Unveiling PDF Parsing (이론)
by Cori해당 포스트는 Medium 'Florian June'이 작성한 Advanced RAG 포스트 시리즈 그 두 번째 내용을 정리하며, PDF 문서를 효과적으로 처리하는 방법에 대해 다루고 있다.
실제 작업에서는 비구조화된 데이터가 구조화된 데이터보다 훨씬 더 많다. 이러한 방대한 데이터를 파싱할 수 없다면, 그 엄청난 가치를 실현할 수 없다. 비구조화된 데이터 중에서 PDF 문서가 대부분을 차지하며, PDF 문서를 효과적으로 처리하는 것은 다른 유형의 비구조화된 문서를 관리하는 데에도 큰 도움이 될 수 있다.
The Challenges of Parsing PDF

PDF 문서는 비구조화된 문서의 대표적인 예이지만, PDF 문서에서 정보를 추출하는 것은 도전적인 과정이다. PDF 파일은 PDF 리더기나 프린터가 화면이나 종이에 기호를 어디에, 어떻게 표시할지를 지시하는 일련의 명령어로 구성된다. 이는 <p>, <w >, <table>, <w>과 같은 태그를 사용하여 서로 다른 논리 구조를 구성하는 HTML이나 docx 파일 형식과는 대조적이다. 이러한 특성으로 인해, PDF 문서를 파싱하는데 있어 도전 과제는 페이지 전체의 레이아웃을 정확하게 추출하고, 표, 제목, 단락, 이미지 등을 포함한 문서의 텍스트를 변환하는데 있다.
How to parse PDF documents
method #01. Rule-based approach
규칙 기반 파싱 방법 중 가장 널리 사용되는 라이브러리는 pypdf로, LangChain 및 LamaIndex에서 이를 사용한다.
import PyPDF2
filename = "{file_path}.pdf"
pdf_file = open(filename, 'rb')
reader = PyPDF2.PdfReader(pdf_file)
page_num = 3
page = reader.pages[page_num]
text = page.extract_text()
print('--------------------------------------------------')
print(text)
pdf_file.close()이후 실습에서 다루겠지만, PyPDF의 경우 PDF의 문자 시퀀스를 그대로 유지하지 않고 단일 긴 시퀀스로 직렬화한다. 즉, 각 문서의 줄을 줄바꿈 문자 '\n'로 구분된 시퀀스로 처리하기에 단락이나 표를 정확하게 식별하지 못한다.
method #02. Deep-Learning models
딥러닝 모델을 이용한 PDF 파싱의 경우 표와 단락을 포함한 문서 전체의 레이아웃을 정확하게 식별할 수 있으며, 표 내의 구조도 이해할 수 있다. 다만 몇 가지 제한 사항이 있는데, 객체 탐지와 OCR 단계는 많은 시간이 소요될 수 있어 GPU나 기타 가속 장치가 필요하다는 것이다. 다음 3가지 모델은 오픈소스로 공개된 딥러닝 모델들이다. 오픈소스 모델 외에 레이아웃 기반 인식과 OCR 접근 방식을 이용하여 PDF 문서를 파싱하는 ChatDoc 같은 유료 모델도 있다.
model1: Unstructured
- 해당 모델은 LangChain에 통합되었으며, infer_table_structure=True로 설정한 hi_res 전략의 표 인식 효과는 좋지만 fast 전략은 객체 탐지 모델을 사용하지 않기 때문에 이미지와 표 인식에서의 성능이 저하된다. 해당 모델은 크게 3가지 도전 과제가 존재한다.
- How to extract data from tables and images
from unstructured.partition.pdf import partition_pdf
filename = "{file_path}.pdf"
# infer_table_structure=True automatically selects hi_res strategy
elements = partition_pdf(filename=filename, infer_table_structure=True)
tables = [el for el in elements if el.category == "Table"] # Table 추출하기
print(tables[0].text)
print('--------------------------------------------------')
print(tables[0].metadata.text_as_html)Unstructured 모델은 테이블을 HTML 태그로 변환하며, 이를 HTML 형식으로 저장할 수 있다.
- How to rearrange the detected blocks? Especially for double-column PDFs
Unstructured 모델은PDF 문서를 다음과 같이 블록으로 인식한다.


페이지의 읽기 순서를 재정렬할 수 있는 옵션이 있는데, Unstructured의 내장된 정렬 알고리즘은 다중 열 상황을 처리할 때 그다지 좋은 결과를 내지 못했다. 이런 경우, 정렬 알고리즘을 설계해야 하는데 가장 간단한 방법은 x_1 좌표로 먼저 정렬한 후, 해당 좌표가 동일한 경우 세로 좌표로 정렬하는 것이다.
layout.sort(key=lambda z: (z.bbox.x1, z.bbox.y1, z.bbox.x2, z.bbox.y2))하지만 위와 같이 코드를 작성할 경우 가끔가다 동일한 좌표선상에 있지 않은 애들을 만날 경우 오류가 발생한다.

이런 경우, 좀 더 고도화된 정렬 알고리즘이 필요하다. 먼저 모든 왼쪽 상단 좌표를 정렬하여 최소값(x1_min)을 구하고, 오른쪽 하단 좌표를 정렬하여 최대값(x2_max)을 구한 후, 이 정보를 사용하여 중앙선의 x 좌표를 계산한다. x1 값이 중앙선 x 좌표보다 작은지 아닌지에 따라 왼쪽 열인지 오른쪽 열인지 구할 수 있다. 분류가 완료되면 각 열 내에서 블록을 y 좌표 기준으로 정렬하고, 마지막으로 오른쪽 열을 왼쪽 열로 이어붙인다.
- How to extract multiple-level headings
다중 레벨 제목을 포함한 제목을 추출하는 목적은 LLM의 답변 정확도를 높이는 것이다. 예를 들어, 사용자가 문서에서 2.1절의 주요 내용을 알고 싶어 할 때, 2.1절의 제목을 정확하게 추출하여 관련 내용을 문맥으로 LLM에 보내면 최종 답변의 정확도가 크게 향상된다. Unstructured 라이브러리를 사용하여 type='Section-header'인 블록을 추출하고 높이 차이를 계산한다. 가장 큰 높이 차이를 가진 블록이 첫 번째 레벨 제목에 해당하고, 그 다음이 두 번째 레벨 제목, 그 다음이 세 번째 레벨 제목이 된다.
model2: LayoutParser
- 지난 2년동안 업데이트 되지 않았으며, 복잡한 구조의 PDF를 인식해야 하는 경우 약간 느리더라도 가장 큰 모델을 사용하는 것이 좋다.
model3: PP-StructureV2
- PDF 문서 분석을 위해 다양한 모델 조합이 사용되며, 성능은 평균보다 좋다.
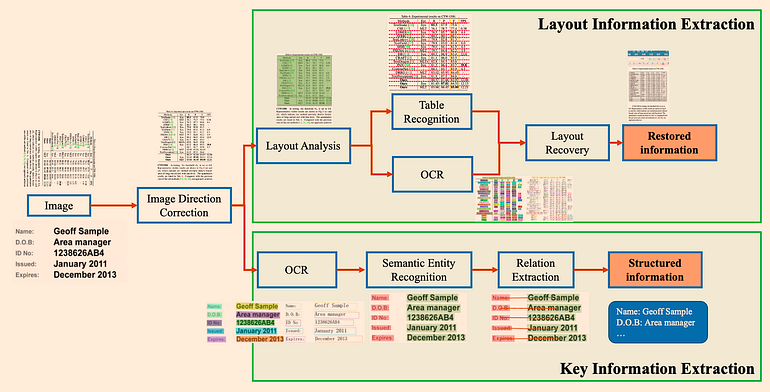
method #03. Multi-modal large models
멀티모달 모델을 사용하여 표를 파싱하는 것도 가능한데, 크게 4가지 방법을 사용하며 이 중 3번째 방법의 성능이 좋다.
- 관련 이미지를 검색하여(GPT 페이지) GPT-4-V에 보내 쿼리에 응답하게 함
- 모든 PDF 페이지를 이미지로 간주하고, 각 페이지에 대해 GPT-4-V가 이미지 추론을 수행, 이에 대한 벡터 스토어 인덱스를 구축한다. 이미지 추론 벡터 스토어에 대해 답변을 응답함
- Table Transformer를 사용하여 검색된 이미지에서 표 정보를 잘라내고, 이를 GPT-4-V에 보내 쿼리에 응답하게 함
- 잘라낸 표 이미지에 OCR을 적용하여 데이터를 GPT-4/GPT-3.5에 보내 쿼리에 응답하게 함
Ref.
'AI > Natural Language Processing' 카테고리의 다른 글
| Using RAGAs + LlamaIndex for RAG evaluation (이론) (1) | 2024.06.11 |
|---|---|
| Unveiling PDF Parsing: How to extract formulas from scientific pdf papers (0) | 2024.06.10 |
| Problem of Naive RAG (2) | 2024.06.10 |
| RAG (Retrieval-Augmented Generation) (0) | 2024.06.05 |
| [LLM] Aya23 (0) | 2024.05.28 |
블로그의 정보
코딩하는 오리
Cori