업을 나타낸다.

Graph RAG는 데이터셋의 도메인에 특정한 대형 언어 모델(LLM) 프롬프트를 사용하여 노드(예: 엔티티), 엣지(예: 관계), 공변량(예: 주장)을 감지, 추출 및 요약한다. 커뮤니티 검출은 그래프를 요소(노드, 엣지, 공변량) 그룹으로 나누는 데 사용되며, LLM은 인덱싱과 쿼리 시점 모두에서 이를 요약할 수 있다. 특정 쿼리에 대한 전역 답변은 해당 쿼리와 관련된 모든 커뮤니티 요약에 대해 쿼리 중심의 최종 요약 라운드를 수행함으로써 생성된다. 현재 Graph RAG는 오픈 소스가 아니다.
Step 1: Source Documents → Text Chunks
청크 크기의 균형 문제는 RAG에 있어 오랜 과제이며, 청크가 너무 길면 LLM 호출 횟수가 줄어든다. 그러나 컨텍스트 윈도우의 제약으로 인해 많은 양의 정보를 완전히 이해하고 관리하는 것이 어려워지며, 이는 recall 값 감소로 이어질 수 있다.
다음 그림에서, HotPotQA 데이터세트에 대해 600 토큰 크기의 청크는 2400 토큰 크기의 청크에 비해 두 배 많은 효과적인 엔티티를 추출하는 것을 볼 수 있다.

Step 2: Text Chunks → Element Instances (Entities and Relationships)
이 방법은 각 청크에서 엔티티와 그 관계를 추출하여 지식 그래프를 구성하며, 이는 대형 언어 모델(LLM)과 프롬프트 엔지니어링을 결합하여 이루어진다. 동시에 Graph RAG는 다단계 반복 과정을 사용하는데, 이 과정에서는 LLM이 모든 엔티티가 추출되었는지 여부를 이진 분류 문제와 유사하게 판단해야 한다.
Step 3: Element Instances → Element Summaries → Graph Communities → Community Summaries
이전 단계에서 엔티티, 관계, 주장을 추출하는 것은 실제로 추상적 요약의 한 형태이다. 그러나 Graph RAG는 이것이 충분하지 않으며, 이러한 '요소'들을 LLM을 사용하여 추가적으로 요약해야 한다고 생각한다.
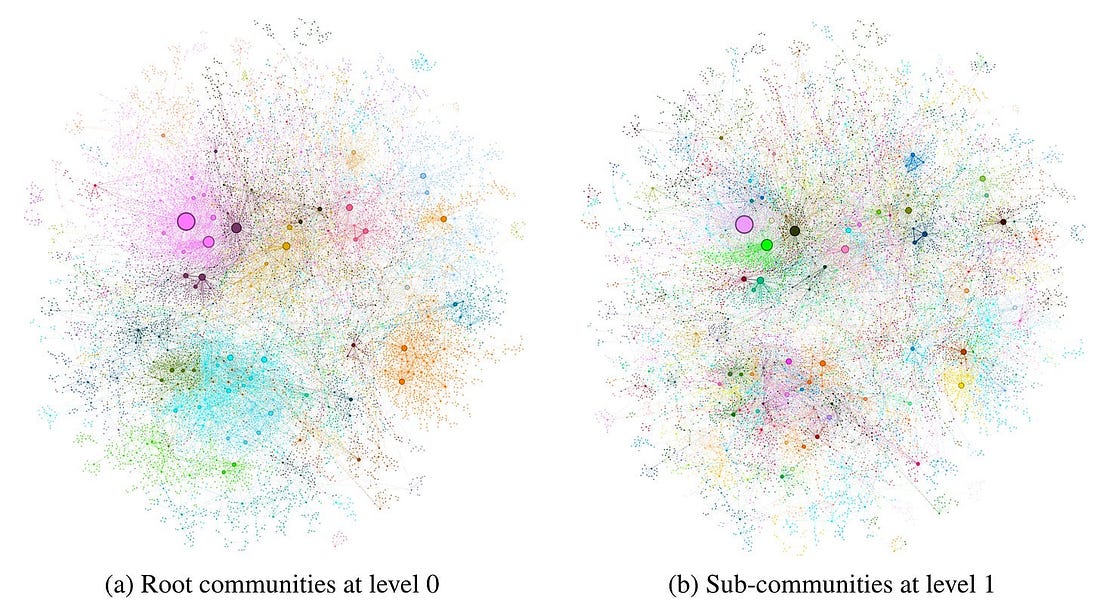
Graph RAG는 그래프 내의 커뮤니티 구조를 식별하기 위해 커뮤니티 탐지 알고리즘을 사용하며, 긴밀하게 연결된 엔티티를 동일한 커뮤니티에 포함시킨다. 위 그림은 Leiden 알고리즘을 사용하여 MultiHop-RAG 데이터셋에서 식별된 그래프 커뮤니티를 보여준다. 이 시나리오에서는 LLM이 추출 중에 엔티티의 모든 변형을 일관되게 식별하지 못하더라도, 커뮤니티 탐지는 이러한 변형 간의 연결을 설정하는 데 도움이 될 수 있다. 일단 커뮤니티로 그룹화되면, 이러한 변형이 동일한 엔티티 의미를 나타내며, 단지 다른 표현이나 동의어로 되어 있음을 의미한다. 이는 지식 그래프 분야의 엔티티 중의성 해결과 유사하다.

커뮤니티를 식별한 후, Leiden 계층 내의 각 커뮤니티에 대해 보고서와 같은 요약을 생성할 수 있다. 이러한 요약은 데이터셋의 전체 구조와 의미를 이해하는 데 독립적으로 유용하며, 코퍼스를 문제없이 이해하는 데 사용할 수 있다. 위 그림은 는 커뮤니티 요약의 생성 방법을 보여준다.
Step 4: Community Summaries → Community Answers → Global Answer
해당 단계에서는 이전 단계의 커뮤니티 요약을 기반으로 최종 답변을 생성한다. 커뮤니티 구조의 계층적 특성 때문에, 다양한 수준의 요약이 여러 질문에 답할 수 있다. Graph RAG에서는 세부 사항과 포괄성 간의 균형을 맞추기 위해 추가 평가(논문 Graph RAG의 섹션 3) 후에 가장 적절한 추상화 수준을 선택한다. 주어진 커뮤니티 수준에 대해, 다음 그림에서 보이는 것처럼 사용자 쿼리에 대한 전역 답변이 생성된다.

HiPPoRAG
HippoRAG는 인간의 장기 기억에 관한 해마 인덱싱 이론에서 영감을 받은 새로운 검색 프레임워크이다. 이 프레임워크는 대형 언어 모델(LLM), 지식 그래프, 개인화된 페이지랭크 알고리즘과 협력하며, 이 과정은 인간 기억에서 신피질과 해마의 다양한 역할을 모방한다.
다음 그림은 인간 뇌가 지식 통합의 어려운 과제를 비교적 쉽게 해결할 수 있는 방법을 보여준다. 환경 기반의 지속적으로 업데이트되는 기억은 신피질과 C자 모양의 해마 간의 상호작용에 의존한다. 신피질은 실제 기억 표현을 처리하고 저장하며, 해마는 해마 인덱스를 유지한다. 이 인덱스는 신피질의 기억 단위를 가리키고 그들의 연관성을 저장하는 상호 연결된 인덱스 집합에 해당한다.

위 그림은 수천 명의 스탠포드 교수들과 알츠하이머병 연구자들을 설명할 수 있는 수많은 단락 중에서 알츠하이머병 연구에 참여하는 스탠포드 교수를 식별한다. 전통적인 RAG는 단락을 독립적으로 인코딩하기 때문에 두 가지 특징을 동시에 언급하지 않으면 Thomas 교수를 식별하는 데 어려움을 겪는다. 반면, 이 교수를 잘 아는 사람들은 우리의 뇌가 연관 기억 능력 덕분에 그를 빠르게 기억할 수 있는데, 이는 위 그림에서 파란색으로 표시된 C자형 해마 인덱스 구조에 의해 구동되는 것으로 생각된다. 이 메커니즘에서 영감을 받아 HippoRAG는 LLM이 유사한 연관 맵을 구성하고 활용하여 지식 통합 작업을 관리할 수 있게 한다.
이에 영감받아, HippoRAG는 인간 장기 기억의 세 가지 구성 요소를 시뮬레이션하여 패턴 분리 및 완성 기능을 모방하도록 설계되었다.

오프라인 인덱싱의 경우, LLM은 단락을 처리하여 개방형 지식 그래프(KG) 트리플로 변환한다. 이러한 트리플은 인공 해마 인덱스에 추가되고, 합성 부해마 영역(PHR)은 동의어를 감지한다. e.g) HippoRAG는 Thomas 교수와 관련된 트리플을 추출하여 지식 그래프에 통합한다.
온라인 검색의 경우, LLM 신피질이 쿼리에서 명명된 엔티티를 추출한다. 부해마 검색 인코더는 이를 해마 인덱스와 연결한다. HippoRAG는 개인화된 페이지랭크 알고리즘을 사용하여 문맥 기반 검색을 수행하고, Thomas 교수와 관련된 정보를 추출한다.
다음은 HippoRAG의 파이프라인을 소개하는 실제 예시로, 질문, 이에 대한 답변 그리고 지원 및 방해 단락을 보여준다.

다음 그림은 OpenIE 절차와 관련된 지식 그래프의 하위 그래프를 포함한 인덱싱 단계를 보여준다.

마지막으로, 그림 15는 검색 단계를 보여주며, 여기에는 쿼리 명명된 엔터티 인식(NER), 쿼리 노드 검색, 개인화된 페이지랭크(PPR) 알고리즘이 노드 확률에 미치는 영향, 그리고 상위 검색 결과의 계산이 포함된다.

How to Build Long-Term Memory
장기 기억을 구축하는 과정은 주로 다음 세 가지 단계로 구성된다.
Step 1.다음 그림에 나타난것 처럼, OpenIE를 사용하여 검색 코퍼스의 각 단락에서 명명된 엔터티 집합을 추출하기 위해 LLM을 사용한다.

Step 2. 그림과 같이 명명된 엔터티를 OpenIE 프롬프트에 추가하여 최종 트리플을 추출한다.

Step 3. 미세 조정된 기성품 밀집 인코더를 사용하여 지식 그래프를 생성하며, 해당 그래프는 검색에도 사용된다.
How to Retrieve
Step 1. 그림과 같이 사용자 쿼리에서 명명된 엔터티 집합을 추출하기 위해 LLM을 사용한다.

Step 2. 검색 인코더에 의해 결정된 유사성을 기반으로 이러한 명명된 엔티티를 지식 그래프의 노드에 연결한다. 우리는 이 선택된 노드들을 쿼리 노드라고 부른다. 해마에서는 해마 인덱스 요소 간의 신경 경로가 관련된 인접 지역을 활성화하고 상류로 회상할 수 있게 한다. 이 효율적인 그래프 검색 과정을 모방하기 위해 HippoRAG는 PageRank의 한 버전인 Personalized PageRank (PPR) 알고리즘을 활용한다. 이 알고리즘은 사용자 정의 소스 노드 집합을 통해서만 그래프에 확률을 분배한다.
def rank_docs(self, query: str, top_k=10):
"""
Rank documents based on the query
@param query: the input phrase
@param top_k: the number of documents to return
@return: the ranked document ids and their scores
"""
...
...
# Run Personalized PageRank (PPR) or other Graph Alg Doc Scores
if len(query_ner_list) > 0:
combined_vector = np.max([top_phrase_vectors], axis=0)
if self.graph_alg == 'ppr':
ppr_phrase_probs = self.run_pagerank_igraph_chunk([top_phrase_vectors])[0]
elif self.graph_alg == 'none':
ppr_phrase_probs = combined_vector
elif self.graph_alg == 'neighbor_2':
ppr_phrase_probs = self.get_neighbors(combined_vector, 2)
elif self.graph_alg == 'neighbor_3':
ppr_phrase_probs = self.get_neighbors(combined_vector, 3)
elif self.graph_alg == 'paths':
ppr_phrase_probs = self.get_neighbors(combined_vector, 3)
else:
assert False, f'Graph Algorithm {self.graph_alg} Not Implemented'
fact_prob = self.facts_to_phrases_mat.dot(ppr_phrase_probs)
ppr_doc_prob = self.docs_to_facts_mat.dot(fact_prob)
ppr_doc_prob = min_max_normalize(ppr_doc_prob)
else:
ppr_doc_prob = np.ones(len(self.extracted_triples)) / len(self.extracted_triples)
...
...마지막으로, 해마 신호가 상류로 보내질 때처럼, HippoRAG는 이전에 인덱싱된 단락들에 대해 출력된 PPR 노드 확률을 집계하고 이를 사용하여 검색 순위를 매긴다.
spRAG
spRAG는 복잡한 쿼리를 관리하기 위한 방법으로, AutoContext, Relevant Segment Extraction(RSE) 두 가지 주요 기법을 통해 표준 RAG의 성능을 향상시킨다.
AutoContext: Automatic Injection of Document-Level Context
전통적인 RAG에서는 문서가 임베딩을 위해 일반적으로 고정 길이의 청크로 나뉜다. 이 단순한 방법은 문서 수준의 문맥 정보를 종종 간과하여 덜 정확하고 포괄적인 문맥 임베딩을 초래한다. 이 문제를 해결하기 위해 AutoContext가 개발되었으며, 핵심 아이디어는 임베딩 전에 각 청크에 문서 수준의 문맥 정보를 자동으로 포함시키는 것이다. 구체적으로, 1~2문장의 문서 요약을 작성하고 이를 파일명과 함께 각 청크의 시작 부분에 추가한다. 그 결과, 각 청크는 더 이상 고립되지 않고 전체 문서의 문맥 정보를 담게 된다.
def get_document_context(auto_context_model: LLM, text: str, document_title: str, auto_context_guidance: str = ""):
# truncate the content if it's too long
max_content_tokens = 6000 # if this number changes, also update the truncation message above
text, num_tokens = truncate_content(text, max_content_tokens)
if num_tokens < max_content_tokens:
truncation_message = ""
else:
truncation_message = TRUNCATION_MESSAGE
# get document context
prompt = PROMPT.format(auto_context_guidance=auto_context_guidance, document=text, document_title=document_title, truncation_message=truncation_message)
chat_messages = [{"role": "user", "content": prompt}]
document_context = auto_context_model.make_llm_call(chat_messages)
return document_contextRelevant Segment Extraction: Intelligent Combination of Related Text chunks
RSE는 후처리 단계로, 그 목적은 가장 관련성 높은 정보를 제공할 수 있는 청크를 지능적으로 식별하고 결합하여 더 긴 세그먼트를 형성하는 것이다. 구체적으로, RSE는 먼저 내용이 유사하거나 의미적으로 관련된 청크를 그룹화한다. 그런 다음, 쿼리 요구 사항에 따라 이 청크들을 지능적으로 선택하고 결합하여 최적의 세그먼트를 형성한다.
def get_best_segments(all_relevance_values: list[list], document_splits: list[int], max_length: int, overall_max_length: int, minimum_value: float) -> list[tuple]:
"""
This function takes the chunk relevance values and then runs an optimization algorithm to find the best segments.
- all_relevance_values: a list of lists of relevance values for each chunk of a meta-document, with each outer list representing a query
- document_splits: a list of indices that represent the start of each document - best segments will not overlap with these
Returns
- best_segments: a list of tuples (start, end) that represent the indices of the best segments (the end index is non-inclusive) in the meta-document
"""
best_segments = []
total_length = 0
rv_index = 0
bad_rv_indices = []
while total_length < overall_max_length:
# cycle through the queries
if rv_index >= len(all_relevance_values):
rv_index = 0
# if none of the queries have any more valid segments, we're done
if len(bad_rv_indices) >= len(all_relevance_values):
break
# check if we've already determined that there are no more valid segments for this query - if so, skip it
if rv_index in bad_rv_indices:
rv_index += 1
continue
# find the best remaining segment for this query
relevance_values = all_relevance_values[rv_index] # get the relevance values for this query
best_segment = None
best_value = -1000
for start in range(len(relevance_values)):
# skip over negative value starting points
if relevance_values[start] < 0:
continue
for end in range(start+1, min(start+max_length+1, len(relevance_values)+1)):
# skip over negative value ending points
if relevance_values[end-1] < 0:
continue
# check if this segment overlaps with any of the best segments
if any(start < seg_end and end > seg_start for seg_start, seg_end in best_segments):
continue
# check if this segment overlaps with any of the document splits
if any(start < split and end > split for split in document_splits):
continue
# check if this segment would push us over the overall max length
if total_length + end - start > overall_max_length:
continue
segment_value = sum(relevance_values[start:end]) # define segment value as the sum of the relevance values of its chunks
if segment_value > best_value:
best_value = segment_value
best_segment = (start, end)
# if we didn't find a valid segment, mark this query as done
if best_segment is None or best_value < minimum_value:
bad_rv_indices.append(rv_index)
rv_index += 1
continue
# otherwise, add the segment to the list of best segments
best_segments.append(best_segment)
total_length += best_segment[1] - best_segment[0]
rv_index += 1
return best_segmentsComparison of Algorithms and Data Structures
RAPTOR는 클러스터링을 통해 트리 형태의 데이터 구조를 구축하고 이 구조를 기반으로 검색을 수행한다. Graph RAG와 HippoRAG 모두 지식 그래프를 사용하지만, 몇 가지 차이점이 있다: 데이터 구조 측면에서 Graph RAG 및 RAPTOR는 지식 요소를 요약하여 정보를 통합하기에, 새로운 데이터가 추가될 때마다 요약 과정을 반복한다. 반면, HippoRAG는 단순히 지식 그래프에 엣지를 추가하는 것만으로 새로운 지식을 원활하게 통합할 수 있다. 검색 알고리즘 측면에서 Graph RAG는 커뮤니티 탐지에 의존하는 반면, HippoRAG는 개인화된 페이지랭크(PPR) 알고리즘을 사용한다. spRAG는 다른 것들과 달리 고급 데이터 구조를 사용하지 않으며, 단순히 문서 요약과 파일 이름을 각 청크에 추가하고, 관련성 값을 기반으로 검색을 수행한다. 이를 통해 spRAG의 인덱싱 및 검색 속도가 가장 빠를 것임을 시사한다.
About Performance
HippoRAG는 RAPTOR를 기준으로 실험을 수행하여 RAPTOR를 능가하는 일부 결과를 보인다.

Ref.
https://ai.gopubby.com/advanced-rag-11-query-classification-and-refinement-2aec79f4140b
'AI > Natural Language Processing' 카테고리의 다른 글
| Re-ranking (실습) (0) | 2024.06.24 |
|---|---|
| Unveiling PDF Parsing (실습) (0) | 2024.06.21 |
| Query Classification and Refinement (2) | 2024.06.18 |
| Corrective Retrieval Augmented Generation (CRAG) (0) | 2024.06.18 |
| Prompt Compression (이론) (0) | 2024.06.18 |
블로그의 정보
코딩하는 오리
Cori