Using RAGAs + LlamaIndex for RAG evaluation (이론)
by Cori해당 포스트는 Medium 'Florian June'이 작성한 Advanced RAG 포스트 시리즈 그 세번째 내용을 정리하며, RAG 파이프라인 평가를 위한 프레임워크인 RAGAs(Retrieval Augmented Generation Assessment)가 제안한 RAG 평가 지표에 대해 다루고 있다.
비즈니스 시스템을 위한 Retrieval Augmented Generation(RAG) 애플리케이션을 개발했다면, 시스템이 얼마나 잘 작동하는지 평가해야 한다. 기존 RAG가 충분히 효과적이지 않다고 판단되면, 고급 RAG 개선 방법의 효과를 검증할 필요가 있을 수 있다.
Metrics of RAG evaluation
RAG는 입력 쿼리, 검색된 문맥, 그리고 LLM에 의해 생성된 응답이라는 세 가지 주요 부분으로 구성된다. 이 세 가지 요소는 RAG 과정에서 가장 중요한 삼각 관계를 형성하며 상호 의존적이다. 따라서 RAG의 효과는 그림 1에 나와 있듯이, 이 삼각 관계 사이의 관련성을 측정함으로써 평가할 수 있다.
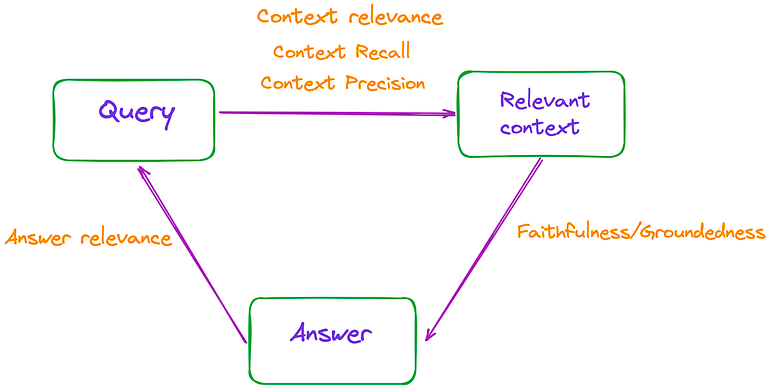
논문에서는 Faithfulness, Answer Relevance, Context Relevance라는 총 3가지 지표를 언급하고 있으며, 이 지표들은 사람이 주석을 단 데이터세트나 참고 답변에 접근할 필요가 없다. 추가로, RAGAs 웹사이트에서는 Context Precision과 Context Recall이라는 두 가지 지표를 더 소개한다.
Faithfulness
답변이 주어진 문맥에 기반하고 있음을 보장하는 것을 의미한다. 환각을 피하고 검색된 문맥이 답변 생성의 근거로 사용될 수 있음을 보장하는 데 중요하며, 점수가 낮으면 LLM의 응답이 환각적인 답변을 제공할 가능성이 높아짐을 나타낸다. Faithfulness 추정을 위해, 프롬프트를 사용하여 일련의 진술을 추출한다.
Given a question and answer, create one or more statements from each sentence in the given answer.
question: [question]
answer: [answer]LLM은 각 진술 si가 c(q)로부터 추론될 수 있는지 여부를 결정하며, 이는 다음 프롬프트를 사용하여 수행된다.
Consider the given context and following statements, then determine whether they are supported by the information present in the context. Provide a brief explan ation for each statement before arriving at the verdict (Yes/No). Provide a final verdict for each statement in order at the end in the given format. Do not deviate from the specified format.
statement: [statement 1]
...
statement: [statement n]최종 Faithfulness 점수, F는 F = |V| / |S|로 계산되는데, 여기서 |V|는 LLM에 의해 지원되는 진술의 수를 나타내며, |S|는 진술의 총 수를 의미한다.
Answer Relevance
해당 지표는 생성된 답변과 쿼리간의 관련성을 측정한다. 답변의 관련성을 추정하기 위해, 주어진 답변 a(q)를 기반으로 LLM이 n개의 잠재적 질문 qi를 생성하도록 프롬프트한다.
Generate a question for the given answer.
answer: [answer]이후, 텍스트 임베딩 모델을 사용하여 모든 질문에 대한 임베딩을 얻는다. 각 qi에 대해 원래 질문 q와의 유사도 sim(q, qi)를 계산한다(코사인 유사도). 질문 q에 대한 답변 관련성 점수 AR는 다음과 같이 계산된다:

Context Relevance
검색 품질을 측정하는 지표로, 주로 검색된 문맥이 쿼리를 얼마나 잘 지원하는지 평가한다. 점수가 낮다는 것은 관련 없는 콘텐츠가 많이 검색되었음을 의미하며, 이는 LLM이 생성하는 최종 답변에 영향을 미칠 수 있다. 문맥의 관련성을 추정하기 위해, LLM을 사용하여 문맥(c(q))에서 핵심 문장 집합(Sext)을 추출한다. 이들은 질문에 답하는 데 중요하며, 프롬프트는 다음과 같다.
Please extract relevant sentences from the provided context that can potentially help answer the following question.
If no relevant sentences are found, or if you believe the question cannot be answered from the given context,
return the phrase "Insufficient Information".
While extracting candidate sentences you’re not allowed to make any changes to sentences from given context.RAGAs에서, 문장 단위 Context Relevance는 다음과 같이 측정된다.

Context Recall
검색된 문맥과 주석된 답변 간의 일관성 수준을 측정하는 지표다.정답과 검색된 문맥을 사용하여 계산되며, 값이 높을수록 성능이 더 좋음을 나타낸다. 해당 값을 계산할 때는 Ground Truth 데이터가 요구된다.
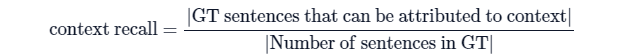
Context Precision
이 지표는 비교적 복잡하며, 검색된 실제 사실을 포함한 모든 관련 문맥이 상위에 랭크되어 있는지를 측정하는 데 사용된다.

Context Precision을 사용하면 순위를 구할 수 있으나, 관련 검색 결과가 매우 적더라도 모두 높은 순위에 있으면 점수가 높게 나오는 단점이 있다.
Using RAGAs + LlamaIndex for RAG evaluation
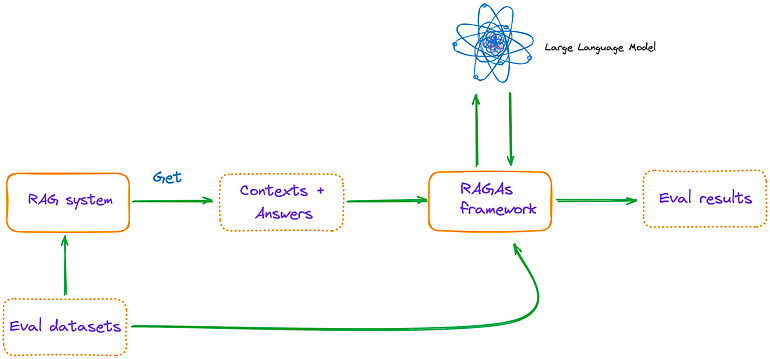
Step 1. Environment Configuration
pip install ragas
pip list | grep ragas* $ pip install git+https://github.com/explodinggradients/ragas.git 명령어를 통해 최신 버전을 설치했다면 LlamaIndex를 지원하지 않을 수 있음
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_KEY"
dir_path = "YOUR_DIR_PATH"
from llama_index import VectorStoreIndex, SimpleDirectoryReader
from ragas.metrics import (
faithfulness,
answer_relevancy,
context_relevancy,
context_recall,
context_precision
)
from ragas.llama_index import evaluateStep 2. Using LlamaIndex to build a simple RAG query engine
documents = SimpleDirectoryReader(dir_path).load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()Step 3. Constructing an evaluation dataset
일부 지표는 수동으로 주석된 데이터셋이 필요하기 때문에, 몇 가지 질문과 그에 해당하는 답변을 직접 작성한다.
eval_questions = [
"Can you provide a concise description of the TinyLlama model?",
"I would like to know the speed optimizations that TinyLlama has made.",
"Why TinyLlama uses Grouped-query Attention?",
"Is the TinyLlama model open source?",
"Tell me about starcoderdata dataset",
]
eval_answers = [
"TinyLlama is a compact 1.1B language model pretrained on around 1 trillion tokens for approximately 3 epochs. Building on the architecture and tokenizer of Llama 2, TinyLlama leverages various advances contributed by the open-source community (e.g., FlashAttention), achieving better computational efficiency. Despite its relatively small size, TinyLlama demonstrates remarkable performance in a series of downstream tasks. It significantly outperforms existing open-source language models with comparable sizes.",
"During training, our codebase has integrated FSDP to leverage multi-GPU and multi-node setups efficiently. Another critical improvement is the integration of Flash Attention, an optimized attention mechanism. We have replaced the fused SwiGLU module from the xFormers (Lefaudeux et al., 2022) repository with the original SwiGLU module, further enhancing the efficiency of our codebase. With these features, we can reduce the memory footprint, enabling the 1.1B model to fit within 40GB of GPU RAM.",
"To reduce memory bandwidth overhead and speed up inference, we use grouped-query attention in our model. We have 32 heads for query attention and use 4 groups of key-value heads. With this technique, the model can share key and value representations across multiple heads without sacrificing much performance",
"Yes, TinyLlama is open-source",
"This dataset was collected to train StarCoder (Li et al., 2023), a powerful opensource large code language model. It comprises approximately 250 billion tokens across 86 programming languages. In addition to code, it also includes GitHub issues and text-code pairs that involve natural languages.",
]
eval_answers = [[a] for a in eval_answers]Step 4. Metrics Selection and RAGAs Evaluation
metrics = [
faithfulness,
answer_relevancy,
context_relevancy,
context_precision,
context_recall,
]
result = evaluate(query_engine, metrics, eval_questions, eval_answers)
result.to_pandas().to_csv('YOUR_CSV_PATH', sep=',')RAGAs에서 LlamaIndex로 평가하기 위해 사용되는 모델은 OpenAI 모델이며, 다른 모델 지원하는지 여부는 추가 확인이 필요하다.
'AI > Natural Language Processing' 카테고리의 다른 글
| Exploring Semantic Chunking (이론) (0) | 2024.06.12 |
|---|---|
| Re-ranking (이론) (0) | 2024.06.11 |
| Unveiling PDF Parsing: How to extract formulas from scientific pdf papers (0) | 2024.06.10 |
| Unveiling PDF Parsing (이론) (0) | 2024.06.10 |
| Problem of Naive RAG (2) | 2024.06.10 |
블로그의 정보
코딩하는 오리
Cori