화자 구분, Speaker Diarization 연구 일지
by Cori개발중인 회의록 자동 작성 모델의 성능 개선이 필요해, 이 중 화자 구분 관련된 연구 내용을 여기에 기록한다. PoC (Proof of Concept) 과정에서는 STT (Speech To Text), Speaker Diarization 모두 자원상 한계로 인해 API를 활용해 구현하였고, 어찌저찌 통과가 되었으나, 성능이 썩 좋지는 않아 전체적인 고도화를 진행하게 되었다. 이 포스팅에서는 화자 구분의 기본 프로세스에 대한 개념과 구현 방안을 정리하고, 각 단계별 고도화 결과에 대한 비교 분석은 지면상 다른 포스팅에서 다룬다.
Section # 01. Speaker Diarization 이란 ?
주어진 음성 파일에서, 화자별 발언 시간을 계산하는 작업으로, 전통적인 화자 구분은 다음 그림과 같이 동작한다. 음성 파일이 입력으로 들어오면, 음성 감지 (Speech Activity Detection)를 수행하여 음성이 존재하는 구간에 대한 세그먼트를 얻는다. 이후, 세그먼트별 오디오 임베딩 벡터 값을 얻고, 얻은 값 각각을 비교하며 유사한 군집끼리 클러스터링한다. 이렇게 얻은 클러스터들에 대해 후처리를 진행하여, 화자 구분 결과값을 최종 반환한다.

음성 파일을 이용한 화자 구분 방식이 일반적이지만, 작년 구글에서는 텍스트(대화 기록)를 입력으로 받아 화자 구분을 수행하는 DiarizationLM 모델을 발표하기도 했다. 프롬프트를 통해 LLM에 전달하고 파싱을 진행하는 방식인데, 한글에 대해서는 성능이 기대 수준에 못 미칠거 같아 연구할 때는 논외로 두었다.

Section # 02. 단일 채널 화자 구분 vs 다중 채널 화자 구분
단일 채널은 하나의 마이크 또는 녹음기에서 수집한 음성 신호(모노, Mono)를, 다중 채널은 여러 마이크(스테레오, Stereo)로 동시에 수집한 다중 신호를 입력으로 받는다. "단일 채널 vs 다중 채널"의 기준은 녹음하는 '기기의 개수'가 아닌, '마이크 입력 채널 수'에 따라 결정된다. 하나의 기기 안에서도 마이크가 여러 개 달려 있으면 다중 채널 녹음이 가능하며, 대부분의 스마트폰은 하나의 주요 마이크 채널만 녹음하기에 단일 채널 녹음이라 볼 수 있다.

단일 채널의 경우 음성 파일에서 공간 정보 (위상, 방향 정보 등)를 활용할 수 없어 같은 시간에 여러 화자가 겹쳐 말하면 구분이 어렵다. 또한 배경 소음이나 잔향이 많으면 화자 특징(embedding)이 흐릿해져 "누가 어디서 말하는지" 알 수 없다.노트북, 태블릿, 스마트폰은 보통 다중 마이크로 구성되어 있지만, 실제로 녹음에 사용되는 채널은 보통 1개로 제한된다. 여러 스마트폰을 동시에 녹음하여 음성 파일을 여러 개 생성한 후, 이들을 멀티채널 wav 파일로 병합해서 다중 채널처럼 처리하는 방식도 가능하긴 하다. 다만 이 경우 시간 싱크가 맞지 않기에 후처리에서 alignment 작업이 추가로 필요하다.
다중 채널의 경우 오버랩된 화자도 공간적으로 분리가 가능하며, 화자의 위치에 따라 신호를 구분하기 때문에 더 정확한 화자 구분을 수행할 수 있다. 더 나아가 수행 배경 소음/잔향이 심한 환경에서의 성능 또한 단일 채널보다 우수하다. 다중 채널의 wav 파일은 하나의 파일 안에 여러 개의 채널(tracks)이 들어 있는 멀티채널 오디오 파일로, 무압축 형식(PCM)이며, 다음과 같이 모든 채널이 하나의 파일에 샘플 단위로 순차적으로 번갈아가며 저장된다.
# L: Channel 1, R: Channel 2, C: Channel 3
[ L R C ] [ L R C ] [ L R C ] ...다중 채널 오디오 파일은 다음과 같이 분할할 수 있다.
import soundfile as sf
data, sr = sf.read("multi_channel.wav") # data.shape = (샘플 수, 채널 수)
channel_1 = data[:, 0]
channel_2 = data[:, 1]
channel_3 = data[:, 2]반대로, 분할한 오디오 파일을 다음과 같이 다시 합칠 수 있다.
import numpy as np
import soundfile as sf
ch1, sr = sf.read("mic1.wav")
ch2, _ = sf.read("mic2.wav")
ch3, _ = sf.read("mic3.wav")
multi = np.stack([ch1, ch2, ch3], axis=1) # shape: (샘플 수, 3)
sf.write("merged_3ch.wav", multi, sr)
Section # 03. Front-end Processing
Front-end processing의 주요 목적은 입력 오디오의 품질을 향상시키고, 후속 처리 단계에서 정확도를 높이는 것이다. 주로 배경 소음 제거, 잔향 감소, 음성 분리 등을 적용한다
3.1 배경 소음 제거
배경 소음을 제거하고, 음성을 강조하는 방법론으로는 딥러닝 기반 접근 방식이 활발히 연구되고 있으며, 대표적으로 LSTM(Long Short-Term Memory) 기반의 노이즈 제거 모델과 Minimum Variance Distortionless Response (MVDR) Beamforming 방식 등이 있다.

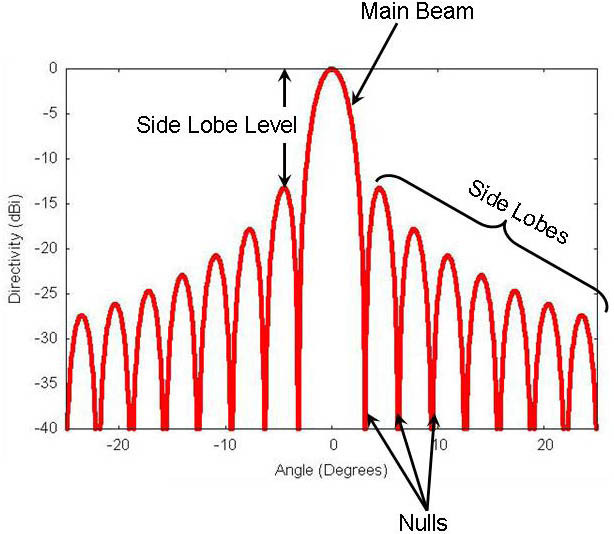
주파수 값 기반 소음 제거 방식은 가장 단순한 방식인만큼, 잡음과 음성이 겹쳐 있을 경우 효과적이지 않으며, 원하는 음성까지 손실이 발생할 수 있다.
- 저주파와 고주파 범위에서 특정 임계값(threshold)을 설정하여 필터링
- 일정 주파수(예: 100Hz 이하, 10kHz 이상)를 차단하거나 강조하는 방식
- 단일 채널(single-channel) 환경에서 효과적
LSTM 기반 노이즈 제거 방식은 LSTM(순환 신경망)을 이용해 시간 순서에 따른 음성-노이즈 패턴을 학습하고, 노이즈만 제거하기 때문에 정밀한 작업이 가능하지만 많은 연산량을 필요로 한다.
- 음성과 잡음의 복잡한 시간적 패턴을 학습 가능
- 음성과 비슷한 노이즈도 구별 가능
반면, MVDR Beamforming은 음성과 소음의 주파수가 겹쳐도 효과적인 소음 제거가 가능하며, 다중 채널 환경에서 잡음뿐만 아니라 반향 또한 감소시킬 수 있다. 뿐만 아니라 방향성 강한 소음 제거에 탁월하며 이러한 성능 덕분에, 실제 회의, 방송, 통화 환경에서 ASR 성능을 높이는데 많이 쓰인다.
- 다중 마이크(multi-microphone) 배열을 활용하여 특정 방향의 신호를 강조
- 주파수 영역이 아닌, 공간적 특성을 이용하여 잡음을 억제
- 화자의 음성 방향(도래 방향, Direction of Arrival)을 분석하고, 해당 방향의 신호를 증폭
- 동시에 주변 방향(배경 소음이 존재하는 영역)의 신호를 최소화
(AS-IS -> TO-BE) 주파수 기반 + LSTM 기반 노이즈 필터링 or MVDR Beamforming 적용
현재는 단일 채널 기반의 오디오 신호 처리만을 사용하고 있으며, 단순한 주파수 필터링 또는 RMS 기반의 임계값 마스킹 방식으로 배경 소음을 억제하고 있다. 이 방식은 구조가 간단하고 구현이 용이하다는 장점이 있지만, 화자 음성과 노이즈가 주파수 대역에서 겹치거나, 실내 잔향 및 배경 잡음이 복합적으로 포함된 경우에는 효과가 제한적이다.
성능 고도화를 위해, LSTM 기반 노이즈 제거 + 주파수 기반 필터링, 또는 MVDR Beamforming과 같은 공간 필터링 기법을 적용하여 음성 신호의 선명도 및 SNR을 향상시키는 방향으로 개선하려 한다. 다만 MVDR Beamforming 방식은 다중 채널에서 동작하는 알고리즘이기 때문에, 당장에 해당 방식을 적용하지는 않을 것 같다.
LSTM 기반 노이즈 억제 모델로는 SEGAN (Speech Enhancement GAN), Demucs (Facebook), NSNet2 (Microsoft, 실제 제품 일부 반영), MP-SENet (a TF-domain monaural SE model with parallel magnitude and phase spectra denoising) 등이 있으며, 여기서 여러 모델들을 사용해보며 테스트 해보고, 체감 성능이 가장 우수한 모델을 사용할 생각이다.
추가적으로, 노이즈 필터링을 살펴보며 잡음을 분리하는 방법도 괜찮을거 같아 좀 더 살펴보는 중인데, 이 부분은 여유가 있을 때 다뤄보려 한다. 일반적인 Speech Enhancement가 '입력 (음성 + 잡음) → [딥러닝 모델] → 깨끗한 음성'와 같이 동작한다고 했을 때, 잡음은 모델 내부적으로 제거되지만 출력되지 않는다고 한다. 구조를 살짝 바꿔 모델이 음성 + 잡음을 동시에 출력하도록 학습하거나, 전체 입력에서 모델이 예측한 음성을 빼면 잡음만 남는다는 느낌으로 잡음 제거가 가능하지 않을까 .. 라는 생각으로 접근해보려 한다.
3.2 잔향 감소 (Dereverberation)
잔향은 음성이 공간 내에서 반사되면서 발생하는 왜곡으로, 화자 구분 시스템의 정확도를 저하시킬 수 있다. 이를 해결하기 위해 WPE (Weighted Prediction Error) 기반 Dereverberation 기법이 널리 사용된다.
- 오디오 신호를 초기 반사 성분(Early Reflection)과 후반부 잔향 성분(Late Reverberation)으로 분리
- 후반부 잔향 성분을 제거하여 원래의 음성을 복원
초기 반사 성분 (Early Reflection)은 음성이 시작된 직후 짧은 시간 (보통 50ms~100ms) 동안 발생하는 1차 반사 벽이나 장애물에서 반사되어 약간의 왜곡이 생기지만, 원본 음성과 거의 유사한 특성을 가진다. 반면, 후반부 잔향 성분 (Late Reverberation)은 초기 반사 이후, 공간 내 여러 번 반사되며 점차 약해지는 신호 길게 지속되며 음성의 명확성을 떨어뜨린다. 이러한 특징은 ASR, 화자 구분 작업 등에서 중요한 정보를 손실시키는 주요 원인이 된다.
WPE는 다음과 같은 방식으로 후반부 잔향 성분을 제거한다.
Step 1. 입력 오디오에서 잔향 패턴 분석
- 수집된 음성 신호를 시간적 관계(과거 샘플과 현재 샘플의 영향)로 분석하고, 특정 지연 시간을 기준으로 잔향 예측
Step 2. Weighted Prediction Error 필터 적용
- 후반부 잔향 성분을 모델링한 후, 이를 제거하는 최적화 필터 적용하여 기존 음성 신호에서 깨끗한 음성을 복원한다.
Step 3. 출력 생성 (Dereverberated Speech)
- 원래의 음성 신호만 남기고, 잔향을 줄인 버전의 오디오 출력
한 문장이 2초 동안 녹음되었는데, 그 문장의 끝부분에서 "잔향 성분"이 0.5초 동안 남아 있다면, WPE는 그 0.5초의 잔향을 감지하고 제거하려고 한다. 반면 20분 가량의 오디오가 녹음되었다면, WPE는 전체 오디오를 짧은 프레임 (Short Segments, 1s~2s)으로 변환한다. 각 프레임에서 잔향 성분을 분석 및 예측, 제거 작업을 수행한 후 모든 프레임에서 이들을 다시 하나의 20분짜리 오디오로 복원한다.
(AS-IS -> TO-BE) WPE 도입
애초에 음성 파일 녹음 시, 반향 제거 부분은 생각지도 못했던 부분이다. 뒤늦게나마 이런 정보를 접하게 되었으니, 해당 모듈을 적용함으로써 음성 품질이 실제로 향상되는지 확인해보려 한다.
WPE 관련 파이썬 라이브러리에는 대표적으로 nara-wpe와 pyroomacoustics가 있다. 잔향 제거 성능을 높이는데에는 nara-wpe 라이브러리 성능이 우수하기에, 해당 라이브러리를 사용해서 오디오 전처리를 진행할 예정이다.
|
|
pyroomacoustics | nara-wpe |
| 목적 | 실내 음향 시뮬레이션 및 음성처리 전반 | 고성능 WPE 반향 제거 전용 |
| 주요 기능 | 음향 시뮬레이션, beamforming, WPE 포함 | WPE 알고리즘만 고도화 |
| WPE 정확도 | 일반적인 수준 (단순 구현) | SOTA 수준 정확도 및 정밀한 처리 |
| 처리 대상 | 단일 채널 / 멀티 채널 모두 가능 | 멀티채널에 특히 강함 |
| 성능 | 연구/실험에 적합, 다기능 | 실무형, 빠르고 안정적 |
| 확장성 | 다양한 음향 처리 기능 제공 | WPE 전용 라이브러리로 간결 |
3.3 Speech Separation
여러 명이 동시에 말하는 오버랩(overlapping speech) 환경에서 개별 화자의 음성을 분리하는 기술이다. 대표적으로 Beamforming 기반 다채널 음성 분리 방식이 있고, Single 채널의 경우 Conv-TasNet, Deep Clustering(DC), Permutation Invariant Training(PIT) 등의 딥러닝 기반 음성 분리 모델 적용되고 있다. 다만, 단일 채널의 경우 멀티 채널 기반 음성 분리 기법과 비교했을 때 공간적 정보를 활용할 수 없기 때문에, 오버랩된 음성을 완전히 분리하는 것이 어렵다.
단일 채널에서의 음성 분리 한계는 다음과 같다.
- 모든 소리가 단일 신호(mono)로 혼합되므로 공간 정보(위치 정보)가 손실됨
- 같은 주파수 대역에서 말하는 여러 화자를 구별하기 어려움
- 신경망 기반 Speech Separation 모델이 출력 순서를 보장하지 못하는 (퍼뮤테이션 문제, Permutation Invariant Training, PIT) 문제 발생
따라서 두 명 이상의 화자가 동시에 말하는 오버랩(overlapping speech) 환경에서는 성능이 급격히 저하되며, 특히 배경 소음이 강한 경우 노이즈와 음성을 구별하는 데 어려움이 생긴다.
반면, 다중 채널에서의 음성 분리는 다음과 같은 특성으로 인해 효과적이다.
- 각 마이크가 수집하는 신호에 공간적 차이(spatial cues, phase difference)가 발생
- 이러한 차이를 활용하여 화자의 위치를 기반으로 음성 신호를 분리할 수 있음
- Beamforming(MVDR) 같은 공간 필터링 기법을 적용하여 특정 방향의 화자 음성을 강조 가능
다중 채널에서 화자 분리를 할 경우 성능이 훨씬 향상되며, 배경 소음이 포함된 환경에서도 특정 화자의 음성을 강화하는 등 보다 섬세한 작업이 가능해진다.
(AS-IS -> TO-BE) 화자 분리 적용 (다중 채널에서 진행할 경우)
현재 개발중인 상품은 하이퍼클로바 같이 단일 채널에서도 동작 가능하는 모듈을 만드는 것이기에, 화자 분리 모듈은 MVDR Beamforming과 마찬가지로 추가 고려하지 않을 것 같다. 다만, 이후 다중 채널로 서비스가 확장하게 된다면 해당 부분을 적용해볼 생각이며, 관련 내용도 다뤄보도록 하겠다.
4. Speech Activity Detection
SAD (Speech Activity Detection)는 VAD (Voice Activity Detection)라고도 불리며, 음성과 배경 잡음과 같은 비음성을 구분하는 역할을 한다. SAD는 화자 분리뿐만 아니라 화자 인식 및 음성 인식 시스템에서도 중요한 역할을 하며, SAD 단계에서의 오류는 이후 단계까지 오류를 전파시킬 수 있다. SAD 시스템은 크게 음향 특징을 추출하는 전처리(front-end) 부분과 분류기(classifier) 단계로 구분할 수 있다.
전처리 부분에서는 영점 교차율(zero crossing rate), 피치(pitch), 신호 에너지 (signal energy), 선형 예측 코딩 잔차 도메인에서의 고차 통계량, MFCC(Mel-Frequency Cepstral Coefficients) 와 같은 음향 특성이 자주 사용된다. 반면, 분류기 부분에서는 과거 기존에는 스펙트럼 기반 통계 모델, 가우시안 혼합 모델(GMM)등과 같은 방법들을 주로 사용하다 딥러닝이 음성 신호 처리 분야에서 각광을 받기 시작하면서, LSTM (장기 단기 기억 네트워크) 등을 기반으로 한 서비스가 제안되었다.
(AS-IS -> TO-BE)
SAD 모델은 오디오 파일에서 음성이 존재하는 영역을 탐지하는 중요한 부분으로, 기존에는 STT 적용 시 음성이 없는 구간까지 STT를 적용했다면 이후 서비스에서는 음성이 존재하지 않는 구간은 STT 모델에 전달하지 않는 방식으로 구현하려 한다. 아무래도 STT 모델이 생성형이다 보니, 음성이 존재하지 않는 구간에서 이상한 말을 생성하는 경향이 강한데, 파라미터 필터링을 적용해도 걸러내지 않는 경우가 종종 있다보니 SAD 도입은 필수적이라고 본다.
반면 화자 구분에서는 기본적으로 파이프라인에 SAD 기능이 탑재되어 있어 필수적으로 추가 구현이 필요하다 볼 수 없겠으나, 놓치는 구간에 대한 교차 검증 정도로 활용해볼 수 있을 것 같다.
5. Segmentation
Segmentation은 오디오 스트림을 화자가 같다고 판단되는 구간(segment)으로 나누는 과정으로, 이렇게 나뉜 구간은 이후 임베딩 추출과 클러스터링의 입력이 되며, 결국 화자 분리 시스템의 출력 단위를 결정하게 된다.
초기 화자 분리 시스템은 화자가 바뀌는 지점을 감지해 segment를 나누는 방식으로 진행되었다. 해당 방식은 두 개의 창(window)을 비교하면서, 동일 화자인지(H₀) 또는 다른 화자인지(H₁)를 판단하며, BIC (Bayesian Information Criterion) 기법이 대표적이다. BIC는 각 구간의 음성 특징이 가우시안 분포를 따른다고 가정하며, 전체 구간 vs 나눠진 두 구간의 BIC 값을 비교하여 특정 지점에서 BIC 값이 0보다 크면 화자가 바뀌었다고 판단한다. 이러한 방식은 구간의 길이가 제각각이기 때문에, 임베딩의 일관성을 해치는 단점이 있다.
최근에는 딥러닝 기반 임베딩 기법(i-vector, DNN 등)이 도입되면서, 균등한 길이로 잘라서 처리하는 방식이 더 많이 사용 되고 있다. 오디오를 고정된 윈도우 길이와 오버랩으로 나누면 결과적으로 화자 분리 출력 단위도 일정하게 유지된다. 해당 방식도 여전히 단점이 존재하는데, 구간이 너무 짧으면 화자 혼합 방지는 좋지만, 정보가 부족해 임베딩이 불안정하고, 구간이 너무 길면 풍부한 정보는 있지만, 하나의 구간에 여러 화자가 섞일 위험이 있어 적절한 크기의 윈도우를 설정하는 것이 중요하다고 볼 수 있다.
얼핏 보면 Segmentation 작업과 VAD 작업이 비슷하다 느껴질 수 있는데, VAD는 단순히 음성 파일의 어디부터 어디까지 음성이 있음 !! 을 알려주는 역할을 한다. 반면, Segmentation은 음성이 존재하는지 여부를 파악하는 것에서 더 나아가, 화자가 전환되는 지점을 탐지하는 것에 보다 중점을 둔다. VAD에서 10~80초까지를 음성이 존재하는 구간으로 잡았다면, Segmentation을 통해 10~20초까지의 화자와 20~40초까지의 화자가 다르다는 것을 파악해 보다 세분화된 구간으로 분리한다. VAD를 건너뛰고, Segmentation만 하면 더 효율적이지 않냐라고 한다면 꼭 그렇지만도 않다. 전체 오디오에 Segmentation 모델을 적용하면 연산량이 커지기 때문에, VAD를 먼저 돌려서 무음 구간은 제하고, 나머지 부분에 대해서만 Segmentation을 적용하는 것이 보다 효율적이다.
* 정리 과정에서 헷갈리는 점이 있었는데, 바로 Pyannote의 Segmentation backbone 모델로 인한 혼동이다. VAD 모델에서 Segmentation 모델을 사용해 음성이 존재하는 구간을 탐지하는데, VAD 이후에 또 Segmentation을 적용한다고 하길래 그럼 VAD에서 처리하는 Segmentation 모델과 이후에 사용하는 Segmentation 모델은 서로 다른 모델인가 ? 라는 생각이 얼핏 들었다.
결론부터 말하자면, VAD에서든, Diarization에서든 Segmentation에 사용하는 모델은 서로 같은 모델이다. 하지만 역할과 후처리 방식이 다르기 때문에, Segmentation 단계에서 뭘 하냐는 전혀 다를 수 있다. VAD 과정에서 사용하는 Segmentation은 음성 vs 무음 구분으로, threshold, min_duration_on/off 등으로 이진 분류한다. 반면 화자구분 파이프라인에서 적용하는 Segmentation은 화자 전환 경계 탐지로, 이를 위해 모델의 soft output을 유지한다.
Segmentation 모델을 직접 사용해서 화자가 바뀐 지점 (speaker change points) 를 탐지하는 건 Pyannote speaker diarization의 핵심 기술 중 하나로, 다음과 같은 방식으로 이루어진다. 우선 segmentation 모델로 frame 단위 posterior를 추출하고, posterior 간 유사도를 계산하여 변화가 급격한 시점을 speaker change point로 탐지한다. 사용자는 이 구간을 이 지점을 기준으로 구간을 분리할 수 있으며, 화자가 바뀌었다고 보게 된다.
** 이 과정에서 또 하나의 헷갈리는 점이 발생했는데, Segmentation 모델에서 사용하는 유사도 검사와 화자 임베딩 값을 활용한 유사도 검사는 서로 어떤 차이가 있는 것인지가 궁금해졌다. 알아보니, Segmentation 3.0 모델을 활용해 화자 전환 탐지를 위해 진행하는 유사도 검사는 frame 단위 (10~16ms)를 입력으로 받아, 프레임별 speaker activation (score vector)를 반환하여 이들간 유사도를 계산한다. 즉, 시간적으로 연속된 프레임 벡터를 비교해서 유사도가 낮아지면 화자가 바뀐 것 같다고 판단한다. 반면, 임베딩 기반 유사도 검사는 각 세그먼트를 하나의 고정된 임베딩 벡터로 변환 후, 이 벡터 간 유사도(cosine distance 등)를 직접 비교해서 같은 화자인가를 판단한다.
정리하자면, 연속된 프레임에서 갑자기 확 바뀌는 프레임이 있다 ! 는 Segmentation 모델 기반으로 화자 변환 탐지를 진행하는 것이고, 2개의 음성 파일이 있는데 이 둘 간 화자가 같을 확률은 ? 같은 화자 동일 여부 판단/검증은 임베딩 모델 기반으로 검증한다고 할 수 있다.
(AS-IS -> TO-BE) Segmentation 모듈 구축
Segmentation은 화자 분리에서 '언제' 말했는지를 구분하는 가장 첫 단계로, 이후의 임베딩/클러스터링 성능까지 좌우하는 중요한 전처리 기술이라 할 수 있다. 이전에는 이런 모듈별 구현체가 없었기에, 고도화 과정을 통해, Segmentation 모듈을 구축하고 검증하는 과정을 가져보려 한다.
... 이 과정에서 문제가 살짝 발생했는데, 현재 서비스를 내부망 환경에서 구축하고 있기에 허깅페이스 허브에 연결하지 않아야 한다. VAD, Speaker Diarization, Overlapped Speech Detection 등의 파이프라인은 .bin 파일만 있으면 인터넷 연결이 없어도 구현이 가능했던 반면, Speech Seperation 파이프라인은 잘 동작하지 않았다. 그 이유는 즉슨 해당 파이프라인이 세그먼테이션 모델의 specifications 속성을 내부에서 직접 참조하기 때문인데, 다른 모델들(VAD, Speaker Diarization 등)은 세그먼테이션 모델을 로드할 때 내부적으로 모델 구조나 하이퍼파라미터를 직접 참조하지 않기에 동작에 문제가 없었던 것이다. 그럼에도 불구하고 굳이 사용해야겠다면 직접 모델을 불러서 커스터마이즈해야 하는데, 이 작업까지 하기에는 너무 복잡해지기에, 해당 모듈 구현은 일단 보류하게 되었다.
6. Speaker Embedding
화자 표현 방식 (x-vector, i-vector)이 등장하기 전에는 Metric 기반 방식(KL divergence, Bayesian Information Criterion: BIC 등), Factor Analysis 기반 방식(Gaussian Mixture Model - Universal Background Model: GMM-UBM, Joint Factor Analysis: JFA, i-vector + PLDA 등)으로 화자를 특정짓곤 했다. DNN 기반의 representation 학습 방법이 등장하면서, 오디오와 같은 입력 신호를 밀집 벡터(embedding)로 변환하여 화자 표현을 얻기 시작했다. Factor Analysis 방식과 달리 명시적 분해나 확률적 모델링이 필요 없고, 연산 효율성 및 성능이 뛰어나다.
d-vector는 대표적인 딥러닝 기반 화자 임베딩 프레임워크 중 하나로, 입력 특징으로는 context frame이 포함된 stacked filter bank를 사용하고, 여러 개의 fully-connected 층을 cross-entropy loss로 학습한다. 최종적으로 마지막 layer의 출력을 d-vector로 사용한다. 해당 기법은 초기 대표적인 DNN 기반 방법으로 널리 사용되었으며, 구조를 살펴보면 다음과 같다.

x-vector는 Time-delay neural network (TDNN) 아키텍처를 사용한 모델로, 그림과 같이 통계 풀링(statistics pooling) 계층을 포함시켰다. 통계 풀링 계층은 이전 계층의 프레임 단위 출력을 모두 모아서 평균과 표준편차를 계산하여 다음 계층에 전달하는데, 덕분에 입력 길이가 가변적인 오디오에 대해서도 일관된 크기의 임베딩을 추출할 수 있다. 이러한 특성은 화자 검증뿐만 아니라, 화자 구분에도 매우 유리하다 볼 수 있는데, 특히 발화 끝에서 segment가 잘리는 경우와 같이 길이가 제각각인 구간들을 처리해야 할 때 큰 장점이 있다.
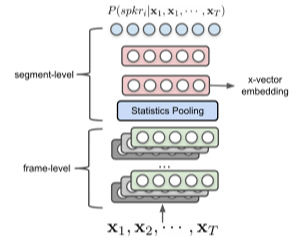
x-vector는 d-vector보다 성능이 더 우수한 임베딩 방법으로, 2018년 NIST 화자 인식 챌린지와 DIHARD 화자 분리 챌린지에서 우수한 성적을 거두었다.
(AS-IS) 다행히 x-vector 기반의 임베딩 모델들이 여러 오픈 소스로 공개되어 있어, 이 모델들을 활용해 음성 데이터에서 화자별 벡터값을 추출하는 작업을 진행할 예정이다. 대표적인 예시로는 SpeechBrain에서 공개한 spkrec-xvect-voxceleb 모델과 Google의 google_speech_command_xvector 모델이 있다. 특히 Pyannote에서 화자 구분 모델로 사용하는 임베딩이 바로 SpeechBrain의 spkrec-xvect-voxceleb 모델이기 때문에, Pyannote 기반의 화자 구분 서비스를 제공하려는 우리 시스템에서도 이 모델을 사용하는 것이 가장 적합할 것으로 보인다.
** (2025.04.18) 추가로 조사해보니, Speechbrain에서 공개한 speechbrain/spkrec-ecapa-voxceleb 모델의 임베딩 성능이 더 우수하다고 하여, 해당 모델을 사용하려 한다.
추가로, 40분 이상의 긴 오디오 파일을 청크 단위로 나누지 않고 화자 구분을 수행하면 성능이 떨어진다는 사실을 확인하였다. 따라서 일반적으로 긴 오디오를 일정 길이의 청크(chunk) 단위로 분할하여 각각의 청크에서 화자 구분을 수행한다. 다만, 청크 단위로 화자 구분을 진행하면 각 청크의 화자 정보가 서로 독립적이므로, 전체 오디오에서 일관된 화자 정보를 얻기 위해서는 임베딩 벡터를 이용하여 서로 다른 청크들 사이의 화자를 매핑(mapping)해주는 작업이 필요하다. 본 시스템에서도 이러한 용도로 임베딩 벡터를 활용할 예정이다.
7. Clustering
8. Evaluation Metrics
Reference
[1] Park, Tae Jin, et al. "A review of speaker diarization: Recent advances with deep learning." Computer Speech & Language 72 (2022): 101317.
[4] Speech Recognition & Diarization
[5] How can I apply a filter to remove reverberation with python?
[6] nsnet2-denoiser
[7] demucs
'AI > Audio Processing' 카테고리의 다른 글
| 현 시점, 화자 구분 문제점 (0) | 2025.07.15 |
|---|---|
| 화자 구분 후처리, Post Processing 작업 일지 (0) | 2025.04.30 |
| 화자 임베딩, Speaker Embedding 작업 일지 (1) | 2025.04.22 |
| 음성 탐지, Voice Activity Detection 작업 일지 (2) | 2025.04.16 |
| 오디오 전처리, Front-end Processing 작업 일지 (5) | 2025.04.10 |
블로그의 정보
코딩하는 오리
Cori