화자 구분 후처리, Post Processing 작업 일지
by Cori회의록 서비스 성능 고도화 프로젝트의 일환으로, 이전 포스트에서 설명한 화자 구분 프로세스 중 Post Processing 과정을 여기에 기록한다. Post Processing은 화자 구분 결과값을 후처리하는 역할을 수행하며, 오디오 파일에서의 잡음 필터링, 화자별 순수 발화 추출, 화자 재레이블링, 청크별 화자 대표 임베딩 계산 및 전체 병합하는 부분을 다룬다.
1. 잡음 필터링
화자 구분 모델을 적용해보면, 발화 시간이 매우 짧은 구간조차도 특정 화자로 분류되는 경우를 자주 확인할 수 있다. 해당 구간의 오디오를 실제로 들어보면, 대부분은 단순한 추임새나 잡음에 가까운 경우가 많으며, 이러한 발화는 전체 대화 흐름에서 중요한 정보로 작용하지 않는 경우가 대부분이다. 또한 발화 길이가 짧을수록, 화자 구분 모델이 올바른 화자를 추정하기 어려워질 가능성이 높다. 결과적으로 이러한 구간들이 잘못된 화자 레이블로 포함되면, 실제보다 많은 수의 화자가 존재하는 것처럼 인식되는 문제로 이어질 수 있다.
SPEAKER chunk_0_20250211 1 4.013 6.868 <NA> <NA> SPEAKER_01 <NA> <NA>
SPEAKER chunk_0_20250211 1 10.882 5.332 <NA> <NA> SPEAKER_02 <NA> <NA>
SPEAKER chunk_0_20250211 1 16.450 1.316 <NA> <NA> SPEAKER_01 <NA> <NA>
SPEAKER chunk_0_20250211 1 18.003 3.223 <NA> <NA> SPEAKER_02 <NA> <NA>
SPEAKER chunk_0_20250211 1 20.112 1.924 <NA> <NA> SPEAKER_01 <NA> <NA>
SPEAKER chunk_0_20250211 1 26.677 6.750 <NA> <NA> SPEAKER_01 <NA> <NA>
SPEAKER chunk_0_20250211 1 29.022 0.928 <NA> <NA> SPEAKER_00 <NA> <NA> - 추임새, 네네..
SPEAKER chunk_0_20250211 1 30.828 0.388 <NA> <NA> SPEAKER_03 <NA> <NA> - 추임새, 그...
SPEAKER chunk_0_20250211 1 42.100 1.485 <NA> <NA> SPEAKER_01 <NA> <NA>여러 오디오 파일을 수집하여 화자 구분 모델을 적용해본 결과, 0.8초에서 1초 이하의 짧은 발화 구간에서 주로 추임새나 잡음 같은 비의미 발화가 감지되는 경향을 확인할 수 있었다. 이에 따라 해당 구간을 특정 화자가 아닌 filler라는 별도의 레이블로 분류하도록 처리하였다. 이러한 조치는 특히 짧은 발화 구간이 새로운 화자로 오인되어, 전체 예측 화자 수가 실제보다 과대 추정되는 문제를 효과적으로 완화하는 데 도움이 되었다. 예를 들어, 다음은 발화 시간이 1초 미만인 SPEAKER_02가 filler로 필터링되어 최종 결과에서 제외된 사례이다.

2. 화자별 순수 발화 추출
화자 구분 모델의 핵심은, 각 화자의 고유 음성 특성을 정확히 반영한 임베딩을 추출하여 이를 기반으로 화자를 구분하는 데 있다. 그러나 실제 대화에서는 두 명 이상의 화자가 동시에 발화하거나, 발화 구간이 일부 겹치는 상황(overlap)이 빈번하게 발생한다. 이러한 경우에도 대부분의 화자 구분 모델은 각 구간을 독립적으로 처리하여 임베딩을 계산하기 때문에, 해당 구간에서 추출된 임베딩에는 복수 화자의 음성 정보가 혼합되어 포함될 가능성이 있다. 다음은 이러한 상황을 잘 보여주는 화자 구분 결과 파일이다.
SPEAKER chunk_0_20250324 1 136.702 5.873 <NA> <NA> SPEAKER_00 <NA> <NA>
SPEAKER chunk_0_20250324 1 138.946 1.806 <NA> <NA> SPEAKER_01 <NA> <NA>
SPEAKER chunk_0_20250324 1 141.865 10.176 <NA> <NA> SPEAKER_01 <NA> <NA>
SPEAKER chunk_0_20250324 1 143.300 0.540 <NA> <NA> filler <NA> <NA>
SPEAKER chunk_0_20250324 1 144.464 0.607 <NA> <NA> filler <NA> <NA>
SPEAKER chunk_0_20250324 1 145.966 0.388 <NA> <NA> filler <NA> <NA>
SPEAKER chunk_0_20250324 1 147.400 4.590 <NA> <NA> SPEAKER_00 <NA> <NA>
SPEAKER chunk_0_20250324 1 153.982 1.620 <NA> <NA> SPEAKER_01 <NA> <NA>136.7초부터 142초, 그리고 141.8초부터 152초까지 특정 화자가 발화하는 도중, 다른 화자가 겹쳐서 말하는 구간이 포함되어 있는 것을 확인할 수 있다. 이러한 구간에서 추출된 임베딩은 특정 화자의 고유한 음성 특징만을 반영하기 어렵기 때문에, 후속 처리 과정에서 화자 간 경계가 모호해지거나 잘못된 클러스터링이 발생할 수 있다.
보다 정확한 화자별 임베딩 값을 획득하기 위해, 본 연구에서는 화자 구분 결과 중 단일 화자의 발화와 다른 화자(또는 filler)의 발화가 겹치는 경우, 해당 구간을 제외하는 후처리 작업을 수행하였다. 앞의 예시에 오버랩 구간 필터링을 적용한 결과는 다음과 같다.
SPEAKER chunk_0_non_overlapped_20250324 1 136.702 2.244 <NA> <NA> SPEAKER_00 <NA> <NA>
SPEAKER chunk_0_non_overlapped_20250324 1 140.752 1.114 <NA> <NA> SPEAKER_00 <NA> <NA>
SPEAKER chunk_0_non_overlapped_20250324 1 142.574 0.726 <NA> <NA> SPEAKER_01 <NA> <NA>
SPEAKER chunk_0_non_overlapped_20250324 1 143.840 0.624 <NA> <NA> SPEAKER_01 <NA> <NA>
SPEAKER chunk_0_non_overlapped_20250324 1 145.072 0.894 <NA> <NA> SPEAKER_01 <NA> <NA>
SPEAKER chunk_0_non_overlapped_20250324 1 146.354 1.046 <NA> <NA> SPEAKER_01 <NA> <NA>
SPEAKER chunk_0_non_overlapped_20250324 1 151.990 0.051 <NA> <NA> SPEAKER_01 <NA> <NA>
SPEAKER chunk_0_non_overlapped_20250324 1 153.982 1.620 <NA> <NA> SPEAKER_01 <NA> <NA>겹치는 발화 구간을 기준으로 화자별 타임라인이 분리된 모습을 확인할 수 있으며, 특히 147초부터 151.99초까지의 SPEAKER_00 발화가 SPEAKER_01의 발화 구간과 완전히 겹쳐 제거된 것을 예로 들 수 있다. 단, 이러한 구간 제외 처리는 화자별 순수 임베딩을 계산하는 과정에서만 적용되며, 그 외의 구간 병합, 최종 클러스터링 등 다른 처리 단계에서는 기존 화자 구분 결과를 그대로 유지한다.
3. 화자 재레이블링
앞선 과정을 통해, 각 파일에서 화자별 순수 임베딩 값들을 획득할 수 있게 되었다. 이렇게 얻은 값은 1차적으로 적용했던 화자 구분 모델의 화자별 임베딩 값과 차이가 존재하기 때문에, 화자 정보를 재레이블링 해주는 과정이 필요하다. 이전 포스트, Speaker Embedding 작업 일지에서 잠깐 살펴본 바와 같이, 청크별 순수 화자별 임베딩 값을 저차원 공간에서 시각화하면 다음과 같다.
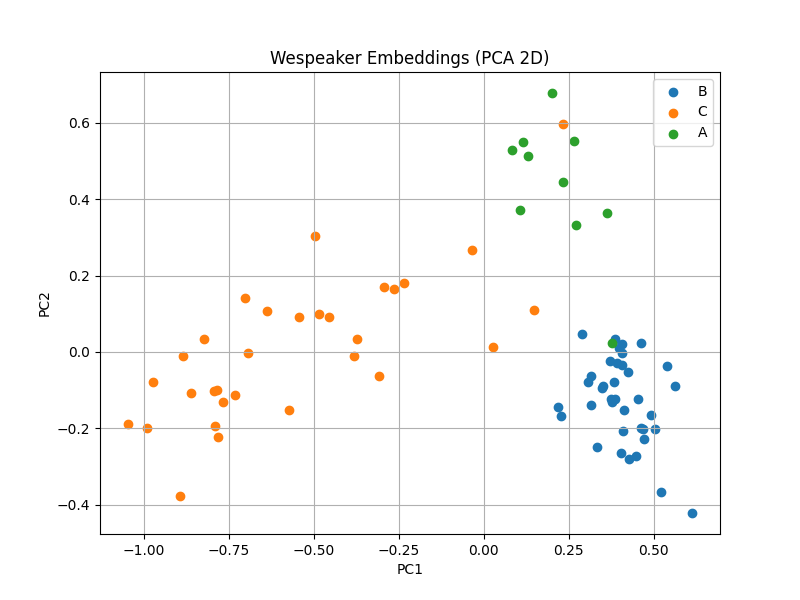

화자 구분 모델이 예측한 결과를 보면, 화자 C(주황)의 일부 임베딩이 화자 A(초록) 근처에 분포하고, 화자 A의 일부 임베딩이 또 다른 화자인 B(파랑)와 인접한 영역에 위치하는 현상을 확인할 수 있다. 이러한 현상이 발생한 원인을 추정해보면 다음과 같다. 예를 들어, 아래와 같은 화자 구분 결과가 있다고 해보자.
SPEAKER chunk_0_overlapped_20250324 1 0 10 <NA> <NA> SPEAKER_01 <NA> <NA>
SPEAKER chunk_0_overlapped_20250324 1 3 15 <NA> <NA> SPEAKER_00 <NA> <NA>
SPEAKER chunk_0_overlapped_20250324 1 12 10 <NA> <NA> SPEAKER_02 <NA> <NA>표면적으로는 0초부터 10초까지의 발화가 SPEAKER_01로 라벨링되어 있지만, 실제로는 3초 이후 대부분의 구간에서 SPEAKER_00이 함께 발화하고 있는 상태다. 이 경우, SPEAKER_01의 순수 발화만을 기준으로 임베딩을 추출하면, 실제 발화량이 적고 구간이 짧기 때문에 임베딩이 다른 화자(SPEAKER_00)의 분포에 더 가깝게 나타날 수 있다. 결국, 레이블은 SPEAKER_01로 되어 있지만, 임베딩 자체는 SPEAKER_00의 특성을 더 많이 반영하게 되는 현상이 발생하는 것이다.
이처럼 overlap 구간이 포함된 경우, 화자 레이블과 임베딩 벡터 간의 불일치가 발생할 수 있으며, 이는 곧 클러스터링 결과의 왜곡이나 화자 수의 과대 추정으로 이어질 가능성이 있다. 따라서, 보다 정확한 화자 임베딩을 얻기 위해서는 순수 발화 구간만을 대상으로 임베딩을 추출하는 후처리 과정이 필수적이다. 본 연구에서는 이러한 문제를 보완하기 위해, KNN 기반의 재레이블링 기법을 적용하여 임베딩 라벨의 정합성을 높였다.

4. 청크별 화자 대표 임베딩 계산 및 결과 병합
전체 오디오 파일의 길이가 긴 경우, 전체 구간을 한 번에 대상으로 화자 구분을 수행할 경우 성능이 저하되는 현상이 종종 발생한다. 이러한 현상은 시간에 따라 화자의 발화 특성이 미묘하게 변화하거나, 노이즈 환경, 말투, 말속도 등의 조건 변화가 누적됨에 따라, 모델이 일정 시점 이후의 발화를 초기 발화와 동일 화자로 인식하지 못하는 경우가 발생하기 때문이다. 또한, 대부분의 화자 임베딩 기반 모델은 짧은 고정 길이의 세그먼트 단위로 임베딩을 계산하고, 이를 클러스터링하는 구조를 가지므로, 세그먼트 수가 지나치게 많아질 경우, 화자 간 경계가 모호해지고 클러스터링 품질이 저하될 가능성이 커진다.
이에 따라 본 연구에서는 전체 오디오 파일을 논리적인 청크 단위로 분할한 뒤, 각 청크에 대해 독립적으로 화자 구분 및 재레이블링을 수행하고, 청크별로 화자의 대표 임베딩(mean embedding)을 추출한다. 대표 임베딩은 해당 청크에서 등장한 화자별 타임라인 임베딩의 평균으로 계산하며, 청크 간 유사도가 높은 화자끼리 화자 정보를 매핑함으로써, 최종적인 화자 구분 결과를 완성한다.
'AI > Audio Processing' 카테고리의 다른 글
| 현 시점, 화자 구분 문제점 (0) | 2025.07.15 |
|---|---|
| 화자 임베딩, Speaker Embedding 작업 일지 (1) | 2025.04.22 |
| 음성 탐지, Voice Activity Detection 작업 일지 (2) | 2025.04.16 |
| 오디오 전처리, Front-end Processing 작업 일지 (5) | 2025.04.10 |
| 화자 구분, Speaker Diarization 연구 일지 (0) | 2025.03.27 |
블로그의 정보
코딩하는 오리
Cori