Re-ranking (실습)
by Cori해당 포스트는 Medium 'Florian June'이 작성한 Advanced RAG 포스트 시리즈 그 네번째 내용을 실제로 실습하는 과정을 정리하며, RAG의 Re-Ranking 과정에 대해 살펴본다. 이론적인 부분은 다음을 참고하자.
Advanced RAG #04: Re-ranking
해당 포스트는 Medium 'Florian June'이 작성한 Advanced RAG 포스트 시리즈 그 네번째 내용을 정리하며, RAG의 Re-Ranking 기술을 소개하고, 두 가지 방법을 사용하여 해당 기능을 통합하는 방법에 대해 다
cori.tistory.com
사용 데이터
실습에 사용한 pdf 파일은 내가 작성했던 졸업 논문이다.
표, 그래프, 수식 등이 포함되어 있어 테스트 용으로 적합한듯 .. ?

Using re-ranking model as reranker
현재 사용할 수 있는 재랭킹 모델은 많지 않으며, Cohere에서 API를 통해 접근할 수 있는 온라인 모델이 대표적이다. 또한, bge-reranker-base와 bge-reranker-large와 같은 오픈 소스 모델들도 있다. bge-reranker-large 모델을 활용해 재순위화를 진행해보자
import os
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.postprocessor.flag_embedding_reranker import FlagEmbeddingReranker
from llama_index.core.schema import QueryBundle
from llama_index.core.schema import ImageNode, MetadataMode, NodeWithScore
from llama_index.core.utils import truncate_text
os.environ["OPENAI_API_KEY"] = "YOUR OPEN API KEY"
dir_path = "YOUR DATA PATH"Llama Index를 활용해 간단한 추출기를 구축해보자
documents = SimpleDirectoryReader(input_files=[os.path.join(dir_path, 'applsci_aud.pdf')]).load_data()
index = VectorStoreIndex.from_documents(documents)
retriever = index.as_retriever(similarity_top_k = 3)노드에 대한 정보를 출력하는 함수를 만들어보자
def display_source_node(
source_node: NodeWithScore,
source_length: int = 100,
show_source_metadata: bool = False,
metadata_mode: MetadataMode = MetadataMode.NONE,
) -> None:
"""Display source node"""
source_text_fmt = truncate_text(
source_node.node.get_content(metadata_mode=metadata_mode).strip(), source_length
)
text_md = (
f"Node ID: {source_node.node.node_id} \n"
f"Score: {source_node.score} \n"
f"Text: {source_text_fmt} \n"
)
if show_source_metadata:
text_md += f"Metadata: {source_node.node.metadata} \n"
if isinstance(source_node.node, ImageNode):
text_md += "Image:"
print(text_md)재순위화 하지 않고 관련 노드들을 추출해보면 다음과 같다.
query = "can not sleep well ?"
nodes = retriever.retrieve(query)
for node in nodes:
print('----------------------------------------------------')
display_source_node(node, source_length=500) # llama index 소스 코드 수정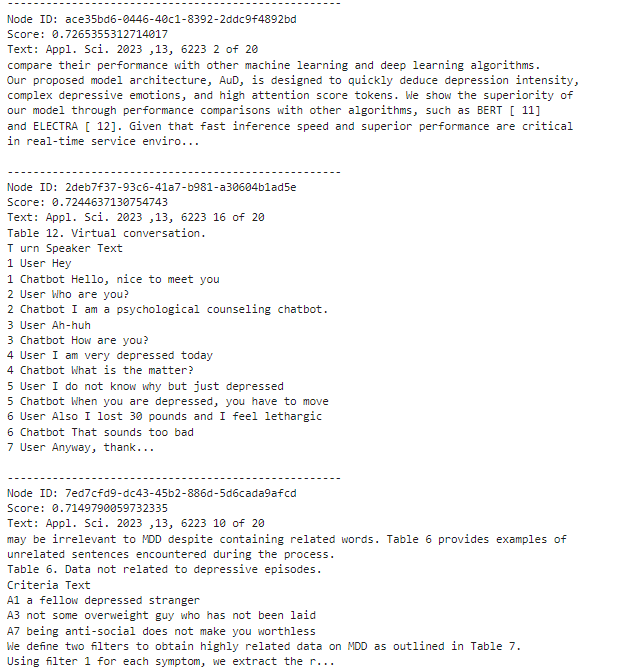
노드들을 재순위화 하는 코드는 다음과 같다.
reranker = FlagEmbeddingReranker(
top_n = 3,
model = "BAAI/bge-reranker-base",
)
query_bundle = QueryBundle(query_str=query)
ranked_nodes = reranker.postprocess_nodes(nodes, query_bundle=query_bundle)
for ranked_node in ranked_nodes:
print('----------------------------------------------------')
display_source_node(ranked_node, source_length = 500)* 다만, 현재 reranker.postprocess_nodes() 함수를 호출하는 과정에서 'Dispatcher' object has no attribute 'get_dispatch_event()' 에러 메시지를 계속 만나는데, 이에 대한 해결책은 찾지 못한 상황이다.
Using LLM as Reranker
여기서는 RankGPT를 활용해 Re-ranking을 적용한다.
Env Setting
!pip install llama-index-postprocessor-rankgpt-rerankfrom llama_index.postprocessor.rankgpt_rerank import RankGPTRerank
from llama_index.llms.openai import OpenAI
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.core.postprocessor import LLMRerank
from llama_index.llms.openai import OpenAI
from IPython.display import Markdown, display
from llama_index.core import Settings
from llama_index.core.retrievers import VectorIndexRetriever
from llama_index.core import QueryBundle
from llama_index.postprocessor.rankgpt_rerank import RankGPTRerank
import nest_asyncio
nest_asyncio.apply()Create Simple Index
documents = SimpleDirectoryReader(input_files=[os.path.join(dir_path, 'applsci_aud.pdf')]).load_data()
index = VectorStoreIndex.from_documents(documents)
retriever = index.as_retriever(similarity_top_k=3)Define functions
def get_retrieved_nodes(query_str, vector_top_k=10, reranker_top_n=3, with_reranker=False):
query_bundle = QueryBundle(query_str)
# configure retriever
retriever = VectorIndexRetriever(
index=index,
similarity_top_k=vector_top_k,
)
retrieved_nodes = retriever.retrieve(query_bundle)
if with_reranker:
# configure reranker
reranker = RankGPTRerank(
llm=OpenAI(
model="gpt-3.5-turbo-16k",
temperature=0.0,
api_key=OPENAI_API_KEY,
),
top_n=reranker_top_n,
verbose=True,
)
retrieved_nodes = reranker.postprocess_nodes(
retrieved_nodes, query_bundle
)
return retrieved_nodesdef pretty_print(df):
return display(HTML(df.to_html().replace("\\n", "<br>")))def visualize_retrieved_nodes(nodes) -> None:
result_dicts = []
for node in nodes:
result_dict = {"Score": node.score, "Text": node.node.get_text()}
result_dicts.append(result_dict)
pretty_print(pd.DataFrame(result_dicts))Extract Nodes
입력 쿼리와 유사한 노드를 추출해보자
new_nodes = get_retrieved_nodes(
"are you depressed ?",
vector_top_k=3,
with_reranker=False,
)
visualize_retrieved_nodes(new_nodes)
재순위화를 적용해서 추출하면 다음과 같은 결과값이 나온다.
new_nodes = get_retrieved_nodes(
"Which date did Paul Gauguin arrive in Arles ?",
vector_top_k=10,
reranker_top_n=3,
with_reranker=True,
)
visualize_retrieved_nodes(new_nodes)
'AI > Natural Language Processing' 카테고리의 다른 글
| Exploring Query Rewriting (실습) (0) | 2024.06.28 |
|---|---|
| Exploring Semantic Chunking (실습) (0) | 2024.06.26 |
| Unveiling PDF Parsing (실습) (0) | 2024.06.21 |
| Enhancing Global Understanding (0) | 2024.06.19 |
| Query Classification and Refinement (2) | 2024.06.18 |
블로그의 정보
코딩하는 오리
Cori