LangGraph
by CoriLangGraph 탄생 배경
- LLM이 생성한 답변이 Hallucination이 발생한 것은 아닐까 ?
- RAG를 적용하여 받은 답변이 문서에는 없는 사전지식으로 답변한 것이 아닐까 ?
- 문서 검색에서 원하는 내용이 없을 경우 부족한 정보를 검색하여 보강할 수 없을까 ?
잘못된 검색 결과가 잘못된 정보 검색으로 이어질 수 있음
=> 사전에 정의된 데이터 소싱 자원, 사전에 정의된 Fixed Size Chunk, 사전에 정의된 Query 입력, 사전에 정의된 검색 방법, 신뢰하기 어려운 LLM 혹은 Agent, 고정된 프롬프트 형식, LLM의 답변 결과에 대한 문서와의 관련성 / 신뢰성
Conventioanl RAG의 문제점은 RAG 파이프라인이 단방향 구조이기 때문에 발생한다.
이전에 잘못된 과정이 있어서 돌아가고 싶어도 수정할 수 없음
LangGraph는 각 세부과정을 노드(Node)로 정의
이전 노드 > 다음 노드를 엣지(Edge) 연결
조건부 엣지를 통해 분기 처리
if 결과가 만족스럽지 않다면, 검색 노드로 다시 보내는 작업 가능
e.g) 로드와 스플릿 각각의 스텝은 노드로 볼 수 있음
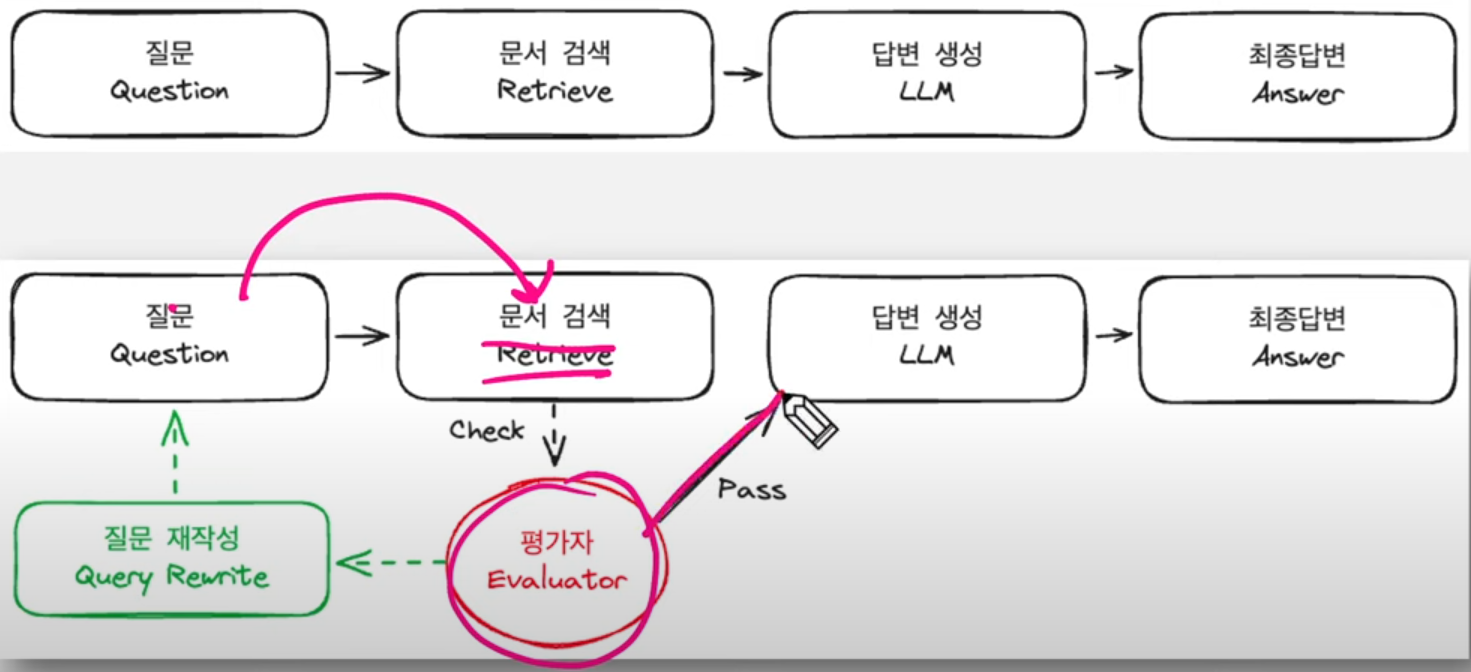

정보 불충분 여부 판단 / 질문 재작성 여부 판단
LangGraph Element
- State, Node, Edge, Conditional Edge
LangGraph 예제들이 복잡한 예제들이 많음
LangChain 사용하지 않고 python만 사용해서 구현해도 가능
* LangGraph 만들 때, 무조건 LangChain을 사용해야 하는 것은 아님 !
구현 시, 두 개 이상의 노드 <-> 노드 간 2개 이상의 엣지 적용 가능
상태는 노드와 노드 간에 정보를 전달할 때 상태 객체에 담아 전달
TypedDict: 일반 파이썬 dict에 타입힌팅을 추가한 개념
엣지를 통해 상태 전달
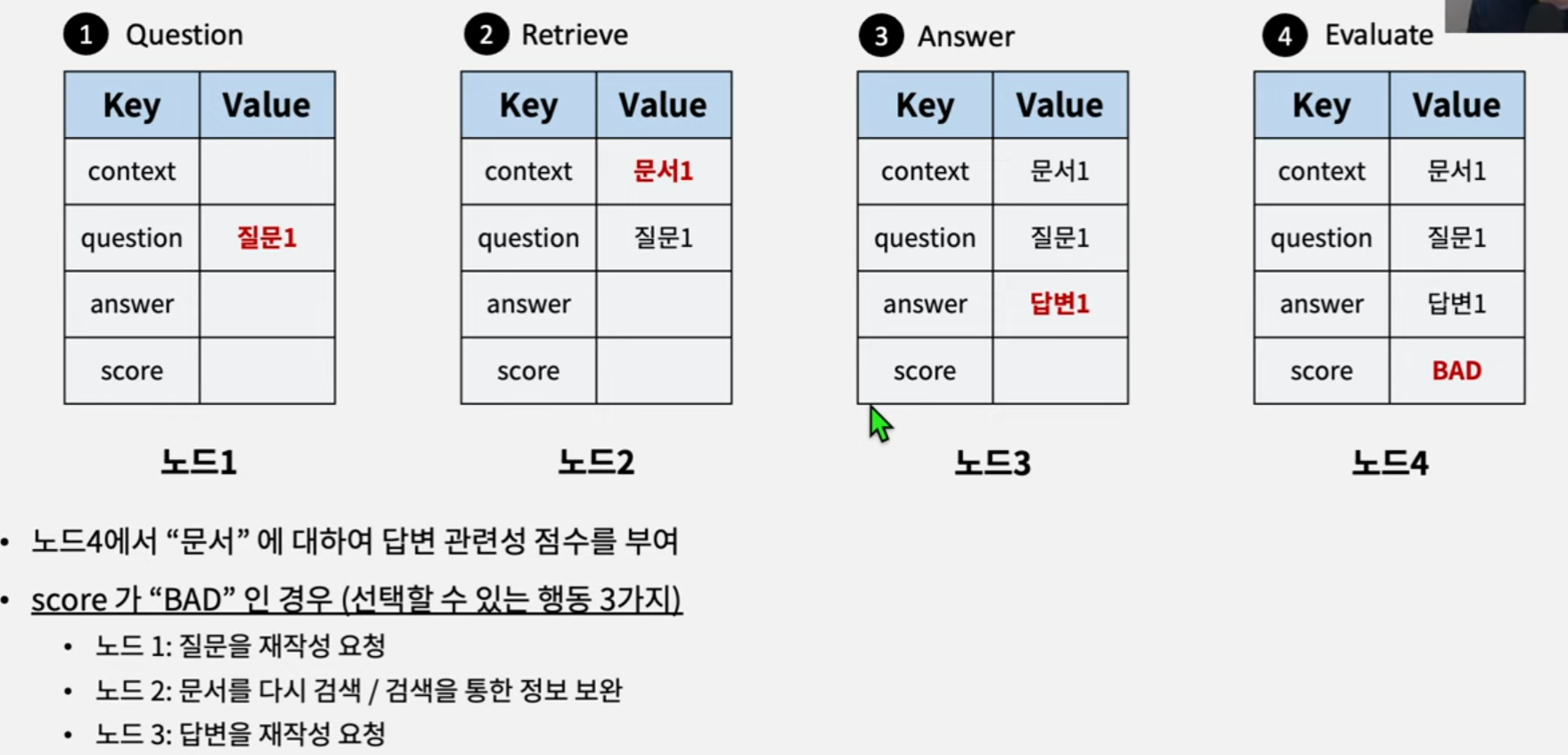
질문 재작성 요청할 경우, 노드4에서 노드1로만 엣지 연결 (Query Transform을 통해 질문 재작성)
문서 검색을 재요청할 경우, 노드4에서 노드2로만 엣지 연결 (Context Retrieval 조정 - chunk size, 다른 검색기, web search)
답변 재생성을 요청할 경우, 노드4에서 노드3으로만 엣지 연결 (프롬프트 조절, 다른 LLM 사용)
노드: 함수로 정의할 수 있음, 입력인자: 상태 객체, 반환: 대부분 상태 객체를 반환하며, Conditional Edge의 경우 다를 수 있음
def retrieve_document(state: GraphState) -> GraphState
# Question에 대한 문서 검색을 retriever로 수행
retrieved_docs = pdf_retriever.invoke(state=['question'])
# 검색된 문서를 context 키에 저장
return GraphState(context=format_docs(retrieved_docs))
Graph 생성 후 노드 추가
add_node('노드 이름', 함수)
from langgraph.graph import END, StateGraph
from langgraph.checkpoint.memory import MemorySaver
# langgraph.graph에서 StateGraph와 END를 가져옴
workflow = StateGraph(GraphState)
# 노드들을 정의한다.
workflow.add_node('retrieve', retrieve_document) # 에이전트 노드 추가
workflow.add_node('llm_answer', llm_answer) # 정보 검색 노드 추가
Graph 노드에서 노드 간 연결
add_edge('노드 이름', '노드 이름') # from 노드, to 노드
workflow.add_edge('retrieve', 'llm_answer') # 검색 -> 답변
workflow.add_edge('llm_answer', 'relevance_check') # 답변 -> 관련성 체크
조건부 엣지 추가
add_conditional_edges('노드 이름', 조건부 판단 함수, dict로 다음 단계 결정)
workflow.add_conditional_edges(
'relevance_check', # 관련성 체크 노드에서 나온 결과를 is_relevant 함수에 전달
is_relevant,
{
'grounded': END, # 관련성이 있으면 종료
'notGrounded': 'llm_answer', # 관련성이 없으면 다시 답변 생성
'notSure': 'llm_answer', # 관련성 체크 결과가 모호하면 다시 답변 생성
},
}
시작점 설정
set_entry_point('노드 이름')
workflow.set_entry_point('retrieve') # 시작점 설정
체크포인터 - 각 노드간 실행결과를 추적하기 위한 메모리 (대화 기록과 유사)
compile(checkpointer=memory) 지정하여 그래프 생성
# 기록을 위한 메모리 설정
memory = MemorySaver()
# 그래프 컴파일
app = workflow.compile(checkpointer=memory)
그래프 시각화
get_graph(xray=True).draw_mermaid_png()
display(
Image(app.get_graph(xray=True).draw_mermaid_png())
)
그래프 실행
Runnable Config에서 기본 설정 가능
- recursion_limit: 최대 노드 실행 개수 지정, 13인 경우 총 13개의 노드까지 실행
from langchain_core.runnables import RunnableConfig
# recursion_limit: 최대 반복 횟수, thread_id: 실행 ID (구분용)
config = RunnableConfig(recursion_limit=13, configurable={'thread_id': 'SELF-RAG'})
# GraphState객체 활성화
inputs = GraphState(question='삼성전자가 개발한 생성형 AI의 이름은 ?')
outputs = app.invoke(inputs, config=config)
print('Question: \t', output['question'])
print('Answer: \t', output['answer'])
print('Relevance: \t', output['relevance'])
Upstage 문서 관련성 체크
from rag.utils import format_docs
from langchain_upstage import UpstageGroundednessCheck
upstage_ground_checker = UpstageGroundednessCheck()
# 업스테이지 문서 관련성 체크 실행
upstage_gorund_checker.run(
{
"context": format_docs(
pdf_retriever.invoke('삼성전자가 개발한 생성AI의 이름은')
),
'answer': '삼성전자가 개발한 생성AI의 이름은 "빅스비 AI"입니다.',
}
)'AI > Natural Language Processing' 카테고리의 다른 글
| Spacy를 활용한 나만의 한국어 NER 모델 만들기 (1) (7) | 2024.11.06 |
|---|---|
| Self-RAG (실습) (1) | 2024.07.03 |
| Exploring RAG for Tables (실습) (0) | 2024.06.28 |
| Exploring Query Rewriting (실습) (0) | 2024.06.28 |
| Exploring Semantic Chunking (실습) (0) | 2024.06.26 |
블로그의 정보
코딩하는 오리
Cori