Query Classification and Refinement
by Cori해당 포스트는 Medium 'Florian June'이 작성한 Advanced RAG 포스트 시리즈 그 열한번째 내용을 정리하며, 초기 쿼리를 개선하는 쿼리 분류와 쿼리 정제에 대해 다루고 있다.
전통적인 RAG 기술은 LLM의 답변 부정확성을 완화할 수 있지만, 초기 쿼리를 개선하지는 않는다.
Problem 1. 간단한 쿼리를 처리하는 데 과도한 컴퓨팅 자원을 소비할 수 있다.
Problem 2. 복잡한 쿼리의 경우, 원래 쿼리만으로는 충분한 정보를 수집하지 못할 수 있다.
Problem 3. 여러 가지 답이 가능한 모호한 쿼리의 경우, 원래 쿼리를 사용한 정보 검색이 충분하지 않다.
쿼리 분류와 쿼리 정제를 통해 초기 쿼리를 개선할 수 있으며, 두 방법 모두 소형 모델의 훈련을 통해 개선될 수 있다.
Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity
Adaptive-RAG는 새로운 적응형 프레임워크를 도입한다. 해당 프레임워크는 쿼리의 복잡성에 따라 가장 적절한 전략을 동적으로 선택하며, 가장 간단한 전략에서부터 가장 복잡한 전략에 이르기까지 다양한 방법을 LLM에 적용할 수 있다.

위 그림은 관련 문서를 먼저 검색하고 답을 생성하는 단일 단계 접근 방식을 나타낸다. 그러나 이 방법은 복잡한 쿼리에 대해 충분히 정확하지 않을 수 있다. 위 그림에서 Multi-Step Approach는 반복적인 문서 검색과 중간 응답 생성을 포함하는 다단계 프로세스를 상징한다. 해당 방법은 효과적이지만 간단한 쿼리에는 비효율적이다. Adaptive Approach는 정교하게 구성된 분류기를 사용하여 쿼리의 복잡성을 판단하는 적응형 접근 방식을 나타낸다. 이 방법은 반복적, 단일 또는 검색이 필요 없는 방법을 포함하여 LLM 검색에 가장 적합한 전략을 선택하는 데 도움이 된다.

코드는 쿼리의 복잡성에 따라 다양한 도구를 호출한다:
Case 1, 복잡한 쿼리: 여러 도구를 사용하며, 여러 문서의 맥락이 필요하다.
Case 2, 간단한 쿼리: 단일 도구를 사용하며, 하나의 문서 맥락만 필요하다.
Case 3, 직접적인 쿼리: LLM을 직접 사용하여 답을 제공한다.
Adaptive Approach 단계에서, 도구는 분류기를 통해 선택되며 분류기는 훈련되지 않은 기존의 LLM을 직접 사용한다.

Construction of the Classifier
Construction of the Dataset
쿼리-복잡성 쌍에 대한 주석 데이터 세트가 부족한데, 이를 해결하기 위해 Adaptive-RAG는 훈련 데이터 세트를 자동으로 구축하는 두 가지 특정 전략을 사용한다.
Strategy 01. 가장 간단한 비검색 기반 방법: 올바른 답을 생성하면 해당 쿼리의 레이블을 'A'로 표시한다. 단일 단계 방법으로 올바르게 답변된 쿼리는 'B'로, 다단계 방법으로 답변된 쿼리는 'C'로 레이블링하며, 간단한 모델에 더 높은 우선순위를 부여한다. 예를 들어, 단일 단계와 다단계 방법 모두 올바른 결과를 생성하고 비검색 기반 방법이 실패하면 해당 쿼리에 'B' 레이블을 지정한다.
Strategy 02. 만약 세 가지 방법 모두 올바른 답을 생성하지 못하면 일부 질문이 레이블이 없는 상태로 남게 되는데, 이 경우 공개 데이터세트에서 직접 할당이 수행된다. 구체적으로, 단일 홉 데이터세트의 쿼리에는 'B'를 할당하고, 다중 홉 데이터세트의 쿼리에는 'C'를 할당한다.
Training and Inference
훈련 방법은 자동으로 수집된 쿼리-복잡성 쌍을 기반으로 분류기를 교차 엔트로피 손실을 사용하여 훈련하는 것을 포함한다. 그런 다음 추론 시, 쿼리를 분류기에 전달하여 쿼리의 복잡성 {‘A’, ‘B’, ‘C’} 중 하나를 결정할 수 있다: o = Classifier(q).
Selection of Classifier Size

다양한 크기의 분류기들 간 성능 차이는 거의 없다. 작은 모델도 성능에 영향을 미치지 않아서 자원 효율성에 도움이 된다.
RQ-RAG: Learning To Refine Queries For Retrieval Augmented Generation
언급된 문제들에 대응하여, RQ-RAG는 세 가지 개선점을 제안한다.

Solution 1. 일상적인 인사말과 같은 간단한 질문의 경우, 맥락을 도입하면 응답의 질이 낮아질 수 있다. LLM은 불필요한 맥락을 추가하지 않고 직접적으로 응답해야 한다.
Solution 2. 복잡한 쿼리는 답변 가능한 더 단순한 하위 쿼리로 나뉜다. 각 하위 쿼리에 대한 정보를 검색하여 원래 복잡한 쿼리에 대한 포괄적인 응답을 형성한다.
Solution 3. 여러 가지 잠재적 응답이 있는 모호한 쿼리의 경우, 초기 쿼리 문구를 사용한 검색만으로는 충분하지 않다. LLM은 쿼리를 명확히 하고, 사용자 의도를 파악한 후 구체적인 검색 전략을 세워야 한다.
RQ-RAG 알고리즘의 핵심은 쿼리를 분류하고 정제하는 것이며, 접근 방식은 Llama2 7B 모델을 엔드투엔드 방식으로 훈련하는 것을 포함한다. 모델은 쿼리 재작성, 분해, 모호성을 명확히 하여 동적으로 검색 쿼리를 향상시킬 수 있다.
다만, 현재 RQ-RAG의 코드는 리팩토링 중에 있어 일부 부분이 아직 동작하지 않기에, 시연하기에는 어려움이 있다.
Dataset Construction
엔드투엔드 특성 상, 데이터세트 구축 전략에 초점을 두는 것이 중요하다.

데이터셋 구축은 주로 다음 단계로 구성된다:
Step 1. 다양한 시나리오를 포함하는 코퍼스를 수집한다. 다중 턴 대화, 분해가 필요한 쿼리, 모호성을 해소해야 하는 쿼리가 포함되며, 이 코퍼스를 사용하여 작업 풀을 만든다.
Step 2. 작업 풀의 작업은 다중 턴 대화, 분해, 모호성 해소의 세 가지 범주로 나뉜다. 예를 들어, 다중 턴 대화 데이터셋의 샘플은 다중 턴 대화 범주로 분류된다.
Step 3. ChatGPT를 사용하여 각 유형의 쿼리를 정제하고, 이를 사용하여 외부 데이터 소스에서 정보를 검색한다. 일반적으로 DuckDuckGo를 주요 소스로 사용하며, 검색 과정은 블랙박스로 처리된다.
Step 4. ChatGPT에 정제된 쿼리와 해당 맥락을 기반으로 수정된 응답을 생성하도록 한다.
이 과정을 반복하여 총 약 4만 개의 인스턴스를 모은다. 다음 그림들은 ChatGPT와 상호작용하기 위한 프롬프트 템플릿을 보여준다.



위 과정이 완료되면 훈련 샘플을 얻을 수 있다.
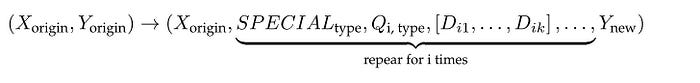
각 샘플은 특수 토큰이 포함된 작업 시퀀스로 구성된다. 각 요소의 의미는 다음과 같다:
- 'Xorigin' 및 'Yorigin'은 원본 데이터셋의 입력-출력 쌍을 나타낸다.
- 'Type'은 최적화 작업을 의미하며, 재작성, 분해, 모호성 제거가 포함된다.
- 'i'는 반복 라운드를 나타낸다.
- 'SPECIALtype'은 최적화 유형을 나타낸다.
- 'Qi, type'은 i번째 라운드에서 특정 특수 태그에 따라 최적화된 쿼리를 나타낸다.
- '[Di1, Di2, . . . , Dik]'은 i번째 라운드에서 검색된 상위 k개의 문서를 나타낸다.
- 'Ynew'는 최종 반복 단계에서 생성된 새로운 답변을 나타낸다.
Training
훈련 데이터셋을 확보한 후, 이를 표준 자기 회귀 방식으로 LLM을 훈련하는 데 사용할 수 있다. 훈련 목표는 다음과 같다.

간단히 말해, 훈련의 목표는 i번째 단계에서 원래 입력 x, 향상된 쿼리 qi, 검색된 문서 di를 주어 모델 M이 응답 y에 대해 가장 높은 확률을 생성하도록 모델 파라미터를 조정하는 것이다.
Answer Selection
각 반복 동안 모델은 특정 요구에 맞춰 다양한 검색 쿼리(재작성, 분해, 모호성 해결)를 디코딩한다. 이러한 쿼리는 각각 다른 맥락을 얻어 확장 경로의 다양성을 촉진한다.

위 그림에서 볼 수 있듯이, RQ-RAG는 트리 디코딩 전략을 개발하고 세 가지 선택 방법(PPL 기반 선택, 신뢰도 기반 선택, 앙상블 기반 선택)을 사용하며, 전체 출력에서 가장 낮은 perplexity(PPL)를 가진 답변을 선택한다.
* 신뢰도 기반 선택: 가장 높은 신뢰도를 가진 모든 결과 선택
**앙상블 기반 선택: 누적 신뢰도 점수가 가장 높은 최종 결과 선택
Comparison with Self-RAG and CRAG
Adaptive-RAG와 RQ-RAG는 Self-RAG와 CRAG와 달리 검색 전에 원래 쿼리를 개선하지 않고, 검색 실행 여부와 검색 후 최적화에 중점을 둔다. CRAG는 웹 검색을 위해 쿼리를 재작성하여 검색된 정보의 품질을 개선한다. RQ-RAG와 Self-RAG는 원래 LLM을 소형 LLM으로 대체하지만, Adaptive-RAG와 CRAG는 원래 LLM을 대체하지 않고 쿼리 분류 층 또는 평가 층을 추가한다. 실험 결과, Adaptive-RAG와 RQ-RAG는 Self-RAG보다 우수한 성능을 보였으며 생성 과정 관점에서 보면, Self-RAG, CRAG, Adaptive-RAG는 트리 디코딩을 사용하지 않아 더 간단하다.
About Engineering Implementation
쿼리가 다중 턴 대화로 전환되는 상황에서는 긴 프롬프트 데이터를 LLM과 함께 사용할 때 지연이 발생할 수 있으며, 이 경우 병렬화가 가능한 해결책일 수 있다. 또한, Adaptive-RAG와 RQ-RAG는 쿼리를 분류하지만, 이러한 분류가 최적인지, 특정 산업 시나리오에 적합한지, 다른 분류 방법이 더 나은 결과를 제공할 수 있는지 확실하지 않다. (증명 위해 비교 실험 필요)
Ref.
https://ai.gopubby.com/advanced-rag-11-query-classification-and-refinement-2aec79f4140b
'AI > Natural Language Processing' 카테고리의 다른 글
| Unveiling PDF Parsing (실습) (0) | 2024.06.21 |
|---|---|
| Enhancing Global Understanding (0) | 2024.06.19 |
| Corrective Retrieval Augmented Generation (CRAG) (0) | 2024.06.18 |
| Prompt Compression (이론) (0) | 2024.06.18 |
| Self-RAG (이론) (0) | 2024.06.17 |
블로그의 정보
코딩하는 오리
Cori