화자 임베딩, Speaker Embedding 작업 일지
by Cori회의록 서비스 성능 고도화 프로젝트의 일환으로, 이전 포스트에서 설명한 화자 구분 프로세스 중 Speaker Embedding 적용 과정을 여기에 기록한다. 프로젝트를 진행하며 2가지 임베딩 모델(Wespeaker, Speechbrain)을 사용해 보았으며, 여기서는 두 모델 간 차이점을 비교 분석하고, 임베딩 모델을 화자 구분 파이프라인에 어떻게 적용하는지 설명한다.
0. Speaker Embedding 모델
프로젝트를 진행하며 2가지 Speaker Embedding 모델을 사용해보았다. 첫 번째 모델은 화자 구분 파이프라인에서 주축을 이루는 Pyannote에서 사용하는 임베딩 모델로, 'Wespeaker/wespeaker-voxceleb-resnet34-LM'이다. ResNet34-LM 모델은 r-vector를 기반으로 하고 있으며, voxceleb-resnet34-LM 모델은 5994명의 화자를 포함하고 있는 VoxCeleb2 Dev 데이터세트에 대해 학습되었다고 한다. 두 번째 모델은 Speechbrain 에서 공개한 임베딩 모델로, ECAPA-TDNN (SOTA) 구조를 사용하는 고품질 임베딩 모델로, Voxceleb 1+ Voxceleb2 training data를 사용하여 학습되었다.


두 모델의 자세한 차이는 나에게 엄청 중요한 것은 아니었기에, AI(ChatGPT)의 힘을 빌려 정리해보았다.

이제부터 두 모델의 임베딩 성능을 실무적인 관점에서 비교 분석해보자.
1. Speaker Embedding 모델
일단 들어가기에 앞서, Wespeaker의 문제점을 발견했다. Pyannote의 Wespeaker는 몰라도, Wespeaker Github에서 제공하는 모델은 지원하는 언어 목록이 'Chinese, English' 2개만 있다는 것이다. 한국어를 지원하지는 않더라도, 음성의 임베딩 벡터는 뭐 .. 언어의 의미를 정확히 몰라도 되니까 .. 사용할 수는 있겠지 싶은 마음으로 language 값을 english로 두고 테스트를 진행했다.
동일 오디오 파일에 대해 화자 구분 결과를 돌려서, 화자별 타임라인을 얻고, 동일한 화자가 발언한 5초 정도의 오디오 파일 2개를 얻었다. 얻은 오디오 파일을 각각의 모델에 전달해서 다음과 같이 임베딩 형태와, 유사도를 계산해보았다.
Speechbrain emb shape: torch.Size([1, 1, 192])
Wespeaker emb shape: torch.Size([256])
Speechbrain emb similarity: 0.729
Wespeaker emb similarity: 0.577Speechbrain 모델의 임베딩 값은 [1, 1, 192] (batch size, channel num, feature dim) 형태를 띄고 있으며, Wespeaker 모델의 임베딩 값은 256차원인 것을 볼 수 있다(Pyannote에서 화자 구분 수행 시 return_embedding=True를 설정했을 때 얻는 임베딩도 256차원이다). 그리고 동일 화자에 대한 임베딩 값을 계산했을 때, 유사도를 보다 높게 계산한 모델은 Speechbrain의 임베딩 모델인 것을 확인할 수 있었다.
테스트에 사용한 음성 파일에는 여성 1명, 남성 2명이 등장하는데, 서로 비슷한 음역대를 가진 남성 A, B 간 유사도를 각 모델이 어떻게 계산하는지 확인하기 위해, 남성 A가 발언한 3초동안의 구간과 남성 B가 발언한 7초 가량의 구간을 잘라서 임베딩 모델에 전달해보았다.
Speechbrain emb similarity: 0.836
Wespeaker emb similarity: 0.267SpeechBrain 모델의 임베딩 유사도가 0.83, Wespeaker 모델의 임베딩 유사도가 0.26으로 잡힌 것을 볼 수 있는데, 여기서부터 SpeechBrain 모델의 성능에 대한 의구심이 생기기 시작했다. 혹시 몰라 여성 A가 발언한 7초 가량의 구간과 남성 B가 발언한 7초 가량의 구간에 대해서도 테스트를 진행해보았다.
Speechbrain emb similarity: 0.716
Wespeaker emb similarity: 0.199성별이 다른 오디오 파일에 대해 임베딩 값을 계산해본건데, Speechbrain의 임베딩 유사도가 상당히 높게 나왔다. 이번에는 남성 A가 발언한 구간과 남성 B가 발언한 구간을 잘라 테스트를 진행해보았다.
Speechbrain emb similarity: 0.701
Wespeaker emb similarity: 0.299항상 Speechbrain은 높게 나오고, Wespeaker는 낮게 나오는건가 ? 싶어서 동일 화자에 대해 테스트를 해보았다.
Speechbrain emb similarity: 0.716
Wespeaker emb similarity: 0.435혼란하다 혼란해 .. 청크한 오디오 파일의 품질 문제 때문인가 싶어, 발화가 겹치는 구간은 모두 제거한 타임라인을 구하여 다시 한번 테스트를 진행해보았으나, 이전과 별 다를바 없는 결과를 얻었기에 추가로 설명하지는 않겠다.
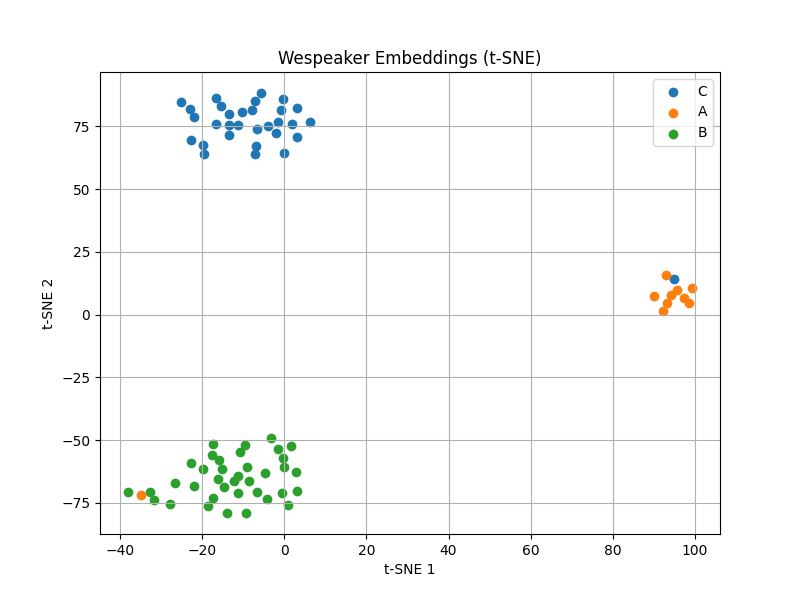
어떤 임베딩 모델을 사용하는 것이 가장 적합할지 감이 잡히지 않아, 임베딩 값들을 직접 시각화해보았다. 우선 회의 녹취록 중 일부를 화자 구분(diarization) 모델에 입력하여, 화자별로 타임라인을 분리해냈다. 이후 각 타임라인에 해당하는 구간을 기준으로, 화자별 임베딩 값을 추출했다. 총 3명의 화자에 대한 임베딩을 수집한 뒤, 이를 기반으로 PCA, t-SNE을 적용하여 시각화를 진행했다. PCA (주성분 분석)는 고차원의 임베딩 공간을 최대 분산 방향으로 2차원으로 축소하여 전체적인 분포 구조를 확인할 수 있고, t-SNE은 임베딩 간 유사도를 고려하여, 로컬 클러스터링 구조를 강조하는 방식으로 2차원으로 시각화한다.
먼저 Speechbrain Embedding 시각화를 살펴보자. PCA 결과를 보면, 세 화자의 임베딩들이 대략적으로 분리되어 있으나, 전체적인 분포는 다소 흩어져 있는 모습을 확인할 수 있다. 특히 A 화자와 B 화자의 일부 임베딩들은 서로 가까운 영역에 위치하고 있어, 명확한 경계가 모호한 경우도 존재한다. t-SNE 결과에서는 PCA보다 조금 더 뚜렷한 군집 구조가 나타난다. C 화자는 비교적 잘 분리되어 있는 반면, A 화자와 B 화자 일부는 여전히 경계가 겹치는 부분이 존재한다. t-SNE는 임베딩 간 유사도를 보존하면서 저차원으로 변환하기 때문에, 이 결과는 Speechbrain 임베딩이 완전히 깨끗한 화자 구분을 제공하지는 않지만, 화자 간 대략적인 구조적 차이는 반영하고 있음을 보여준다.


다음으로 Wespeaker Embedding 시각화를 살펴보면, 이전에 사용한 Speechbrain 모델과 비교하여 훨씬 명확한 화자 분리 구조를 확인할 수 있다. PCA 결과에서는 세 화자(A, B, C)가 서로 명확하게 구분된 군집을 형성하고 있으며, 각 화자 그룹 간 간격도 크게 벌어져 있는 모습을 보인다. 특히 A 화자(주황색)와 B 화자(초록색) 간 경계가 명확하게 나뉘어져 있어, Wespeaker 임베딩이 전체적인 분산 구조를 효과적으로 반영하고 있음을 알 수 있다. t-SNE 결과에서는 로컬 구조까지 더욱 뚜렷하게 드러난다. 각 화자별 임베딩이 매우 밀집되어 있으며, 서로 다른 화자 그룹 간 거리가 확연히 떨어져 있어 클러스터 간 혼재(overlap)가 거의 발생하지 않았다. 특히 화자 C(파란색), A(주황색), B(초록색) 모두 각자의 고유한 영역을 가지며, 내부적으로도 높은 일관성을 유지하고 있다. 이러한 결과는 Wespeaker 임베딩이 화자 간 분리를 더욱 명확히 학습하고 있음을 시각적으로 뒷받침한다.

마지막으로, 화자별 대표 임베딩값을 평균 내고, 이에 대한 임베딩 모델별 히트맵을 다음과 같이 그려보았다. (청크별 히트맵은 너무 징그럽게 나온다 !). Speechbrain 모델이 확실히 유사도가 높게 잡히는 것을 볼 수 있는데, 성능이 좋다는 모델이 이러한 성능을 보이니 내가 잘못 사용한게 아닐까 하는 의구심이 들 지경이었다. 이 부분에 대해 좀 더 조사해보고, 알게 된 사항 있으면 여기에 기록하겠다.


시각화 결과를 종합적으로 고려할 때, 본 프로젝트에서는 Speaker Embedding 모델로 Wespeaker 사용하기로 결정했다.
2. 화자 구분 파이프라인에서의 활용
Pyannote에서 제공하는 Pyannote-Diar 모델을 사용하면 임베딩 모델을 직접 지정해주지 않아도 내부적인 임베딩 모델(Wespeak)을 활용해 화자별 임베딩 값을 계산하고, 화자 구분까지 전부 완료해준다. 그리고, 화자 구분 수행 시 return_embeddings 값을 True로 지정해주면 파일 내 화자별 대표 임베딩 벡터 값도 화자 구분 결과값과 함께 얻을 수 있다. 너무 편리하다.
다만, 이렇게 얻은 임베딩 값은 커스터마이징 하기 까다롭다. 화자 구분 결과 값을 보다 세밀하게 조정해야 할 필요가 있을 때, 앞서 말한 방식으로 얻은 임베딩 벡터 값에는 이러한 변경 사항이 반영되지 않게 된다. 예를 들어 다음과 같은 화자 구분 결과 파일(.rttm)이 있다고 해보자.
SPEAKER chunk_0_20250225 1 2.545 9.754 <NA> <NA> SPEAKER_00 <NA> <NA>
SPEAKER chunk_0_20250225 1 7.135 0.624 <NA> <NA> SPEAKER_01 <NA> <NA>
SPEAKER chunk_0_20250225 1 10.510 2.498 <NA> <NA> SPEAKER_02 <NA> <NA>
SPEAKER chunk_0_20250225 1 13.008 1.029 <NA> <NA> SPEAKER_00 <NA> <NA>
SPEAKER chunk_0_20250225 1 14.037 2.616 <NA> <NA> SPEAKER_02 <NA> <NA>
SPEAKER chunk_0_20250225 1 18.037 1.468 <NA> <NA> SPEAKER_02 <NA> <NA>저기서, 7.135초부터 0.624초 동안 감지된 'SPEAKER_01'의 결과 값은 높은 확률로 '잡음'이거나, '으음..' 같은 추임새일 것이다. 그래서 후처리 작업의 일환으로 저런 짧은 발화들을 사용하지 않는 값으로 필터링하게 되는데, 화자 구분 결과 값으로 얻은 SPEAKER_02의 임베딩 값에는 저 짧은 발화 구간에서의 임베딩 값 또한 이미 사용해서 계산되어 버린 상태가 되는 것이다. 뿐만 아니라, 다른 화자간 발언이 겹치는 구간에 대해서도 고려하지 않기 때문에 여러 화자의 임베딩 값이 섞여버리기도 한다.
** Pyannote 동작 과정
Step 1. 오디오 파일을 고정 길이 Window로 분할
Step 2. 각 Window별 Speaker Embedding 추출
Step 3. 추출한 임베딩 기반으로 Clustering, Classification 수행
이러한 일련의 이유로, 프로젝트에서는 Speaker Embedding 모델을 후처리 작업에서 많이 사용하게 되었으며, 해당 과정은 후속 포스트 (Post Processing)에서 보다 자세하게 다뤄 볼 예정이다.
'AI > Audio Processing' 카테고리의 다른 글
| 화자 구분 후처리, Post Processing 작업 일지 (0) | 2025.04.30 |
|---|---|
| 음성 탐지, Voice Activity Detection 작업 일지 (2) | 2025.04.16 |
| 오디오 전처리, Front-end Processing 작업 일지 (5) | 2025.04.10 |
| 화자 구분, Speaker Diarization 연구 일지 (0) | 2025.03.27 |
블로그의 정보
코딩하는 오리
Cori