오디오 전처리, Front-end Processing 작업 일지
by Cori회의록 서비스 성능 고도화 프로젝트의 일환으로, 이전 포스트에서 설명한 화자 구분 프로세스의 가장 앞단에 해당하는, 음성 파일에 대한 Front-end Processing 적용 과정을 여기에 기록한다. 가장 기본적인 주파수 범위 필터링부터, 노이즈 제거, 반향 제거들을 수행해보고, 적용 전-후 오디오 품질이 실제로 개선되었는지 시각화해본다.
0. 오디오 시각화
오디오 Front-end Processing 처리 전과 후 품질 변화를 비교하기 위해, 오디오 파일을 크게 세 가지 방식으로 시각화한다.
첫 번째는 Waveform(파형) 시각화로, 시간에 따른 오디오 신호의 진폭 변화를 보여준다. 아래 그림은 하나의 오디오 파일을 시간 축에 따라 시각화한 결과로, 사람이 말하는 구간에서는 진폭이 크고 변화가 많은 반면, 무음 구간에서는 거의 0에 가까운 값을 유지하는 것을 확인할 수 있다. 이를 통해 전체 오디오의 말하기 구간과 무음 구간을 직관적으로 파악할 수 있다. 다만, Waveform만으로는 오디오의 주파수 정보나 음성의 세부적인 특성까지 파악하기 어렵다는 한계가 있다. 예를 들어, 서로 다른 화자의 음성이나 배경 노이즈가 섞인 구간이라도, 파형상에서는 유사한 진폭 패턴을 보일 수 있어 음질이나 발화 특성의 차이를 구별하는 데는 부족하다. 또한 특정 주파수 대역에서 발생하는 노이즈나 음성 특징(예: 음색, 억양 등)은 Waveform에서는 드러나지 않기 때문에, 보다 정밀한 분석을 위해서는 스펙트로그램(Spectrogram) 등의 주파수 기반 시각화가 필요하다.

스펙토그램은 오디오 신호의 주파수 분포가 시간에 따라 어떻게 변하는지를 시각적으로 보여주는 방법이다. Waveform이 시간에 따른 진폭 변화를 나타낸다면, 스펙트로그램은 시간(Time)–주파수(Frequency)–세기(Magnitude)의 3차원 정보를 2차원 이미지로 표현한다. 가로축은 시간, 세로축은 주파수, 색상은 해당 시간–주파수 영역의 에너지 크기를 나타내며, 일반적으로 밝을수록 에너지가 크고 어두울수록 에너지가 작다. 이를 통해 사람의 음성과 환경 소음, 혹은 특정 주파수 대역의 노이즈를 시각적으로 구분할 수 있으며, 발화의 억양, 음색, 말소리의 명확성 등도 비교적 쉽게 파악할 수 있다. 따라서 오디오의 품질 분석이나 전처리 전·후의 변화 확인에 매우 유용하게 활용된다.

Mel-Spectrogram은 스펙트로그램에서 한 단계 더 나아가, 사람의 청각 특성을 반영해 주파수 축을 Mel-scale로 변환한 시각화 방식이다. 인간의 귀는 고주파보다 저주파에 더 민감하게 반응하는데, Mel-scale은 이러한 특성을 수치적으로 반영한 비선형 주파수 스케일이다. 따라서 Mel-Spectrogram은 사람이 실제로 인지하는 소리의 특징에 더 가까운 정보를 제공한다. 표현 방식은 스펙트로그램과 유사하게 시간–주파수–세기 정보를 시각화하지만, 세로축의 주파수 값이 Mel-Scale로 재배치되며, 이는 특히 음성 인식이나 음향 모델링에서 더욱 효과적인 입력값이 된다. 또한 Mel-Spectrogram은 딥러닝 기반 오디오 처리 모델에서 표준 입력으로 널리 사용되며, 오디오의 명료도나 처리 품질을 비교하는 데 있어서도 직관적인 기준이 된다.

요약하자면, Waveform은 전체적인 신호 흐름을, Spectrogram은 주파수 기반 구조를, Mel-Spectrogram은 사람의 청각에 더 가까운 표현을 제공한다. 이 세 가지 시각화를 함께 살펴보면, 오디오 전처리의 효과와 품질 개선 여부를 다각도로 분석할 수 있다. 이제부터 위 3가지 시각화 기법을 통해, Front-end Processing 적용 전과 후 오디오 차이를 비교 분석해보자.
1. 주파수 범위 필터링
ffmpeg 라이브러리를 활용해 특정 주파수 범위를 벗어나는 음성을 제거하는 필터링 기법. 단순 주파수 기준(100~3500)으로 오디오를 필터링하다 보니 잡음이 아닌 사람 목소리가 필터링되어 버리는 경우도 있고 해서, 현재는 사용하고 있지 않다. 관련 코드는 [이곳을] 클릭하면 확인할 수 있다.
def filter_audio_with_ffmpeg(self, input_file, high_cutoff=100, low_cutoff=3500, output_file=None):
"""
FFmpeg을 사용한 오디오 필터링 (고역대, 저역대).
Args:
input_file (str or BytesIO): 입력 오디오 파일 경로 또는 BytesIO 객체.
high_cutoff (int): 고역 필터 컷오프 주파수 (Hz).
low_cutoff (int): 저역 필터 컷오프 주파수 (Hz).
output_file (str, optional): 필터링된 오디오 저장 경로. 지정되지 않으면 메모리로 반환.
Returns:
io.BytesIO: 필터링된 오디오 데이터 (output_file이 None인 경우).
"""
pass앞서 설정한 주파수 필터링 값 100~3500은 다른 값들을 바꿔가며 여러 시도를 해 보았었고 적정 주파수를 찾는게 여간 힘든 일이 아니었기에 (하나의 오디오에서 최적으로 설정해도, 다른 오디오에서 최적이 아닌 경우 다수 존재) 해당 주파수를 기본값으로 두었다. 다음은 주파수 필터링 적용 전과 후를 보여주는 오디오 파형이다.



주파수 필터링을 100Hz에서 3500Hz 사이로 적용하면, 사람 목소리가 주로 사용하는 대역만 남기고 그 외의 불필요한 주파수들을 깔끔하게 제거할 수 있다. 해당 방식은 음성 인식이나 화자 분리 같은 작업 전에 간단한 전처리로 쓰기에 좋지만, 필터링 범위 안에 있는 잡음은 그대로 남아 있다. 이에 해당 방식으로 커팅을 하고, 추가적으로 Demucs 같은 딥러닝 기반의 노이즈 억제 모델을 같이 써야 훨씬 더 정교한 잡음 제거가 가능해진다.
2. 소음 제거 (Denoise audio)
노이즈 억제를 위해 LSTM 기반 노이즈 억제 모델 중 NSNet2(Microsoft) 모델과 demucs(Facebook)를 적용해보았다. 이외에도, noisereduce 라이브러리와 paddleboard(Spotify) 라이브러리를 추가로 사용해보았다. demucs의 경우, 음성을 ['vocal', 'other', 'bass', 'drum']으로 분리하는데, 이 중 vocal을 denoised된 음성 파일로 간주하고 진행했다. Demucs를 이용한 노이즈 억제 코드는 [여기를], NSNet2를 이용한 노이즈 억제 코드는 [이곳을] 클릭하면 확인할 수 있다. paddleboard와 noisereduce 라이브러리는 관련 공식문서를 참고해서 진행할 수 있다.
Noisereduce 라이브러리는 단순히 특정 주파수 대역을 자르는 것이 아니라, 배경 소음을 실제로 학습해서 제거하는 방식을 사용한다. Noisereduce 라이브러리를 사용해 잡음 제거 전 후를 시각화하면 다음 그림과 같다. 파형상으로는 여백이 생기고, 정적 구간의 잡음이 거의 사라진 것을 볼 수 있다. 스펙토그램과 Mel 스펙트로그램에서도 잡음이 확실히 줄어든 것을 보아, 노이즈 제거에 있어 성능이 준수하다고 볼 수 있다.



Paddleboard 기반 소음 제거는 단순한 threshold 기반이 아닌, 딥러닝으로 음성과 잡음을 구분 음성과 겹쳐 있는 배경 소리도 일부 제거가 가능하기에, 음성의 선명도는 유지하면서 잡음만 줄이는게 가능하다 할 수 있다. Paddleboard 라이브러리를 이용한 노이즈 억제 전과 후는 다음 그림과 같다. 특이했던건, 튀는 파형의 위치가 __|__ -> ___|_ 이렇게 바뀐게 있다는 점 .. ? 근데 이 부분은 일부 노이즈 억제 라이브러리들이 내부적으로 에너지 손실을 방지하기 위해 후처리 단계에서 볼륨을 다시 증폭하는 성향이 있어, 해당 과정에서 발생한것으로 추정된다.



NSNet2는 NSNET(Noise Suppression Network) 두 번째 버전으로, 실시간 음성 통화 품질 향상을 위해 개발된 Microsoft Research의 딥러닝 기반 노이즈 억제 모델이다. Microsoft Teams의 실시간 노이즈 억제 기능에 탑재되어 사용되고 있으며, 키보드 타자 소리, 백색 소음, 짖는 개 소리, 문 닫는 소리 등 다양한 환경 소음을 지능적으로 제거한다. 실제로 다음 그림을 보면, 말소리는 유지하면서, 음성과 겹치지 않는 잡음은 강력하게 제거하는 것을 볼 수 있다. 특히 STFT·Mel 스펙트로그램에서 노이즈가 거의 전멸한 수준으로 평탄화된 것을 볼 수 있다.
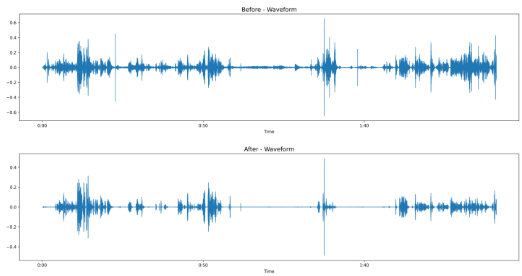


Demucs(Deep Extractor for Music Sources)는 Facebook AI Research에서 개발한 딥러닝 기반 음원 분리 모델로, 원래는 음악에서 보컬, 드럼, 베이스, 기타 등의 트랙을 분리하기 위해 만들어졌다. 하지만 사람 음성과 배경음을 효과적으로 분리하는 능력 덕분에, 음성 처리 분야에서도 음성만 추출하는 용도로 널리 사용되고 있다. Demucs를 이용한 노이즈 제거 전, 후 그림을 살펴보면 정적 구간의 배경음이 거의 0에 수렴할 정도로 줄어든 것을 볼 수 있다. 또한, 분리 전에는 전 시간 구간에 걸쳐 고주파·저주파 잡음이 얇게 퍼져 있었던 반면, 분리 후에는 오로지 음성 활동 구간에서만 스펙트럼이 존재하는 것을 볼 수 있다.
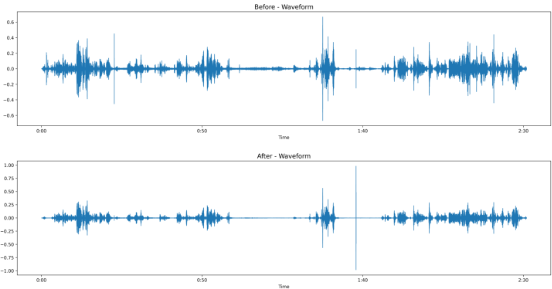


각 모델들에 대해, 4~5개 정도의 음성 파일 (타자 소리와 같은 배경음이 많이 들어간 파일, 카페 같은 주변 소리가 시끄러운 파일, 잡음이 거의 없는 음성 파일 - 원본 음성의 손실 정도 체크)들에 대해 각각의 모델들을 테스트해 보았을 때, 가장 괜찮았던 노이즈 제거 모델은 NSNet2로, 각 모델별 특징을 정리해보면 다음과 같다.
| noisereduce | paddleboard | NSNet2 | demucs | |
| 방식 | 통계적 노이즈 추정 + 감산 | 딥러닝 기반 denoise | 실시간 denoise용 DNN | 음악 분리용 모델 활용 |
| 주요 특징 | 정적 배경음 제거에 강함 | Spotify에서 개발 | Teams 등에 실제 사용 | 말소리만 추출 |
| 노이즈 억제 효과 | 커피 마시는 소리, 키보드 타건음 등 완벽 제거 x | 문 닫히는 소리, 키보드 타건음 등 완벽 제거 x | 잡음 제거 거의 완벽에 가까움 | 음성 분리정도 뛰어남 |
| 음성 손실 정도 | - | - | - | - |
위 모듈들에 대한 개인적인 점수를 매기면, NSNet2 >>> demucs >= paddleboard >> noisereduce 인 것 같다. demucs, paddleboard, noisereduce 모두 원본 파일보다 우수한 성능을 보이지만, NSNet2 모듈을 사용해보니 다른 모델들의 아쉬운점들이 부각되었달까 .. 다만, 음성 파일의 길이가 커질수록 CPU 과부하가 걸려서 프로그램이 죽을 수 있으니 (GPU 사용하도록 수정해보았으나 GRU 관련 오류로 인해 실패) 오디오 파일을 청크로 잘라서 노이즈 억제하는게 좋다.
실제로 잡음 제거가 화자 구분에 영향을 미칠까 ? 를 테스트해보았다. 테스트에 사용한 음성 파일은 실제 회의에서 녹음한 파일 중 일부를 커트해서 진행했으며, 해당 파일에는 3명의 화자가 등장한다. 먼저 원본 파일에 대한 화자 구분을 돌려본 결과를 보여주면 다음과 같다.

화자가 4명으로 나오는 것을 확인할 수 있는데, 실제로 음성 파일을 들어보니 SPEAKER_01, SPEAKER_03이 주요 화자였고, SPEAKER_00은 제3자와 SPEAKER_01이 섞여 있었으며, SPEAKER_02는 SPEAKER_01을 SPEAKER_02로 잘못 분류한 화자였다.
noisereduce를 사용해 노이즈 억제를 하고, 이에 대한 화자 구분을 진행해보았을 때 다음과 같은 결과가 나왔다. 화자가 3명이 아닌 2명으로 구분되었고, 여러모로 원본 파일보다 성능이 저하된 듯한(그것도 좀 많이 .. ?) 결과가 나왔다. 그래서 해당 라이브러리는 사용 고려 대상에서 제외했다.

paddleboard를 적용해 노이즈 제거 한 음성에 대해 화자 구분을 적용해본 결과는 다음과 같다. noisereduce 라이브러리를 사용했을 때 보다 발화 정도를 더 잘 인식한 것을 확인할 수 있었다. 다만, 해당 라이브러리는 50초 지점 부근에서 SPEAKER_00이 발화한 내용을 못 잡는 등의 문제가 있는 것이 확인되었다.

Demucs를 적용해 노이즈 제거 한 음성에 대한 화자 구분 결과는 다음과 같다. 화자가 3명이 아닌 4명으로 구분되었고, 원본 파일과 비슷한 지점(89~91s)에서 음성이 인식되어 들어보니, SPEAKER_01의 웃음소리와 중얼거리는 소리가 새로운 화자로 인식된 것이었다. 아무래도 노이즈 억제보다는 음성 분리이다 보니, 화자 구분쪽에서는 성능이 원본이랑 비슷하게 나온 것 아닐까 싶었고 마찬가지로 고려 대상에서 제외했다.

마지막으로, 노이즈 억제 효과가 가장 우수하다고 느껴졌던 NSNet2에 대한 화자 구분 결과값을 보여주면 다음과 같다. 화자가 3명 등장하는 파일은 맞지만, 남자 2명이 말할 때 화자 구분을 잘 하지 못하는 현상은 여전한 문제로 남아있긴 해서, 이 부분은 이후 화자분리 고도화에서 좀 더 살펴볼 생각이다.

3. 반향 제거 (Deverve audio)
회의실처럼 벽, 천장, 바닥으로 둘러싸인 공간에서는 말소리가 벽에 반사되며 잔향(reverberation)이 발생한다. 이런 반향은 음성이 뿌옇게 들리게 만들고, 음성 인식(STT)이나 화자 분리(diarization)와 같은 모델의 성능을 떨어뜨릴 수 있다. 본 포스팅에서는 노이즈 억제 후, 멀티채널 오디오의 잔향 성분을 예측하고 잔향 성분을 제거하는 WPE(WWeighted Prediction Error) 알고리즘을 구현한 nara-wpe 라이브러리를 적용했다.
일반적으로 WPE는 멀티채널 오디오에서 더 높은 성능을 보이지만, nara-wpe 라이브러리는 단일 채널 오디오에도 적용할 수 있어, 회의 녹음처럼 모노 마이크로 녹음된 환경에서도 실질적인 반향 제거 효과를 얻을 수 있다. 앞서 가장 좋은 성능을 보였던 NSNet2를 이용한 노이즈 제거 처리 후 반향 제거까지 진행해서, 화자 구분 모델을 돌려보았다.

화자가 1명 날아가긴 했으나, 잘못 인식하던 화자 정보들을 잘 배치하는 것을 확인할 수 있었다.
Front-end Processing 과정을 통해 오디오 품질 개선하는 작업에 대해 다뤄보았다. 일단은 원본 오디오에 대해 NSNet2 + 반향 제거를 적용해 화자 구분 + STT를 하려하며, 추가적인 업데이트 사항이 있으면 여기에 기록하겠다.
** 2025.04.10
실제로 deverve 까지 적용한 음성 파일 전체에 대해 화자 구분을 적용해보았는데, 뭔가 성능이 엄청 개선되었다기 보다 오히려 저하된듯한 느낌을 받았다. 앞서 설명했던 내용들은 단일 케이스이고, 3분짜리 파일에 대해 적용해본거라 괜찮게 느껴진건지도 .. ? 알아보니 NSNet + Deverve까지 적용하면 원본 파일의 고유 화자 음성 정보가 변형되기 때문에, 화자별 고유 임베딩 값 손실이 발생해 화자 구분 성능이 저하될 수도 있다고 한다 .. 그래서 Front-end Processing 적용은 좀 더 고민해볼 예정이다.
'AI > Audio Processing' 카테고리의 다른 글
| 화자 구분 후처리, Post Processing 작업 일지 (0) | 2025.04.30 |
|---|---|
| 화자 임베딩, Speaker Embedding 작업 일지 (1) | 2025.04.22 |
| 음성 탐지, Voice Activity Detection 작업 일지 (2) | 2025.04.16 |
| 화자 구분, Speaker Diarization 연구 일지 (0) | 2025.03.27 |
블로그의 정보
코딩하는 오리
Cori